
AI 的出现为人类社会带来了新一轮的技术革命,如何更好的解决人类的问题是 AI 研究的一个重要课题。然而最近,关于 AI 将会取代部分人力工作的说法不仅在科技圈炸了锅,更让对技术并不很了解的非科技从业者也感觉到了压力,提到人工智能,现在人们最担心的是:它对不会取代我的工作?
有了这样的担忧,身在科技圈的 AI 公司们就开始行动起来,通过实际行动来消除民众的担忧。既然担心人力被 AI 替代,那么人与 AI 协作如何?
PAIR 的诞生
作为世界科技巨头之一的谷歌推出了一项叫做 PAIR(People + AI Research) 的 AI 项目,希望能够通过研究以及重新设计人与 AI 系统的交互方式并试图确保这项技术能造福每个人。谷歌表示,PAIR 将在 AI 供应链中对大量会影响到每个人的不同课题展开研究–从开发算法的研究人员到医生、设计师、农民等这些正在使用或将要使用专业 AI 工具的专业人士。
根据不同的用户需求,PAIR 计划的研究内容分成了三个部分:
- 工程师和研究人员:AI 是由人打造的。Google 如何让工程师更加容易地理解和打造机器学习系统?他们需要什么样的教学材料和开发工具?
- 各领域专家:AI 如何帮助专业人士开展他们的工作?随着医生、技师、设计师、农场主以及音乐家越来越多地使用 AI,Google 如何为他们提供支持?
- 日常用户:Google 如何确保机器学习的包容性,让每个人都能受益于 AI 的突破性进展?设计思维能否解锁全新的 AI 应用?能否实现 AI 背后技术的普及化?
PAIR 团队由谷歌大脑研究员 Fernanda Viégas 与 Martin Wattenberg 带领,两位均是数据可视化专家。12 名全职谷歌大脑员工将加入。除此之外,PAIR 还将与谷歌之外的研究人员合作,譬如哈佛大学教授 Brendan Meade 以及 MIT 教授 Hal Abelson。和愿景相比,PAIR 的核心团队一点也不算大。不过有消息称,PAIR 是一个“全公司尺度”的项目,谷歌的各个研究部门会与之密切合作。
开源工具:Facets
通过 PAIR 项目,谷歌发布了 Facets——这是一款开源可视化工具,旨在帮助用户理解并分析各类机器学习数据集。
Facets 当中包含两款可视化方案,允许用户以不同的细化水平获取关于数据的整体观点。其中 Facets Overview 负责帮助您掌握数据中的每项具体特征,而 Facets Dive 则用于对个别数据组进行观察。
这两套可视化方案能够帮助您进行数据调试——这项工作在机器学习当中与模型调试拥有同等重要的地位。另外,用户亦可以将其轻松纳入 Jupyter 记事本或者嵌入至网页当中。除了开源代码之外,谷歌还建立起 Facets 演示网站。用户可直接在自己的浏览器当中借助此网站对自己的数据集进行可视化——无需安装或者设置任何软件,数据也绝不会离开您的计算机。
