

中国成立数据科学部门
2018 年 2 月,Airbnb 中国(爱彼迎)宣布成立数据科学部门,由 17 年底加入的朱涛负责。朱涛此前曾在沃尔玛担任全球电子商务增长部门数据科学总监,拥有多项机器学习与算法方面的专利。
朱涛告诉 AI 前线,Airbnb 数据科学部门负责利用分析、算法和推理,为战略和业务部门提供决策帮助,为用户提供智能解决方案。Airbnb 作为一家数据驱动的公司,数据科学部门在该公司扮演重要的角色。在每一个 Airbnb 全球的四个事业群下,都有一个数据科学部门直接汇报给事业群的负责人,并参与高层决策。
此前,Airbnb 已经吸引了不少中国用户的青睐,中国已成为 Airbnb 营收的重要贡献市场,以下是关于 Airbnb 的一组最新数据:
国外游客在成都、重庆、武汉扥国内内陆城市的房源预订量增长超过 100%;
非一线城市房源预定量同比增长 170%;
爱彼迎境内游市场已超过总业务量的 50%。
可以看到,airbnb 这一次是真正准备深入中国腹地抢夺最本土化的那片市场了。
Airbnb 在此时成立中国数据科学部,以及 2017 年底,Airbnb 中国区主席,同时也是该公司联合创始人兼首席战略官 Nathan Blecharczyk 通过邮件表示,“Airbnb 非常重视中国市场,并认为中国在 2020 年有望成为 Airbnb 最大的客源国”,都表明了 Airbnb 对中国市场的重视和关注。
备受期望的 Airbnb 中国
2017 年底,Airbnb 中国区主席,同时也是该公司联合创始人兼首席战略官Nathan Blecharczyk通过邮件表示,Airbnb 非常重视中国市场,并认为中国在 2020 年有望成为 Airbnb 最大的客源国。
不过,民宿短租行业的市场巨大,Airbnb 中国也面临激烈的竞争局面,不但涌现了一大批创业公司,酒旅巨头也瞄准了这一市场,纷纷布局。要想赢得市场竞争,达成目标,技术也是 Airbnb 傲视其它公司的一个重要武器,中国区数据科学部门正是在这样的情况下应运而生。

(Airbnb 中国北京办公室)
据朱涛介绍,Airbnb 中国数据科学团队分布在旧金山和北京两个办公室,保持与总部密切联系,主要负责 Airbnb 中国本土以及境外游业务的数据科学支持。
