
介绍
几个月前,一位客户问我:“目前大数据分析中较快的 Python 数据结构对象是什么? ”我总被问到类似的问题。其中有一些问题很难解决,通常需要多花一些时间才能找到合适的优化解决方案。我一般会在周末和晚上做这些事,并以此为乐。
以前关于这个问题,我第一个简单的答案是 Python List 对象。我曾在许多数据科学项目中使用 List 对象,包括数据管道和提取 - 转换 - 加载(ETL)生产系统等。然后我就想到了以下问题:我可以使用 List 对象进行数百万或数十亿行数据的操作和分析吗?如果我将数据科学项目切分成许多小任务,然后使用最新的 Python asyncio 库异步运行它们,会怎么样呢?基于这些问题,我决定抽出一些时间,借助 Python 数据生态系统库寻找可用于大数据分析的一些实用解决方案。为了便于读者理解和快速验证结果,程序将计算由浮点数组成的一维 NumPy 数组的算术平均值、中值和样本标准差。为了对比程序的运行时间,我将使用以下库:
- NumPy - NumPy 是用于科学计算的基础 Python 包。
- Numba - Numba 提供了由 Python 直接编写的高性能函数来加速应用程序的能力。通过几个注释,面向数组和数学计算较多的 Python 代码就可以被实时编译为原生机器指令。而且 Numba 拥有类似于 C、C++ 和 FORTRAN 的性能,无需切换语言或 Python 解释器。
- asyncio - asyncio 是 Python 异步编程库。
为什么要使用 NumPy?
正如 NumPy 网站所说:“NumPy 是用于科学计算的基础 Python 包。它提供了强大的 N 维数组对象和复杂的(广播)功能。”导入 NumPy 库之后,Python 程序的性能更好、执行速度更快、更容易保证一致性并能方便地使用大量的数学运算和矩阵功能。也许正因为如此,我们不再需要使用 Python List 对象了?重要的是,许多 Python 数据生态系统库都基于 NumPy 之上,像 Pandas 、 SciPy 、 Matplotlib 等等。
用到的 Python 算法
在此我将通过算术平均值、中值和样本标准差的简单计算,来展示不同 Python 程序的运行时间并进行对比。测试数据来自由 64 位浮点数构成的一维 NumPy 数组。我将实现以下三种 Python 算法并对它们进行分析:
- NumPy 数组
- 结合 asyncio 异步库的 NumPy 数组
- 结合 Numba 库的 NumPy 数组
NumPy 数组程序
我们来看看每个算法的代码。每个算法都有遵循面向对象编程(OOP)方法的类对象和主调用程序。类对象包含以下五种方法:
- calculate_number_observation() - 计算观测数
- calculate_arithmetic_mean() - 计算算术平均值
- calculate_median() - 计算中值
- calculate_sample_standard_deviation() - 计算样本标准差
- print_exception_message() - 如果出现异常,打印异常信息
列表 1 显示了单独使用 NumPy 数组的汇总统计类对象代码。
import sys import traceback import time from math import sqrt class SummaryStatistics(object): """ 使用标准过程计算观测数、算术平均值、中值和样本标准差 """ def __init__(self): pass def calculate_number_observation(self, one_dimensional_array): """ 计算观测数 : 参数 one_dimensional_array: numpy 一维数组 : 返回值 观测数 """ number_observation = 0 try: number_observation = one_dimensional_array.size except Exception: self.print_exception_message() return number_observation def calculate_arithmetic_mean(self, one_dimensional_array, number_observation): """ 计算算术平均值 : 参数 one_dimensional_array: numpy 一维数组 : 参数 number_observation: 观测数 : 返回值 算术平均值 """ arithmetic_mean = 0.0 try: sum_result = 0.0 for i in range(number_observation): sum_result += one_dimensional_array[i] arithmetic_mean = sum_result / number_observation except Exception: self.print_exception_message() return arithmetic_mean def calculate_median(self, one_dimensional_array, number_observation): """ 计算中值 {1} : 参数 one_dimensional_array: numpy 一维数组 : 参数 number_observation: 观测数 : 返回值 中值 {1} """ median = 0.0 try: one_dimensional_array.sort() half_position = number_observation // 2 if not number_observation % 2: median = (one_dimensional_array[half_position - 1] + one_dimensional_array[half_position]) / 2.0 else: median = one_dimensional_array[half_position] except Exception: self.print_exception_message() return median def calculate_sample_standard_deviation(self, one_dimensional_array, number_observation, arithmetic_mean): """ 计算样本标准差 : 参数 one_dimensional_array: numpy 一维数组 : 参数 number_observation: 观测数 : 参数 arithmetic_mean: 算术平均值 : 返回值 样本标准差值 """ sample_standard_deviation = 0.0 try: sum_result = 0.0 for i in range(number_observation): sum_result += pow((one_dimensional_array[i] - arithmetic_mean), 