Facets Overview
Facets Overview 以自动化方式帮助用户快速掌握数据集内各项特征值的分布情况。您亦可立足同一可视化视图对多套数据集进行比对——例如训练集与测试集。在这里,您将能够顺利解决阻碍机器学习的各类常见数据问题,包括预料之外的特征值、存在严重值缺失的特征、分布不均衡的特征以及数据集之间的特征分布偏差等等。
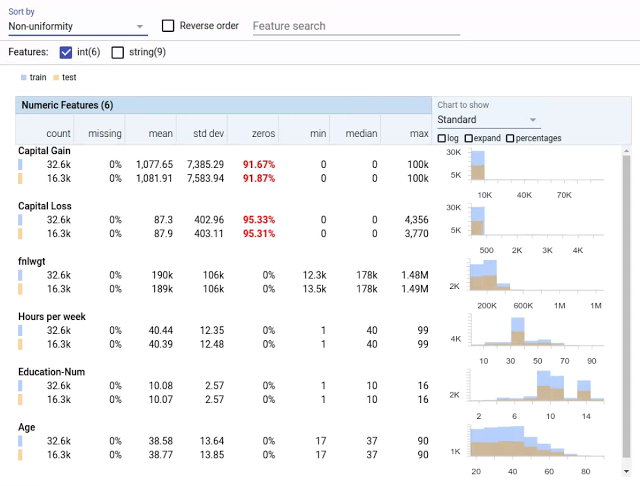
Facets Overview 对 UCI 人口普查数据集内六组数字特征进行可视化。各特征按照非均匀性排序,上部为分布最不均匀的特征。红色数字表示可能存在的故障点,在本示例中为存在大量 0 值的数字特征。右侧的直方图则允许您直接比较训练数据(蓝色)与测试数据(橙色)之间的分布差异。
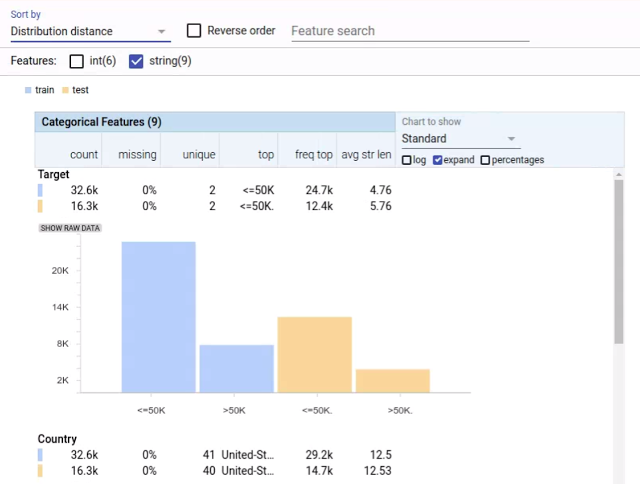
Facets Overview 的可视化结果显示了 UCI 人口普查数据集中九项分类特征中的两项。各特征按照分布距离进行排序,其中训练(蓝色)与测试(橙色)数据集顶部的特征间具有最大偏差。需要注意的是,“Target”特征的标签植在训练与测试数据集之间存在差异,这是由测试集内存在的尾随点所造成(‘〈=50K’与‘〈=50K’〉。我们可以在图表以及表格最上列中的条目中看到。这种标签不匹配性将导致利用这部分数据进行训练及测试的模型无法得到正确评估。
Overview 亦可帮助我们发现数据集当中包含的问题,具体包括:
- 预料之外的特征值
- 大量示例当中缺失的特征值
- 训练 / 服务偏差
- 训练 / 测试 / 验证集偏差
可视化工作的关键,在于跨越多个数据集进行异常植检测与分布结果比较。其中红色部分用于高亮显示需要关注的值(例如缺失数据比例过高或者各数据集间的特征分布存在巨大差异)。各项特征亦可按照您的关注度值进行排序——这项关注度值可设定为缺失值的数量或者不同数据集间的偏差。
欲了解更多与 Overview 使用方法相关的细节信息,请参阅其说明页面。
说明页面: https://github.com/PAIR-code/facets/blob/master/facets_overview/README.md
Facets Dive
Dive 是一款用于以交互方式探索成千上万个数据点的工具,允许用户在高级概述与低级细节之间进行无缝切换。每项示例将在可视化视图当中表达为单一条目,并可通过其具体特征值在多个维度上通过平面 / 三维方式进行定位。通过将平滑的动画与缩放同定位与过滤相结合,Dive 能够帮助我们轻松地复杂的数据集当中发现模式及各类异常值。