Airbnb 中国数据科学部的不同之处,在于其身处中国,生长在这个市场巨大但情况复杂的土地上,该团队的工作需要应对中国用户与其他市场迥异的使用习惯,需要接受很多对其他市场用户有效果的功能,在中国可能会出现截然不同效果的事实,并提出适应中国国情的解决方案。因此,数据科学团队在处理中国业务或数据模型时会区别于其他市场,Airbnb 的技术手段会基于总部,但在某些领域会更加深入。另外,中国的互联网环境和其他市场是完全不同的,Airbnb 也需要针对中国的互联网环境开发相应的技术。
Airbnb 与数据科学
Airbnb 是一家数据驱动型公司,数据之于 Airbnb 的重要性不言而喻。2008 年成立之初到现在,Airbnb 十分重视数据的作用,将数据视为最重要的声音之一,数据科学团队规模迅速成长。
Airbnb 之所以注重数据科学的原因,在朱涛的理解中,是因为数据科学不同于传统的 BA(商业分析方法)、BI(商业智能),它更加注重方法,知识积累和科学依据,而传统的 BA 和 BI 则更加偏重于经验。
例如,Airbnb 内部是有一个类似于文献系统的发布系统 Knowledge Repo,Airbnb 的数据科学家通过实验或者科学推理得出的一些结论,以及最新开发出来的新模型都会被总结并发布在此系统中。公司内部任何一个人都可以检索到过去的研究,如果大家遇到类似的问题都可以在这里面找到之前的研究成果,这样,即便是没有任何经验的数据科学家,也可以避免从 0 开始摸索,而且已有的结论可以作为基础支撑进行更进一步的研究。
最近几年,因为计算能力以及训练方法的进度,深度学习在语言、视觉以及最优决策领域取得了显著的进步,成为一个独立的流行领域。机器学习本身则是数据科学中对于预测问题常用一大类算法的集合。
很多人只对 ML/DeepLearning 感兴趣,其实这些领域只是数据科学里面非常小但是非常深入的一个垂直领域,数据科学还有非常多很重要的学科,深度学习是机器学习的一种模型。
Airbnb 的数据科学部门集合了包括数据分析、机器学习、深度学习、统计推断、经济学等多个领域,主要从业务问题入手,寻找最合适的方法来解决问题。机器学习在 Airbnb 也只是算法数据科学方向的一个领域,算法数据科学还包括像最优决策这样的算法问题。像前面提到的实时搜索排序是机器学习算法问题,而对于一个用户支持电话应该分配给哪个工作人员接听处理,则是一个典型的最优决策算法问题。
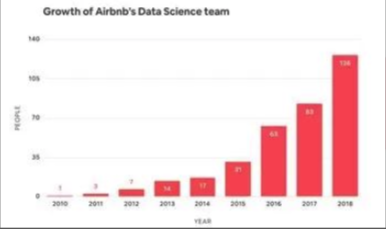
从 2010 年数据科学团队人数寥寥无几,到 2018 年将近 140 人,Airbnb 的数据科学团队成长速度很快。
获奖、开源,Airbnb 数据科学部都做了些什么?
