Yelp 每天要运行数百万个测试,确保开发人员提交的代码不会对已有的功能造成破坏。如此巨大规模的测试,他们是怎么做到的呢?以下内容翻译自 Yelp 的技术博客,并已获得翻译授权,查看原文 How Yelp Runs Millions of Tests Every Day 。
开发速度对于一个公司的成败来说是至关重要的。我们总是通过减少测试、部署和监控变更的时间来提升开发效率。为了让开发者能够安全地提交代码,我们每天通过内部的分布式系统 Seagull 运行了超过数百万个测试。

Seagull 是什么?
Seagull 是一个具备容错能力和弹性的分布式系统,我们用它来并行执行我们的测试套件。我们使用了如下技术来构建 Seagull 。
- Apache Mesos (用于管理 Seagull 集群的资源)
- AWS EC2 (为 Seagull 和 Jenkins 集群提供实例)
- AWS DynamoDB (保存调度器的元数据)
- Docker (为测试要用到的服务提供隔离)
- Elasticsearch (跟踪测试的运行时间和集群数据的使用情况)
- Jenkins (构建代码并运行 Seagull 调度器)
- Kibana 和 SignalFx (用于监控和告警)
- AWS S3 (作为测试日志的真实来源)
挑战
在将我们的单体 Web 应用 yelp-main 的新代码部署到生产环境之前,Yelp 的开发人员针对 yelp-main 的特定版本运行了整个测试套件。开发人员通过触发 seagull-run 作业来运行测试,这个作业将会在我们的集群上安排调度以便运行测试用例。这里需要考虑两方面的因素。
- 性能:每一个 seagull-run 作业都有将近 10 万个测试用例,如果逐个运行它们需要差不多 2 天的时间。
- 规模:一般情况下,每天会有超过 300 个 seagull-run 作业被触发,高峰期有 30 到 40 个作业并行运行。
我们所面临的挑战是如何在分钟级别运行每一个 seagull-run 作业,而不是按天来运行,同时还能保持较低的成本。
Seagull 的工作原理
首先,开发人员在控制台触发 seagull-run,它会启动一个 Jenkins 作业,用于编译代码,并生成测试清单。这些测试清单被组合在一起,传递给一个调度器,调度器将会在 Seagull 集群上执行测试。最后,测试结果被保存到 Elasticsearch 和 S3 上。
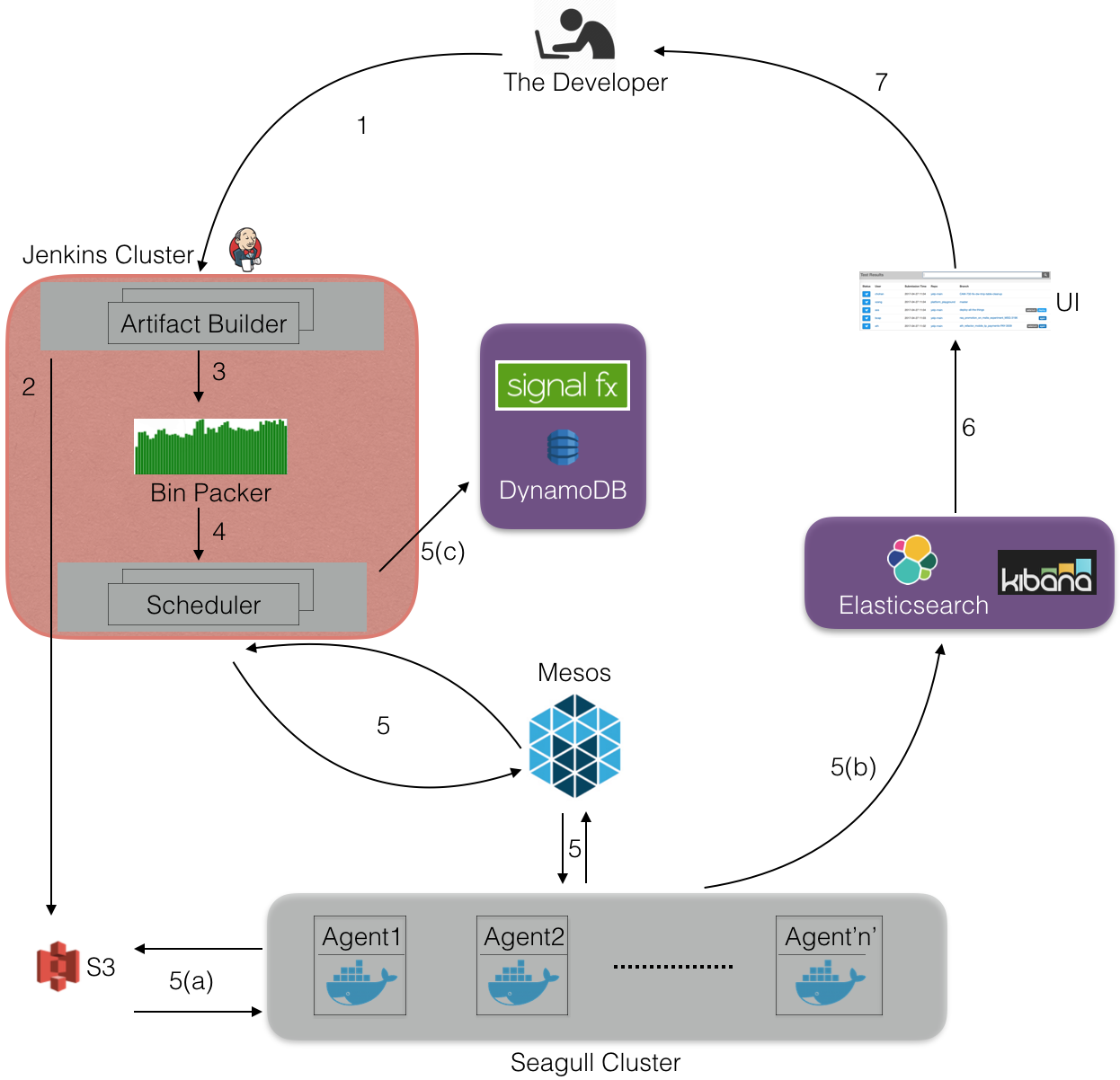
1. 一个开发人员为某个版本的代码(基于 git 某个分支的 SHA 值)触发了一个 seagull-job,我们假设 git 分支的名字叫作 test_branch。
2. 为 test_branch 生成代码包和测试清单,并上传到 S3 上。
