第六版论文中使用了不同的硬件平台、在三种不同类型的流行深度学习方法上对 GPU 加速工具的评估。根据基准评测结果,当存在 GPU 时,团队发现 Caffe 平台在全连接网络上表现更好,而 TensorFlow 在卷积神经网络和循环神经网络上都表现突出。GPU 内存是在 Caffe 等许多工具上运行大型网络的关键指标之一,CNTK 和 Torch 不能在 GTX 980(其有 4GB 内存)上运行 32 或更多个 mini-batch 大小的 ResNet-50,而 TensorFlow 在管理 GPU 内存上表现更好,并且其基本上可以在所有的配置情况下运行。cuBLAS 是一个高性能的 BLAS 库,但其 API 参数对实现好的结果来说是很重要的。在计算一些情况下的卷积运算时,FFT 是一个更好的选择。
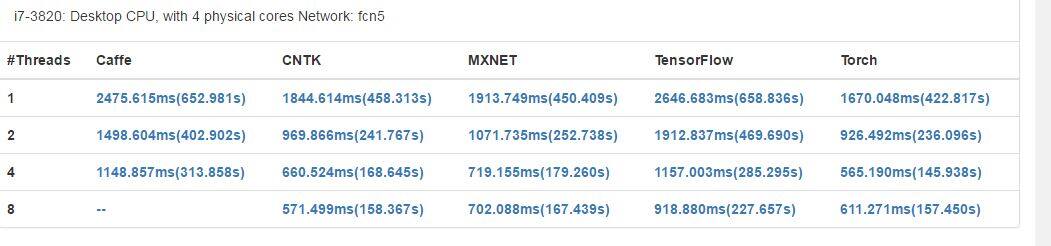
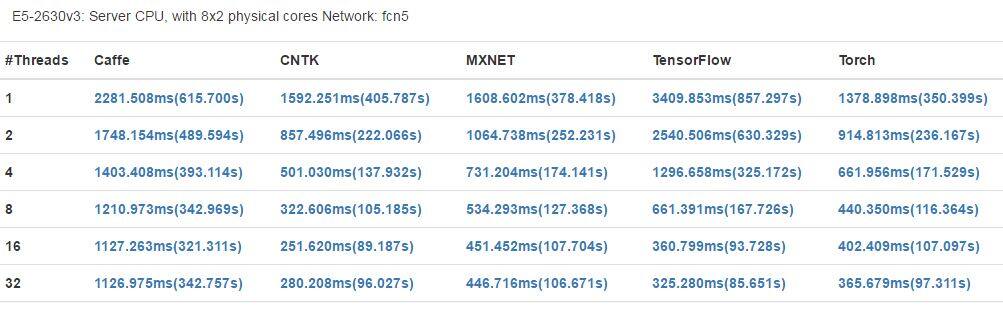
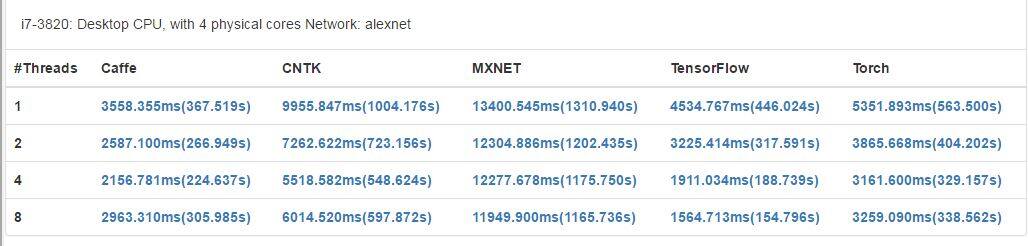
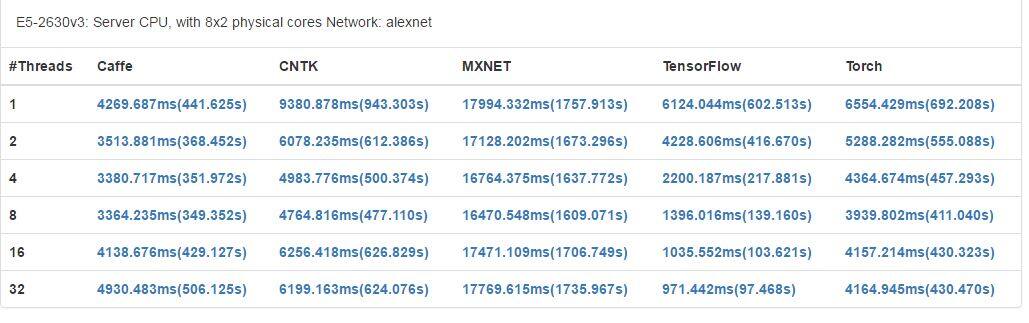
在仅使用 CPU 的机器上,Caffe 在 CPU 并行上表现更好,TensorFlow 也在 CPU 资源利用上有很好的表现。在 CPU 并行机制上,使分配的线程等于 CPU 的核数可以得到更好的表现。
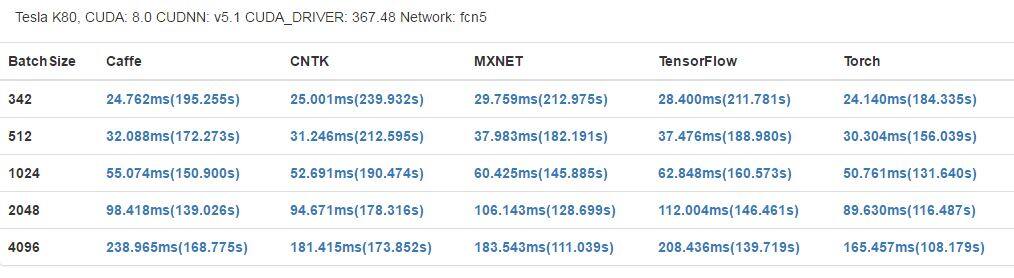
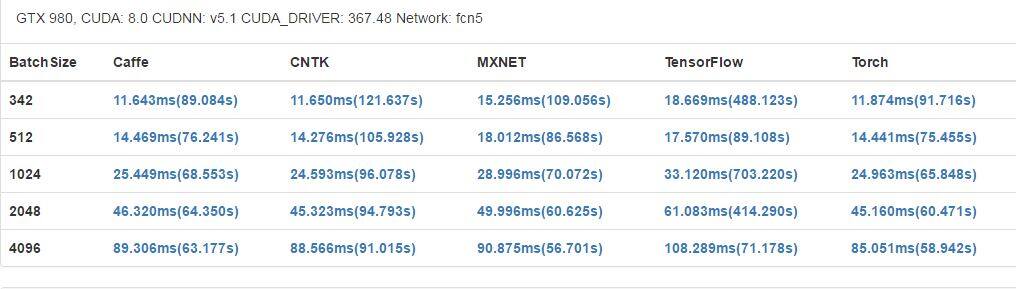
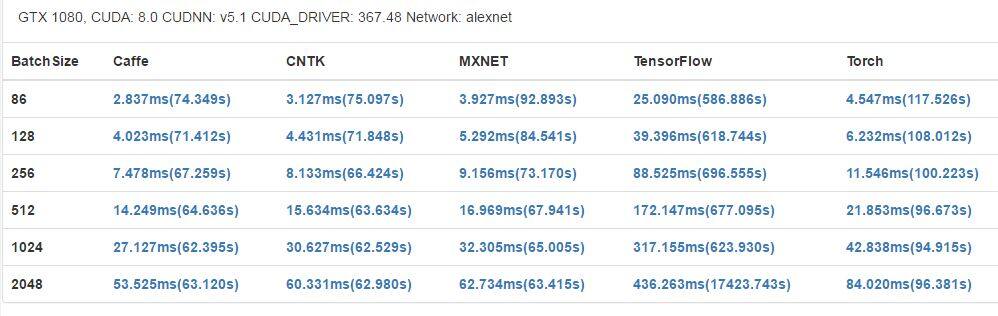
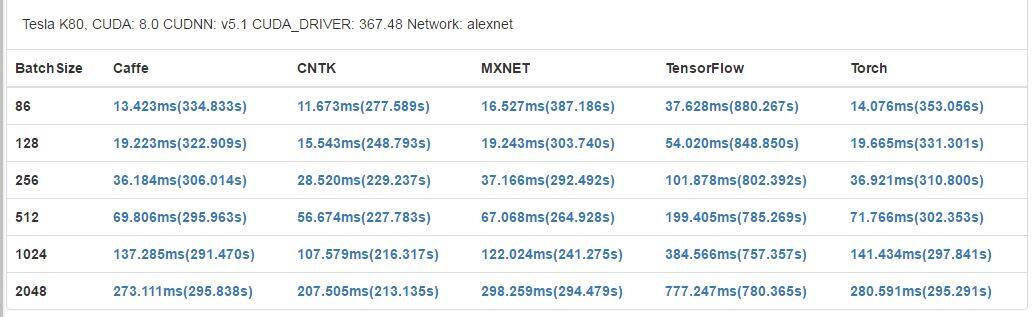
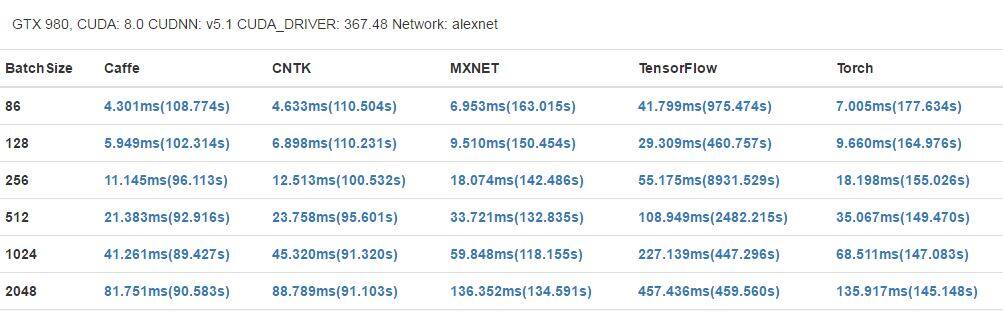
