Uber 在 GitHub 正式开源了分布式跟踪系统Jaeger ,其灵感来源于 Dapper 和 OpenZipkin ,从 2016 年开始,该系统已经在 Uber 内部得到了广泛的应用,它可以用于微服务架构应用的监控,特性包括分布式上下文传播(Distributed context propagation)、分布式事务监控、根原因分析、服务依赖分析以及性能 / 延迟优化。该项目已经被云原生计算基金会(Cloud Native Computing Foundation,CNCF)接纳为第12 个项目。
Uber 分布式跟踪技术的演化
Uber 的分布式跟踪系统是随着业务的演化而不断发展的,在由单体架构迁移至微服务时,传统的监视工具,例如度量值和分布式日志依然能够发挥作用,但这类工具往往无法提供跨越不同服务的可见性。因此,就有必要引入分布式跟踪的工具。
最初,Uber 所使用的跟踪工具叫做 Merckx。Merckx 架构使用了拉取模式,可从 Kafka 的指令数据中拉取数据流,其不足之处在于主要面向单体式 API 的时代,缺乏分布式上下文传播的概念。随后,Uber 开发了 TChannel ,这是一种适用于 RPC 的网络多路复用和框架协议。很多新构建的服务都使用了 TChannel,但是承担核心业务的大部分服务都没有使用 Tchannel。这些服务主要是通过四大编程语言(Node.js、Python、Go 和 Java)实现的,在进程间通信方面使用了多种不同的框架。这种异构的技术环境使得 Uber 在分布式追踪系统的构建方面会面临比谷歌和 Twitter 更严峻的挑战。
因此,Uber 专门组建了分布式跟踪团队,团队目标就是将现有的 Tchannel 原型系统转换为一种可以全局运用的生产系统,让分布式追踪功能可以适用并适应 Uber 的微服务。该团队集思广益,创建了 Jaeger 项目。
关于 Uber 分布式跟踪技术的演进过程,在 InfoQ 之前的文章中曾经有过相关报道。
Jaeger 项目简介
术语
Jaeger 兼容 OpenTracing 的数据模型和 instrumentation 库,能够为每个服务 / 端点使用一致的采样方式。在 Jaeger 中,使用了该规范所定义的术语。
- Span:代表了系统中的一个逻辑工作单元,它具有操作名、操作开始时间以及持续时长。Span 可能会有嵌套或排序,从而对因果关系建模。一个 RPC 调用的 Span 如下图所示。
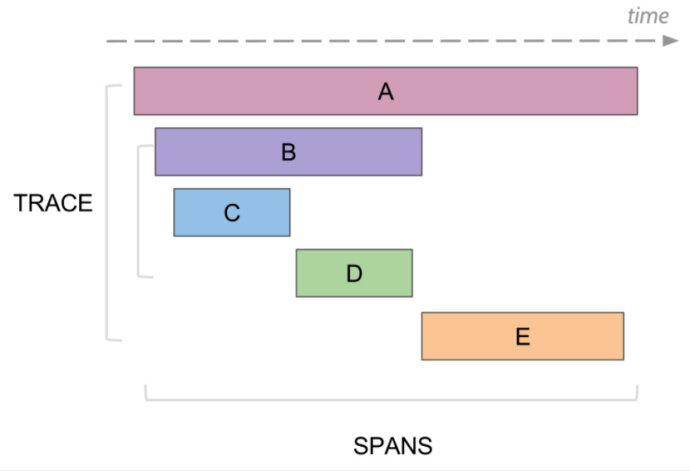
- Trace:代表了系统中的一个数据 / 执行路径,可以理解成 Span 的有向无环图。