在逐渐壮大过程中,Airbnb 数据科学部做出了很多亮眼的成绩,最近的一次是在 KDD2018 ADS track Best Paper Award 中获奖,获奖论文包括:
Real-time Personalization using Embeddings for Search Ranking at Airbnb( http://www.kdd.org/kdd2018/accepted-papers/view/real-time-personalization-using-embeddings-for-search-ranking-at-Airbnb )
Customized Regression Model for Airbnb Dynamic Pricing( http://www.kdd.org/kdd2018/accepted-papers/view/customized-regression-model-for-Airbnb-dynamic-pricing )
Winner’s Curse: Bias Estimation for Total Effects of Features in Online Controlled Experiments( http://www.kdd.org/kdd2018/accepted-papers/view/winners-curse-bias-estimation-for-total-effects-of-features-in-online-contr )。
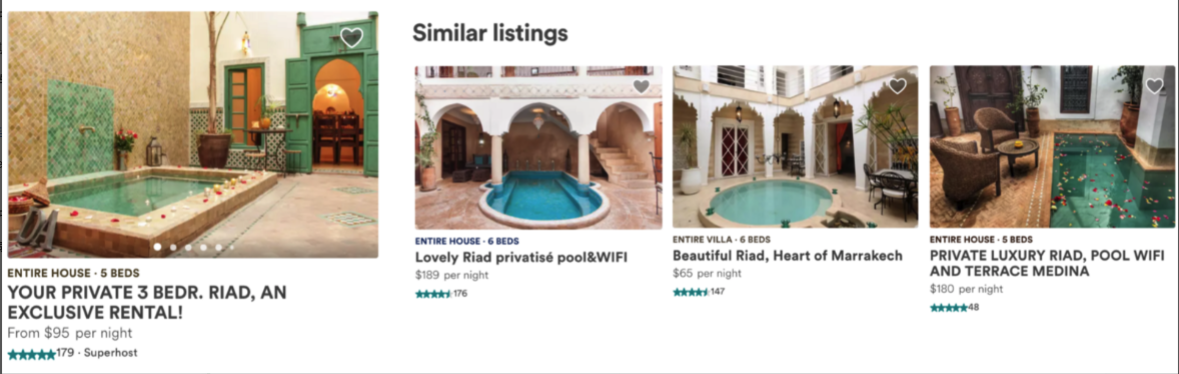
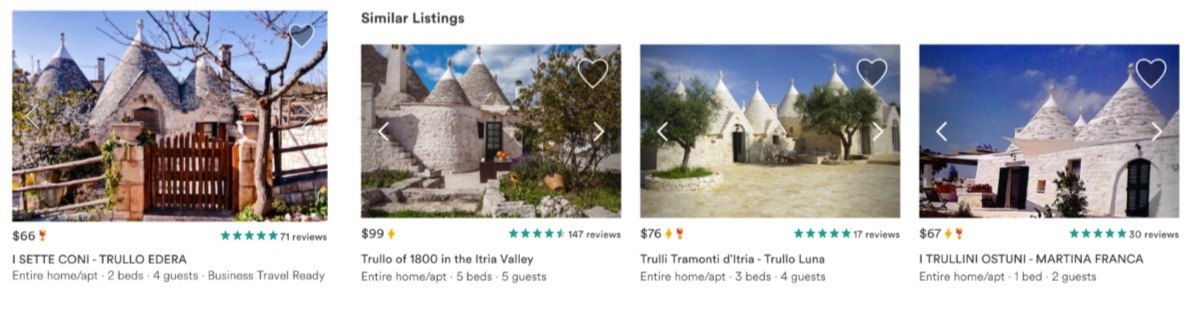
其中,获得最佳论文的 Real-time Personalization using Embeddings for Search Ranking at Airbnb 中的算法原理,是首先通过大量用户历史行为训练出房源高维的 embedding 模型,再加上房源其他的基础特征作为房源的综合特征集。当一个新用户来到搜索页面后,随着他(她)点击不同的房源,Airbnb 通过分布式系统实时对用户接下来看到的房源进行基于 learn-to-rank 的算法重新排序,以优化用户看到房源的相关性。经过 AB test 发现,通过这种新的 embedding 模型所找到的房源的相关性要明显高于其他基于相似性的模型(基于 embedding 模型的相关房源推荐实例如下图)。