2) sample_variance = sum_result / (number_observation - 1) sample_standard_deviation = sqrt(sample_variance) except Exception: self.print_exception_message() return sample_standard_deviation def print_exception_message(self, message_orientation = "horizontal"): """ 打印完整的异常信息 : 参数 message_orientation: 水平或垂直 : 返回值 空 """ try: exc_type, exc_value, exc_tb = sys.exc_info() file_name, line_number, procedure_name, line_code = traceback.extract_tb(exc_tb)[-1] time_stamp = " [Time Stamp]: " + str(time.strftime("%Y-%m-%d %I:%M:%S %p")) file_name = " [File Name]: " + str(file_name) procedure_name = " [Procedure Name]: " + str(procedure_name) error_message = " [Error Message]: " + str(exc_value) error_type = " [Error Type]: " + str(exc_type) line_number = " [Line Number]: " + str(line_number) line_code = " [Line Code]: " + str(line_code) if (message_orientation == "horizontal"): print( "An error occurred:{};{};{};{};{};{};{}".format(time_stamp, file_name, procedure_name, error_message, error_type, line_number, line_code)) elif (message_orientation == "vertical"): print( "An error occurred:\n{}\n{}\n{}\n{}\n{}\n{}\n{}".format(time_stamp, file_name, procedure_name, error_message, error_type, line_number, line_code)) else: pass except Exception: pass
列表 1. 单独使用 NumPy 数组的汇总统计类对象代码
列表 2 显示了汇总统计的主程序。可以看到,程序创建了 summary_statistics 类对象,然后调用其中的方法。该程序导入 NumPy 库以生成一维数组,并使用 time 模块中的 clock() 方法来计算程序的运行时间。
import time import numpy as np from class_summary_statistics import SummaryStatistics def main(one_dimensional_array): # 创建汇总统计类对象 summary_statistics = SummaryStatistics() # 计算观测数 number_observation = summary_statistics.calculate_number_observation(one_dimensional_array) print("Number of Observation: {} ".format(number_observation)) # 计算算术平均值 arithmetic_mean = summary_statistics.calculate_arithmetic_mean(one_dimensional_array, number_observation) print("Arithmetic Mean: {} ".format(arithmetic_mean)) # 计算中值 median = summary_statistics.calculate_median(one_dimensional_array, number_observation) print("Median: {} ".format(median)) # 计算样本标准差 sample_standard_deviation = summary_statistics.calculate_sample_standard_deviation(one_dimensional_array, number_observation, arithmetic_mean) print("Sample Standard Deviation: {} ".format(sample_standard_deviation)) if __name__ == '__main__': start_time = time.clock() one_dimensional_array = np.arange(100000000, dtype=np.float64) main(one_dimensional_array) end_time = time.clock() print("Program Runtime: {} seconds".format(round(end_time - start_time, 1)))
列表 2. 使用 NumPy 数组的汇总统计类对象代码
当行数达到 1 百万时,汇总统计主程序将得到以下结果:
观测数: 1000000 算术平均值: 499999.5 中值: 499999.5 样本标准差: 288675.27893349814 程序运行时间: 1.3 秒
结合 asyncio 异步库的 NumPy 数组
列表 3 显示了结合 Python asyncio 异步库的汇总统计 asyncio 类对象代码。请注意,main() 方法使用 calculate_number_observation() 作为第一个也是唯一任务来启动事件循环异步进程。