Facets Dive 可视化方案在 UCI 人口普查测试数据集内显示出全部 16281 个数据点。此动画效果向用户显示出经过着色的各数据点,不同颜色代表不同特征(即‘关系’)。通过在其中一个维度上分层以代表一项接续特征(即‘年龄’),而在另一维度上分层则代表一项离散特征(即‘婚姻状况’)。
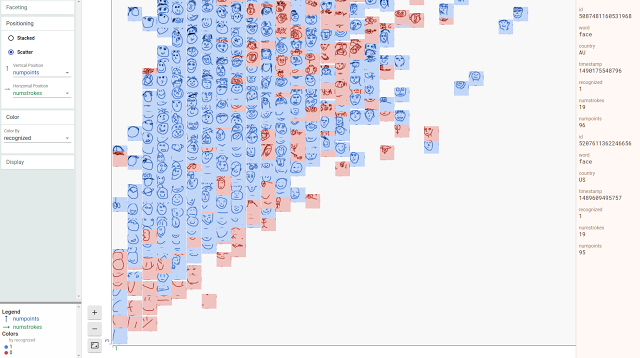
Facets Dive 对“Quick,Draw!”数据集内的大量面部绘图进行可视化处理,结果显示了图形当中笔画数与点数之间的关系,同时亦能够帮助“Quick,Draw!”分类器将各图像正确分类为面孔。
Fun fact: 在大规模数据集当中——例如 CIFAR-10 数据集,人类标记中的小错误往往很容易被忽略。谷歌研究员们利用 Dive 对 CIFAR-10 数据集进行了检查,并从中发现了一只“青蛙猫”——即被错误标记为猫的青蛙图像。

利用 Facets Dive 探索 CIFAR-10 数据集。在这里,研究员逐行对为真标签进行分层,并逐列给出预测标签。由此产生的混淆矩阵视图允许研究者进一步发现属于特定类型的错误分类。在本示例当中,机器学习模型错误地将一小部分青蛙图片分类为猫。通过将为真图像放置在混淆矩阵当中,研究者发现了这项有趣的事实,即模型将某只青蛙误判为猫。利用 Facets Dive,研究者们得以意识到这项错误的实际根源——并非模型进行错误的分类,而是数据集当中存在错误的数据标记。
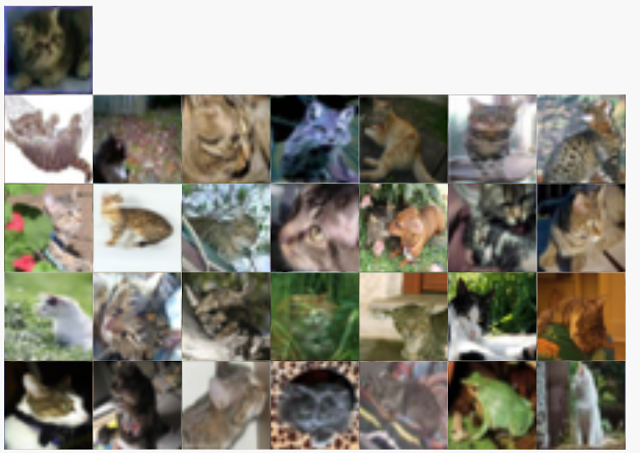
您能找到那只“青蛙猫”吗?
欲了解更多与 Dive 使用方法相关的细节信息,请参阅其说明页面。
说明页面: https://github.com/PAIR-code/facets/blob/master/facets_dive/README.md
在谷歌公司内部,已经利用 Facets 实现了巨大的应用价值,谷歌的开发者们也很高兴能够与全世界分享这款可视化工具。他们希望这些工具能帮助大家在自己的数据当中发现新鲜有趣的结论,进而构建起更为强大且准确的机器学习模型。由于这些工具属于开源项目,因此来自全球的开发者们亦可根据自己的具体需求对可视化内容进行定制,或者通过项目贡献帮助谷歌更好地理解数据内容。
公众号推荐:
AGI 概念引发热议。那么 AGI 究竟是什么?技术架构来看又包括哪些?AI Agent 如何助力人工智能走向 AGI 时代?现阶段营销、金融、教育、零售、企服等行业场景下,AGI应用程度如何?有哪些典型应用案例了吗?以上问题的回答尽在《中国AGI市场发展研究报告 2024》,欢迎大家扫码关注「AI前线」公众号,回复「AGI」领取。


InfoQ编辑

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论