在分析和推理方面,例如 Airbnb 需要了解一个观察到的结果(比如最近交易量增长了,或者出现了更多的短途旅行)主要是由什么原因导致的,就可以使用计量经济学、统计学、社会科学找到这个问题的答案,其中最为常见的方法可能就是对比试验。
在互联网领域,页面 SEO 的方法一般都是基于经验的迭代出来,很难通过实验的方法测量出来。在最新发布的博客中,Airbnb 介绍了常用到的一个较复杂的实验方法——Difference-in-difference (DID, or DD) 方法。通过这个方法,Airbnb 能够准确地知道其对一个页面改版以后会对 SEO 引流产生怎样的影响,以便加速迭代过程,少走弯路。
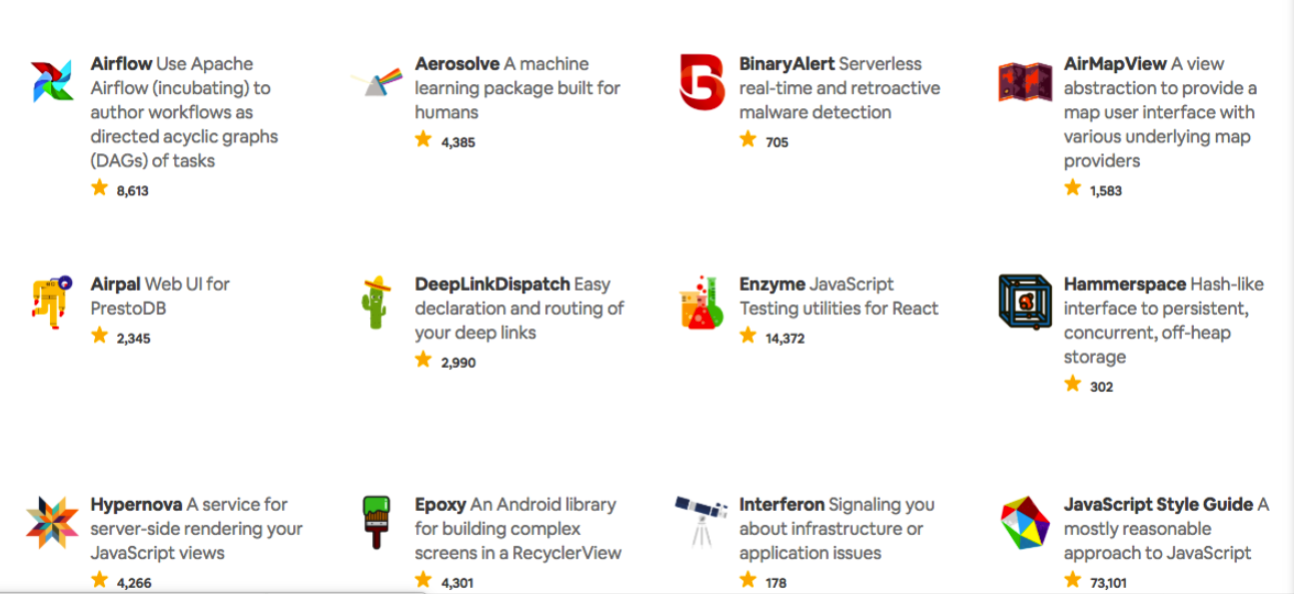
此外,Airbnb 还是一家具有分享精神的公司,乐于分享技术。在其技术博客上开源了 26 个项目,在数据科学领域的开源项目包括:
Airflow:一个程序化的签名、安排、监控数据管道的平台,Apache 基金会孵化项目。
Aerosolve:人类友好的机器学习库,让用户(房东)也能看懂模型给出的结果。
Airpal:PrestoDB 的 Web UI 界面。
knowledge repo:给数据科学家和其它专家的下一代知识分享平台。
Superset:一个现代的、企业级 BI Web 应用,Apache 基金会孵化项目。
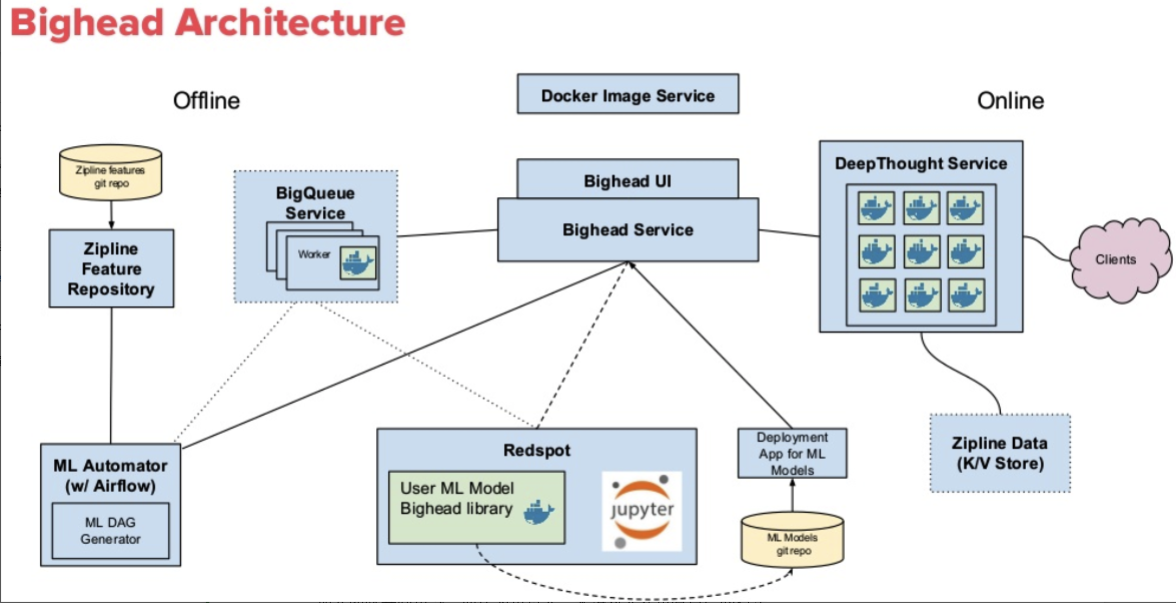
Bighead:Airbnb 的线上机器学习系统
关于生产环境中机器学习系统,Airbnb 有多个架构应用在不同的生产环境下。下图所示的‘大头架构’就是其生产中用到的一个解决方案。这个架构主要分线下和线上两部分组成,主要组件包括:
- 负责特征提取的 Zipline(Zipline 内的特征也能被其他模型利用)
- 模型训练以及预测的 ML Automator(ML Automator 也包括 scheduler 在内,能识别并按步奏来执行相互关联的模型训练任务)
- 模型交互界面
- 几句 jupyter 的模型开发工具 -Redspot
- 线上的 DeepThought 服务。DeepThought 能够 cache 住训练好的模型实时进行预测
Airbnb 中国数据科学的人才观
Airbnb 中国正在快速发展当中,刚成立的数据科学部门也求贤若渴,希望招募到实力强劲的人才加入团队共同奋斗。而作为负责人,朱涛对人才也有自己的看法。
随着智能时代的到来,数据成为所有企业和组织抢占竞争优势的基础,所谓的数据者得天下。在此背景下,人才的争夺也近白热化,数据科学家成为一个炙手可热、备受追捧的职业。
