从 2006 年开源 Hadoop 开始,Yahoo(也就是现在的 Oath)为广大开发者社区的大数据基础设施做出了不可磨灭的贡献。现在,我们又卖出了坚实的一步,Yahoo 的大数据处理和服务引擎 Vespa 正式在 GitHub 上开源了( https://github.com/vespa-engine )。
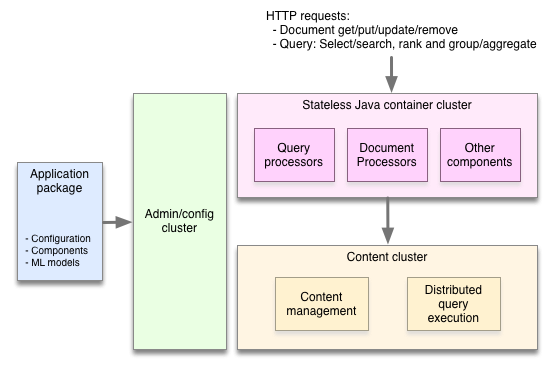
越来越多的应用程序需要处理大量的数据,尽管开发者可以使用 Hadoop 来存储和批处理数据,也可以使用 Storm 来处理流式数据,但这些技术无法直接服务于最终用户。提供大规模服务是一项巨大的挑战,当用户需要等待基于大量数据集的计算结果时,比如特征搜索、推荐系统、定制化,这种挑战就会变得尤为明显。
有了 Vespa,开发者可以轻松地构建基于大数据集实时计算结果的应用,而到目前为止,只有少数几个大公司具备这样的能力。
提供服务不是简单地根据 ID 查询项目或应用模型计算出几个数字,很多提供服务的应用需要基于大数据集运行计算,比如搜索和推荐。为了给用户返回精确的搜索结果或推荐清单,应用程序需要找出所有符合查询条件的项目,根据相关度或推荐模型决定每一个项目的匹配程度,移除重复项目,增加浏览辅助项,最后把结果返回给用户。因为这些计算依赖用户的具体请求,所以无法预先计算。应用程序必须实时地处理用户请求,而且要快,因为用户在等待结果。在大数据集上快速执行上述操作需要很多基础设施的支持——分布式算法、数据分布和管理、高效的数据结构和内存管理等等。而这些正是 Vespa 要为开发者提供的——一个一站式的引擎,简洁易用。
我们已经在 Oath 的多个产品上使用了 Vespa,包括 Yahoo.com、Yahoo News、Yahoo Sports、Yahoo Finance、Yahoo Gemini、Flickr 等。我们使用 Vespa 来处理每日数十亿个用户请求,为用户返回基于数十亿文档得出的搜索结果和推荐内容,并提供定制化内容和广告。事实上,Vespa 每秒可以处理 90,000 次内容和广告请求,延迟通常只有几十毫秒。在 Flickr 上,Vespa 每秒可以处理数百个基于数百亿张图片的关键字和图像搜索。另外,Vespa 在 Yahoo Gemini 上每天处理 30 亿个请求,高峰时段每秒钟 140,000 个请求,直接给公司带来可观的收益。
我们基于 Vespa 构建的应用具备如下特性:
-
使用 SQL 风格的查询和文本搜索来过滤内容
-
基于匹配项生成数据驱动的页面
-
根据人工或机器学习相关度模型对匹配进行排名
-
毫秒级的处理响应时间
-
实时写入数据,每个节点每秒钟写入数千次
-
在运行服务的同时进行伸缩和重配置
为了保证速度和伸缩性,Vespa 在多台机器上分布数据和计算任务,避免了单点 master 的瓶颈。传统的应用将数据拉取到一个无状态的层上进行处理,而 Vespa 是将计算任务推送给数据集。为此,Vespa 需要做很多非常棘手的工作,比如当机器发生故障或增加新机器时在后台重新分布数据、实现分布式的低延迟和处理算法、处理分布式数据一致性等。
我们在构建 alltheweb.com(后被 Yahoo 收购)时就开始开发我们的搜索和服务。在过去几年中,我们不断使用新技术重写了我们的引擎。Vespa 是我们发布过的项目当中涉及范围最广、代码量最大的一个项目。Vespa 已经在 Yahoo 的大部分关键系统上得到了实地验证,所以我们很高兴能够把 Vespa 推向世界。
Vespa 赋予了开发者将任意大小数据集和模型填充进服务系统的能力,而且可以实时地得到计算结果,带来更好的用户体验,而且成本更低,比预计算方式具有更低的复杂度。而且,开发者可以与复杂的计算展开实时的交互,不需要启动离线作业或反复回过头来检查结果。
Vespa 可以运行在自有数据中心或云端。我们提供了 Vespa 的 Docker 镜像和 rpm 安装包,也提供了运行指南,可以让 Vespa 运行在本地机器或 AWS 集群上。
这个( http://docs.vespa.ai/ )是我们的文档,里面包含了一个入门指南。
管理分布式系统不是件简单的事情。我们投入了大量精力开发Vespa,其他开发者就可以专注在创建功能上,他们可以实现基于大数据集的实时计算,而不是把时间花在集群和数据的管理上。根据我们的文档所给出的指南,你可以在不到十分钟的时间内让一个应用跑起来。
原文地址: http://blog.vespa.ai/post/165763618906/open-sourcing-vespa-yahoos-big-data-processing
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




