
Matt Bostock 在 SRECON 2017 欧洲大会的演讲中,介绍了如何使用Prometheus 实现对 CloudFlare 分布于全球的架构和网络的监控。Prometheus 是一种基于度量进行监控的工具,CloudFlare 是一家CDN、DNS 和DDoS 防御(Mitigation)服务提供商。
基于度量的开源监控项目 Prometheus 最早推出于 2012 年,它是 CNCF (原生云计算基金会,Cloud Native Computing Foundation)的成员。Prometheus 的动态配置和查询语言 PromQL 支持用户编写对告警的复杂查询。CloudFlare 提供 CDN(内容分发网络,Content Delivery Network)、分布式 DNS 和 DDoS 防御服务,这意味着其架构已扩展到全球范围。监控这样的架构及网络无疑是一件复杂的工作。在演讲中,Bostock 介绍了 Prometheus 在其中发挥的作用。在 CloudFlare,前期部署的 Nagios 的职能已有 87% 被 Prometheus 所替代。
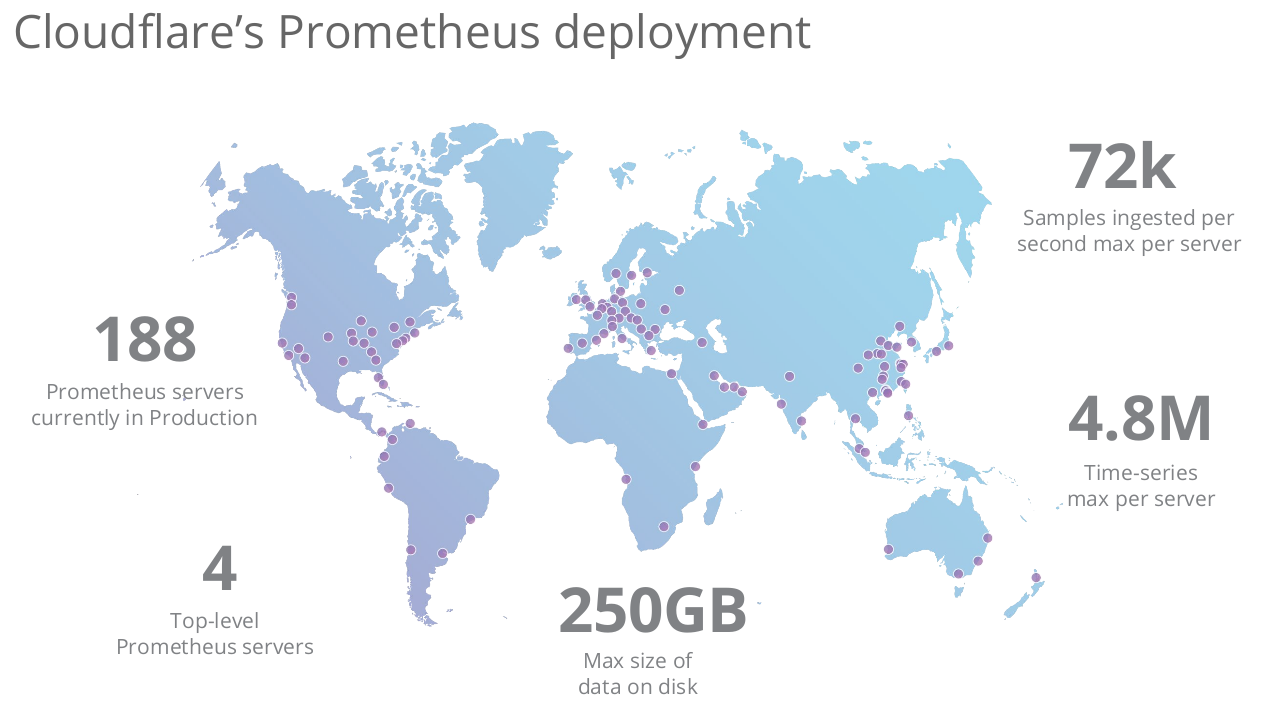
CloudFlare 提供类似于 Anycast 所提供的 CDN 服务。 Anycast DNS 使得 DNS 查询可以被最接近用户的服务器所处理, Anycast HTTP 使得内容可以从距离用户最近的服务提供。作为原始 Web 站点和用户之间的中介,CloudFlare 还检查访问者的流量中是否存在有威胁的模式。它提供了跨 150 个国家的 116 个数据中心,每秒处理 500 万次 HTTP 请求,120 万次 DNS 请求,占全球因特网请求的 10%。每个入网点(PoP,Point-Of-Presence)提供 HTTP、DNS、DDoS 防御和键值存储服务。截至演讲时,有 188 台运行在生产环境中的 Prometheus 服务器需要监控。
Prometheus 是基于度量的,也就是说它采集时序度量,并基于度量构建其余的特性。它工作于 Pull 模式下,每台监控服务器运行一个称作“exporter”的进程,通过 HTTP 发布所采集的度量。CloudFlare 为每个服务域部署了一个 exporter,使用它们采集系统(例如 CPU、内存、TCP、磁盘等)、网络(例如 HTTP、Ping 等)、本地匹配(错误信息)和容器 / 命名空间的度量。其中,exporter 使用了 Google 的开源项目 cadvisor 采集容器 / 命名空间的度量。Prometheus 并不会永久地保存所有数据,因为它更侧重于“此时此地”(here-and-now)的监控情况。数据不做下采样,并在CloudFlare 配置中保存15 天。
在CloudFlare 的核心数据中心,服务包括日志访问、分析业务,以及使用Marathon、Mesos、Chronos、Docker、Sentry、Ceph(用于存储)、Kafka、Spark、Elasticsearch 和Kibana 等技术栈构建的API。Prometheus 在每个PoP 通过exporter 查询服务器和服务获取度量。每个PoP 的高可用性是由使用多个Prometheus 服务提供的。
Prometheus 的报警管理称为“Alertmanager”。CloudFlare 的部署中包括一个 Alermanager,由每个 Prometheus 服务器推送事件,并考虑了配置的高可用性。报警基于历史数据做测试,确保服务的正确执行的。 Bosun 等新兴监控工具也包括类似的特性。为提供更好的报警服务,其它的一些特性还包括了描述性的名称、简单易用性和一些可使接收者立刻采取行动的信息。
CloudFlare 团队使用 jiralerts 实现 JIRA 工单系统与 Alertmanager 的集成。JIRA 可以用户定制工作流,使得报警监控中可以包括一些监控工作流特定的用户定制状态。另一个称为 alertmanagere2s 的工具接收报警,并将报警信息集成到 Elasticsearch 索引中,用于进一步的检索和分析。CloudFlare 已为 Alertmanger 构建了自己的仪表盘,称为“ unsee ”。
那么 Prometheus 是如何监控自身情况的?这有两种实现方法。一种是混合方法,即在同一数据中心中,由一个 Prometheus 去监控另一个 Prometheus。另一种方法是自顶向下的方法,由顶层 Prometheus 服务器监控位于数据中心层面的 Prometheus 服务器。
CloudFlare SRE 团队的经验是,尽早对环境和集群等的标签和组身份做标准化;其它一些经验是关于如何创建可视化,以及从同行和利益相关者生成买入。经验指出,团队的尽早参与将有助于服务与监控系统的更快整合。而报警本身则需要多次迭代进行调整和改进,这是一个开展中的过程。
查看英文原文: Monitoring Cloudflare’s Global Network Using Prometheus

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论