组件
Jaeger 的各组件关系如下图所示:
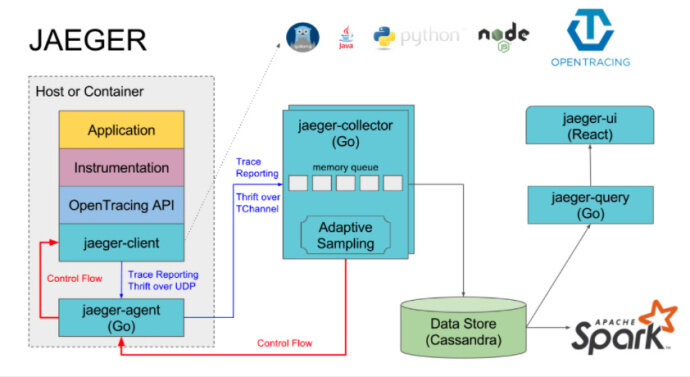
Jaeger 客户端库
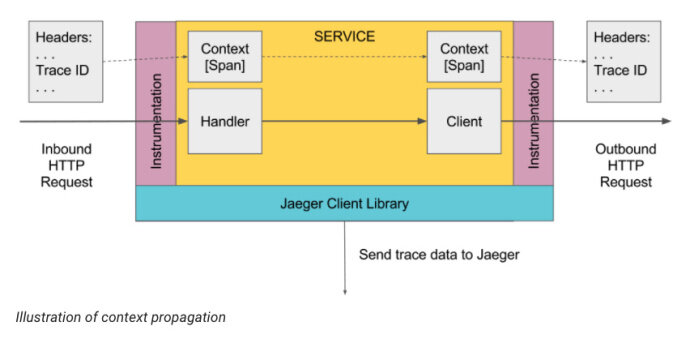
Jaeger 客户端库是 OpenTracing API 的特定语言实现。它们可以对要进行分布式跟踪的应用进行 instrument 操作,这些应用可以手动实现,也可以使用各种已有的开源的框架,比如 Flask、Dropwizard、gRPC 等。
经过 instrument 操作的服务在接收到新请求的时候,就会创建 Span 并关联上下文信息(trace id、span id 和 baggage)。只有 id 和 baggage 会随请求进行传播,而组成 Span 的其他信息,比如操作名称、日志等,并不会随之传播。采样得到的 Span 会在后台异步传递到进程外边,发送到 Jaeger Agent 上。
需要注意的是,所有的 Trace 都会生成,但是只有其中的一小部分会被采样。默认情况下,Jaeger 会采样 0.1% 的 Trace。
Agent
Agent 是一个网络守护进程,监听通过 UDP 发送过来的 Span,它会将其批量发送给 collector。按照设计,Agent 要被部署到所有主机上,作为基础设施。Agent 将 collector 和客户端之间的路由与发现机制抽象了出来。
Collector
Collector 从 Jaeger Agent 接收 Trace,并通过一个处理管道对其进行处理。目前的管道会校验 Trace、建立索引、执行转换并最终进行存储。存储是一个可插入的组件,现在支持 Cassandra。
Query
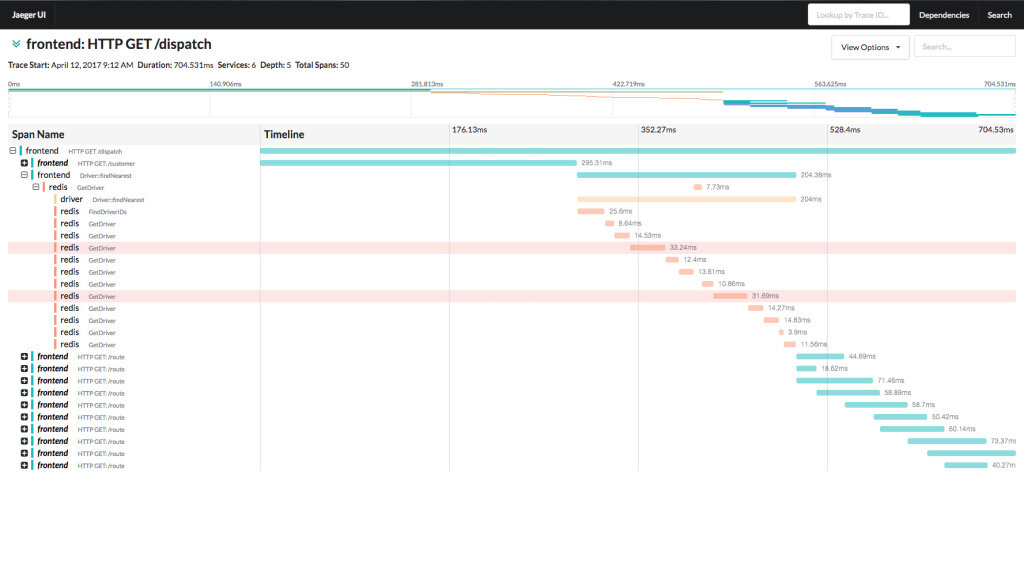
Query 服务会从存储中检索 Trace 并通过 UI 界面进行展现,该 UI 界面通过 React 技术实现,其页面 UI 如下图所示,展现了一条 Trace 的详细信息。
按照其官网的介绍,未来计划加入的功能包括自适应采样(Adaptive Sampling)、提供更多种语言的客户端库、延迟矩阵图、动态配置、基于Apache Flink 构建数据管道,以支持Trace 聚集和数据挖掘,除此之外,Jaeger 0.70 版本已支持服务到服务的依赖图,未来还会支持基于路径的依赖图,能够展现出某项服务的所有上下流依赖,而不仅仅是临近的服务。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