然而,虽然数据科学家现在是备受追捧的热门高薪职业,但同时也是全球离职率最高的职业之一,这一现象不可忽略。
数据显示,在收入 Top 5 的公司中的 Pinterest,数据科学家平均年薪为 $212K ,其中包括 $145K 的底薪、$12K 的年终奖和每年 $55K 美元的股权。
在高薪背后,仍有很多数据科学家每周花费 2 小时寻找新的工作机会。据一份基于 Stack Overflow 对于 64000 位开发人员的调查得出结论,在开发者中表示自己正在找一份新工作的比例在机器学习专家中名列前茅,为 14.3%,而数据科学家紧随其后,为 13.2%。据分析,数据科学家离职率高的原因包括期望值与现实不符等。
对此,朱涛认为,数据科学家现在是一个非常热门的高薪职业,这类职业的热门程度从一定程度上反映了它对数字化商业的贡献以及重要性。一个好的数据科学家确实可以为企业省去不少试错成本,快速提高产品体验。但是过于频繁的换工作也会限制一个数据科学家深入思考和理解一个领域的机会。另外,数据科学在中国是一个新兴行业,行业内还没有形成有效的相对标准化的人才评估考核体系,这个问题也需要对数据科学感兴趣的人来一起交流并共同建立这个新兴行业。
朱涛说道:“成为一名优秀的数据科学家,一是需要有扎实的统计、数学建模、经济学,以及计算科学基础知识,并善于逻辑思维与推理,二是善于从解决实际问题中积累数据科学的方法和经验。一般具备以上背景的人都很适合做数据科学。”
PS:10 月 27 号下午,Airbnb 中国的北京办公室将会举办一场数据科学的技术分享会,届时会有 Airbnb 的数据科学家深入介绍 Airbnb 是如何利用机器学习技术做图像识别以及文本理解还有一些分析和推理方面的技术。点击 http://form.izhiqun.com/f/60JGMW 了解详情。
采访嘉宾
朱涛,Airbnb 中国数据科学部负责人,曾任沃尔玛 labs 担任增长部门数据科学总监,本科毕业于北京航空航天大学,并获得美国伊利诺伊大学香槟分校运筹学博士学位。朱涛拥有 5 部出版作品,4 项搜索、消费者生命周期、营销算法、个性化推荐系统和方法相关专利。
PSS: Airbnb 中国数据团队也在快速扩张中,数据科学分析,推理和算法方向都在招人。有兴趣的同学请将简历发至techrecruitingcn@airbnb.com 邮箱中。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论 1 条评论