来自荷兰国际集团(ING)的 Janna Brummel 和 Robin van Zijll 在伦敦 Velocity 大会上分享了他们是如何通过 SRE 来提升网络银行可用性的。他们组建了一支 SRE 团队,为产品团队(在内部被称为 BizDevOps)提供有关可靠性的工具、咨询和培训。
ING 的 2017 年中指标表明,他们的个人网上银行系统的可用性降到了 96.84%,而其他系统(如个人移动银行)的可用性都在 99.99% 左右。造成这种局面的因素包括:产品团队缺乏监控;集中式的告警系统只在发生重大事件(比如系统崩溃)时才会发出告警,诊断问题需要很长时间(一个主要事故平均需要 69 分钟);缺少事后的事故评审和总结;缺少组件层面的可用性洞见(服务层面的反馈对产品团队来说不够直接)。
集中式的 SRE 团队只提供咨询(他们本身不会参与轮班待命),同时他们作为一个平台团队,也为产品团队提供工具和内部服务,帮助他们提升系统的可靠性。他们根据谷歌SRE 手册中定义的服务可靠性层级来计划和安排产品团队的任务优先级。
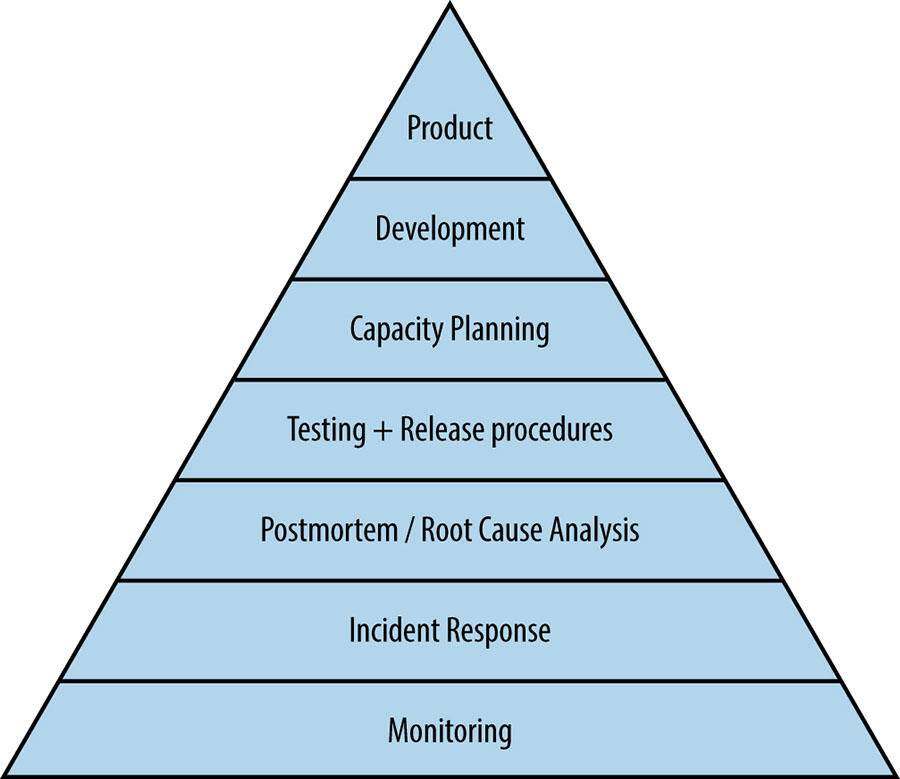
目前,SRE 团队主要覆盖金字塔的底下三层。在监控和事故响应方面,他们基于 Prometheus 、 Grafana 和 Mattermost ( ChatOps )构建了一些工具。他们帮助产品团队进行事故的事后诊断,并提供建议用于识别和修复可靠性问题。Brummel 和 van Zijll 分享了他们是如何花时间和精力扭转之前那种糟糕的局面的。他们建议在增加事故评审频率之前先要多花一些时间搞清楚状况,否则可能会事与愿违。
这些变更是以逐步按需的方式推出的,而不是采取“大爆炸”式的方式进行,让产品团队来决定是否采用他们提供的工具以及是否实践他们的建议。SRE 团队也在从由几个工程师组成的小团队发展成更大的社区(跨国的 SRE 团队,目前有三个 SRE 团队,分别在荷兰、西班牙和澳大利亚)。他们通过演示和内部讨论来发展 SRE 社区。
Brummel 和 van Zijll 关于 SRE 之旅的要点包括:在进行 SRE 招聘时更注重 SRE 思维;为避免出现优先级冲突,SRE 团队需要一个产品负责人;做好花大量时间向产品团队解释和推广 SRE 的准备;工具需要提供商用级别的可用性,而且要切实解决用户的痛点;考虑工具的可扩展性和所有权问题。
查看英文原文: How ING Bank Does SRE