import sys import time import traceback import asyncio from math import sqrt class SummaryStatisticsAsyncio(object): """ 使用 asyncion 库计算观测数、算术平均值、中值和样本标准差 """ def __init__(self): pass async def calculate_number_observation(self, one_dimensional_array): """ 计算观测数 : 参数 one_dimensional_array: numpy 一维数组 : 返回值 空 """ try: print('start calculate_number_observation() procedure') await asyncio.sleep(0) number_observation = one_dimensional_array.size print("Number of Observation: {} ".format(number_observation)) print(" 观测数: {} ".format(number_observation)) await self.calcuate_arithmetic_mean(one_dimensional_array, number_observation) print("finished calculate_number_observation() procedure") except Exception: self.print_exception_message() async def calcuate_arithmetic_mean(self, one_dimensional_array, number_observation): """ 计算算术平均值 : 参数 one_dimensional_array: numpy 一维数组 : 参数 number_observation: 观测数 : 返回值 空 """ try: print('start calcuate_arithmetic_mean() procedure') await self.calculate_median(one_dimensional_array, number_observation) sum_result = 0.0 await asyncio.sleep(0) for i in range(number_observation): sum_result += one_dimensional_array[i] arithmetic_mean = sum_result / number_observation print("Arithmetic Mean: {} ".format(arithmetic_mean)) await self.calculate_sample_standard_deviation(one_dimensional_array, number_observation, arithmetic_mean) print("finished calcuate_arithmetic_mean() procedure") except Exception: self.print_exception_message() async def calculate_median(self, one_dimensional_array, number_observation): """ 计算中值 : 参数 one_dimensional_array: numpy 一维数组 : 参数 number_observation: 观测数 : 返回值 空 """ try: print('starting calculate_median()') await asyncio.sleep(0) one_dimensional_array.sort() half_position = number_observation // 2 if not number_observation % 2: median = (one_dimensional_array[half_position - 1] + one_dimensional_array[half_position]) / 2.0 else: median = one_dimensional_array[half_position] print("Median: {} ".format(median)) print("finished calculate_median() procedure") except Exception: self.print_exception_message() async def calculate_sample_standard_deviation(self, one_dimensional_array, number_observation, arithmetic_mean): """ 计算样本标准差 : 参数 one_dimensional_array: numpy 一维数组 : 参数 number_observation: 观测数 : 参数 arithmetic_mean: 算术平均值 : 返回值 空 """ try: print('start calculate_sample_standard_deviation() procedure') await asyncio.sleep(0) sum_result = 0.0 for i in range(number_observation): sum_result += pow((one_dimensional_array[i] - arithmetic_mean), 2) sample_variance = sum_result / (number_observation - 1) sample_standard_deviation = sqrt(sample_variance) print("Sample Standard Deviation: {} ".format(sample_standard_deviation)) print("finished calculate_sample_standard_deviation() procedure") except Exception: self.print_exception_message() def print_exception_message(self, message_orientation = "horizontal"): """ 打印完整异常消息 : 参数 message_orientation: 水平或垂直 : 返回值 空 """ try: exc_type, exc_value, exc_tb = sys.exc_info() file_name, line_number, procedure_name, line_code = traceback.extract_tb(exc_tb)[-1] time_stamp = " [Time Stamp]: " + str(time.strftime("%Y-%m-%d %I:%M:%S %p")) file_name = " [File Name]: " + str(file_name) procedure_name = " [Procedure Name]: " + str(procedure_name) error_message = " [Error Message]: " + str(exc_value) error_type = " [Error Type]: " + str(exc_type) line_number = " [Line Number]: " + str(line_number) line_code = " [Line Code]: " + str(line_code) if (message_orientation == "horizontal"): print( "An error occurred:{};{};{};{};{};{};{}".format(time_stamp, file_name, procedure_name, error_message, error_type, line_number, line_code)) elif (message_orientation == "vertical"): print( "An error occurred:\n{}\n{}\n{}\n{}\n{}\n{}\n{}".format(time_stamp, file_name, procedure_name, error_message, error_type, line_number, line_code)) else: pass except Exception: pass def main(self, one_dimensional_array): """ 启动事件循环异步进程 : 参数 one_dimensional_array: numpy 一维数组 """ try: ioloop = asyncio.get_event_loop() tasks = [ioloop.create_task(self.calculate_number_observation(one_dimensional_array))] wait_tasks = asyncio.wait(tasks) ioloop.run_until_complete(wait_tasks) ioloop.close() except Exception:
列表 3. 结合 Python 异步库的汇总统计 asyncio 类对象代码
汇总统计 asyncio 主程序如列表 4 所示。可以看到 main() 方法是唯一被调用的方法。
import time import numpy as np from class_summary_statistics_asyncio import SummaryStatisticsAsyncio def main(one_dimensional_array): # 新建汇总统计 asyncio 类对象 summary_statistics_asyncio = SummaryStatisticsAsyncio() # 调用 main 方法 summary_statistics_asyncio.main(one_dimensional_array) if __name__ == '__main__': start_time = time.clock() one_dimensional_array = np.arange(1000000000, dtype=np.float64) main(one_dimensional_array) end_time = time.clock() print("Program Runtime: {} seconds".format(round(end_time - start_time, 1)))
列表 4. 结合 Python 异步库的汇总统计 asyncio 主程序代码
当行数达到 1 百万时,结合 asyncio 库的汇总统计主程序将得到以下结果。我加入了 开始 / 结束过程的打印,以展示异步过程在这种特殊情况下的工作原理。
start calculate_number_observation() procedure 观测数: 1000000000 start calcuate_arithmetic_mean() procedure starting calculate_median() 中值: 499999.5 finished calculate_median() procedure 算术平均值: 499999.5 start calculate_sample_standard_deviation() procedure 样本标准差: 288675.27893349814 finished calculate_sample_standard_deviation() procedure finished calcuate_arithmetic_mean() procedure finished calculate_number_observation() procedure 程序运行时间: 1504.4 秒
结合 Numba 库的 NumPy 数组
结合 Numba 库的汇总统计类对象代码如列表 5 所示。你可以访问 Numba 在 GitHub 上的目录,以了解更多关于这个Python 的开源NumPy 感知优化编译器的信息。值得一提的是Numba 支持 CUDA GPU 编程。下面的代码中,调试代码已被删除,以便在编译模式下运行该程序。
import time from numba import jit import numpy as np from math import sqrt class SummaryStatisticsNumba(object): """ 结合 numba 库计算观测数、算术平均值、中值和样本标准差 """ def __init__(self): pass @jit def calculate_number_observation(self, one_dimensional_array): """ 计算观测数 : 参数 one_dimensional_array: numpy 一维数组 : 返回值 观测数 """ number_observation = one_dimensional_array.size return number_observation @jit def calcuate_arithmetic_mean(self, one_dimensional_array, number_observation): """ 计算算术平均值 : 参数 one_dimensional_array: numpy 一维数组 : 参数 number_observation: 观测数 : 返回值 算术平均值 """ sum_result = 0.0 for i in range(number_observation): sum_result += one_dimensional_array[i] arithmetic_mean = sum_result / number_observation return arithmetic_mean @jit def calculate_median(self, one_dimensional_array, number_observation): """ 计算中值 : 参数 one_dimensional_array: 指 numpy 一维数组 : 参数 number_observation: 观测数 : 返回值 中值 """ one_dimensional_array.sort() half_position = number_observation // 2 if not number_observation % 2: median = (one_dimensional_array[half_position - 1] + one_dimensional_array[half_position]) / 2.0 else: median = one_dimensional_array[half_position] return median @jit def calculate_sample_standard_deviation(self, one_dimensional_array, number_observation, arithmetic_mean): """ 计算样本标准差 : 参数 one_dimensional_array: numpy 一维数组 : 参数 number_observation: 观测数 : 参数 arithmetic_mean: 算术平均值 : 返回值 样本标准差值 """ sum_result = 0.0 for i in range(number_observation): sum_result += pow((one_dimensional_array[i] - arithmetic_mean), 2) sample_variance = sum_result / (number_observation - 1) sample_standard_deviation = sqrt(sample_variance) return sample_standard_deviation
列表 5 结合 Numba 库的汇总统计类对象代码
汇总统计 Numba 主程序如列表 6 所示。
import time import numpy as np from class_summary_statistics_numba import SummaryStatisticsNumba def main(one_dimensional_array): # 创建类汇总统计 numba 类对象 class_summary_statistics_numba = SummaryStatisticsNumba() # 计算观测数 number_observation = class_summary_statistics_numba.calculate_number_observation(one_dimensional_array) print("Number of Observation: {} ".format(number_observation)) # 计算算术平均值 arithmetic_mean = class_summary_statistics_numba.calcuate_arithmetic_mean(one_dimensional_array, number_observation) print("Arithmetic Mean: {} ".format(arithmetic_mean)) # 计算中值 median = class_summary_statistics_numba.calculate_median(one_dimensional_array, number_observation) print("Median: {} ".format(median)) # 计算样本标准差 sample_standard_deviation = class_summary_statistics_numba.calculate_sample_standard_deviation(one_dimensional_array, number_observation, arithmetic_mean) print("Sample Standard Deviation: {} ".format(sample_standard_deviation)) if __name__ == '__main__': start_time = time.clock() one_dimensional_array = np.arange(1000000000, dtype=np.float64) main(one_dimensional_array) end_time = time.clock() print("Program Runtime: {} seconds".format(round(end_time - start_time, 1)))
列表 6. 汇总统计 Numba 主程序
当行数达到十亿时,汇总统计 Numba 主程序将得到以下结果。
观测数: 1000000000 算术平均值: 499999999.067109 中值: 499999999.5 样本标准差: 288675134.73899055 程序运行时间: 40.2 秒
NumPy 数组达到十亿行时,计算在 40.2 秒内就完成了,这真是一个激动人心的结果。我认为现在是时候在大数据项目中更多地使用 Numba 库和 NumPy 数组了。当然某些特殊场景可能还需要进一步研究和测试。
笔记本硬件参数
下面是我运行上面这些 Python 程序所使用的笔记本电脑硬件参数:
- Windows 10 64 位操作系统
- 英特尔酷睿™i7-2670QM CPU @2.20 GHz
- 16 GB 内存
程序运行时间对比
表 1 显示了数据行数为 100 万、1000 万、1 亿和 10 亿时不同程序的运行时间。
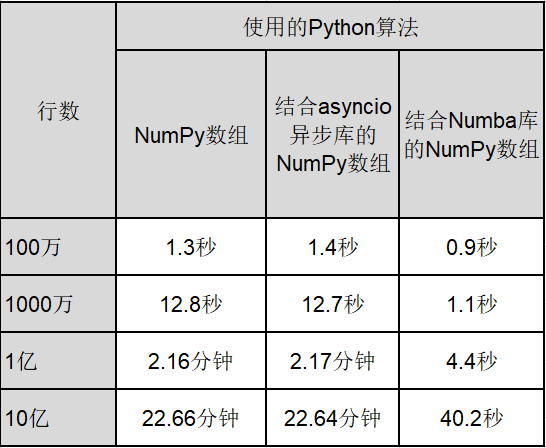
表 1: 程序运行时间对比
结论
- 单独使用 NumPy 数组与结合 asyncio 异步库的 NumPy 数组之间没有明显差别。由于本次计算量不足以证明 Python 数据科学项目中 asyncio 异步库的性能,因此可能需要进行更多的研究来找到它适合的应用场景。
- 与单独使用 NumPy 数组或结合 asyncio 异步库的 NumPy 数组相比,将 NumPy 数组与 Numba 库组合具有最佳的数据操作和分析性能。当 Numpy 数组中有十亿行数据时,执行时间竟然只需要 40.2 秒,令我印象深刻。我怀疑目前的 R 程序是否也可以达到这样的速度。如果不能,也许现在就是 R 程序的程序员学习 Python 及其数据生态系统库的时候了。除此之外,请务必采用持续集成软件开发和部署实践,使用面向对象编程方法论来为实际的生产环境编写 Python 程序。
- 在具有不同类型数据源的数据管道和提取 - 转换 - 加载(ETL)系统项目中,使用结合 Numba 库的 NumPy 数组是目前大数据分析的最佳编程实践之一。你不再需要使用 Python List 对象。
最后,献上我在软件业务应用设计和开发领域摸爬滚打 25 年之后最喜欢的句子之一:
_“__ 一个差 __ 的程序员写代码只是为了 __ 能 __ 运行,_而一个 __ 好的程序员写代码不只是为了运行程序,也为了以后可以 __ 更方便地维护和 __ 更新” - Ernest Bonat 博士
如有关于本文的任何问题,可以随时给 Ernest 发送电子邮件。
感谢蔡芳芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...












评论