GTX 1080 有更高的基础时钟(1733 MHz)和更多 CUDA 内核,在大部分案例中也都获得了更好的结果。但是,Tesla K80 有更大的内存(12 GB),可以支持应用运行更大型的网络和更大的 mini-batch。此外,每一个 K80 卡还配备了 2 个 GPU 芯片,这可能能让其在运行并行程序时获得更好的表现,但在我们的基准评测中,它并没有得到充分的使用。
第六版时局限:团队没有测试跨多个 GPU 和多台机器的可扩展性,因为这种方法可能无法增强一些工具的主要特性。比如虽然 CNTK 支持跨多 GPU 和机器运行,但其它工具却不行。
论文第七版

深度学习已被证明是一种可成功用于许多任务的机器学习方法,而且它的广泛流行也将很多开源的深度学习软件工具开放给了公众。训练一个深度网络往往是一个非常耗时的过程。为了解决深度学习中巨大的计算难题,许多工具利用了多核 CPU 和超多核 GPU 这样的硬件特性来缩短训练时间。但是,在不同的硬件平台上训练不同类型的深度网络时,不同的工具会有不同的特性和运行性能,这让终端用户难以选择出合适的软件和硬件搭配。
在这篇论文中,团队的目标是对当前最先进的 GPU 加速的深度学习软件工具(包括:Caffe、CNTK、MXNet、TensorFlow 和 Torch)进行比较研究。团队将在两种 CPU 平台和三种 GPU 平台上使用三种流行的神经网络来评测了这些工具的运行性能。
团队做出了两方面的贡献:
- 对于深度学习终端用户,我们的基准评测结果可用于指导合适的软件工具和硬件平台的选择。
- 对于深度学习软件开发者,我们的深度分析为进一步优化训练的性能指出了可能的方向。
评测软件工具、算法
- Caffe: 1.0.0(4ba654f)
- CNTK: 1.72(f686879)
- MXNet: 0.7(34b2798)
- TensorFlow: 0.11(47dd089)
- Torch: 7(5c7c762)
- 全连接网络
- 卷积神经网络: AlexNet 、 ResNet
- 循环神经网络
测试环境

对于数据并行的测试硬件:

单 CPU 卡评测结果

根据团队之前的研究,在 CPU 平台上测试特定的 mini-batch 大小 d 的实验能够获得最好的运行时间表现。不同网络使用的 mini-batch 的大小如表所示:
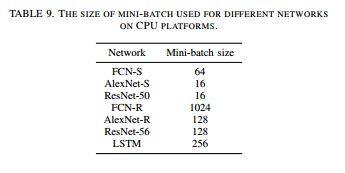
在单 GPU 卡的对比上,我们也展示了不同 mini-batch 大小的结果,从而演示 mini-batch 大小对表现的影响。
多 GPU 卡评测结果
FCN-R:在我们的测试中,mini-batch 的大小设置为 4096,结果如图 16 所示。在图 16(a) 中,我们可以看到 Caffe、CNTK 和 MXNet 的速度非常接近单 GPU 的情况;而在 TensorFlow 和 Torch 上的表现则相对好一点。当 GPU 数量翻倍时,CNTK 和 MXNet 的可扩展性最好,均实现了约 35% 的提速,Caffe 实现了大约 28% 的提速,而 Torch 和 TensorFlow 较差,只有约 10%。当我们把 GPU 数量从 2 个增加到 4 个时,TensorFlow 和 Torch 没有实现进一步的提速。
整体评测数据
- fcn5
- alexnet
结论
本次研究旨在对比现代深度学习软件工具的运行性能,测试它们在不同类型的神经网络和不同的硬件平台上的执行效率。团队通过实验结果表明,目前所有经过测试的工具都可以很好地利用 GPU,和使用 CPU 相比有着很大优势。然而,没有任何一个工具可以在所有方面胜过其他软件工具,这意味着也许存在进一步优化性能的方向。
在未来的研究中,首先,团队会将更多的深度学习软件工具(如百度的 Paddle)和硬件平台(如 AMD 的 GPU 和英特尔 XeonPhi)纳入这项基准研究。其次,团队计划评估在高性能 GPU 集群上这些工具的可扩展性。
附录
论文第二版
论文第三版,更新于 2016 年 9 月 3 日
论文第四版,更新于 2016 年 9 月 11 日
论文第五版,更新于 2016 年 9 月 19 日
论文第六版,更新于 2017 年 1 月 25 日
论文第七版
源代码下载地址
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