3.Bin Packer 获取测试清单和测试历史时间元数据,用于创建多个包含了测试用例的 bundle。如何进行有效的 bundle 其实是一个装箱问题,我么使用了如下两种算法来解决这个问题。至于使用哪一种算法,由开发人员传给 Seagull 的参数来决定。
-
贪婪算法( Greedy Algorithm ):测试用例先是按照它们的历史测试时长来排序,然后我们开始按照 10 分钟的工作量(测试用例)来填充 bundle。
-
线性编程( Linear Programming ):如果出现了测试依赖,一个测试需要与同一个 bundle 里的另一个测试一起运行。对于这种情况,我们将会使用线性编程。线性编程方程式的目标函数和约束定义如下。
-
目标函数:最小化生成 bundle 的数量
-
主要的约束:
- 单个 bundle 的运行时长不超过 10 分钟
- 每个测试只能存在于一个 bundle 里
- 具有依赖关系的测试需要被放在同一个 bundle 里
-
我们使用了 Pulp 来解开这个方程式。
# 目标函数:
problem = LpProblem('Minimize bundles', LpMinimize)
problem += lpSum([bundle[i] for i in range(max_bundles)]), 'Objective: Minimize bundles'
# 其中的一个约束:
for i in range(max_bundles):
sum_of_test_durations = 0
for test in all_tests:
sum_of_test_durations += test_bundle[test, i] * test_durations[test]
problem += (sum_of_test_durations) <= bundle_max_duration * bundle[i], ''
在这里,bundle 和 test_bundle 是 LpVariable 类型,max_bundles 和 bundle_max_duration 是整数。
一般情况下,我们会在线性编程约束里考虑测试用例的 setup 和 teardown 时长,不过为了简单起见,我们在这里把它们忽略了。
4. 在 Jenkins 服务器上启动一个调度器进程,它将会获取 bundle,然后启动一个 mesos 框架。我们为每一个 seagull-run 创建一个新的调度器。每次运行会生成 300 多个 bundle,每个 bundle 大概需要 10 分钟的运行时间。调度器为每一个 bundle 创建了一个 mesos 执行器,并被安排在 Seagull 集群上执行,只要 Mesos Master 能够提供可用的资源。
5. 在执行器被安排到集群上之后,执行器内部将执行如下几个步骤。
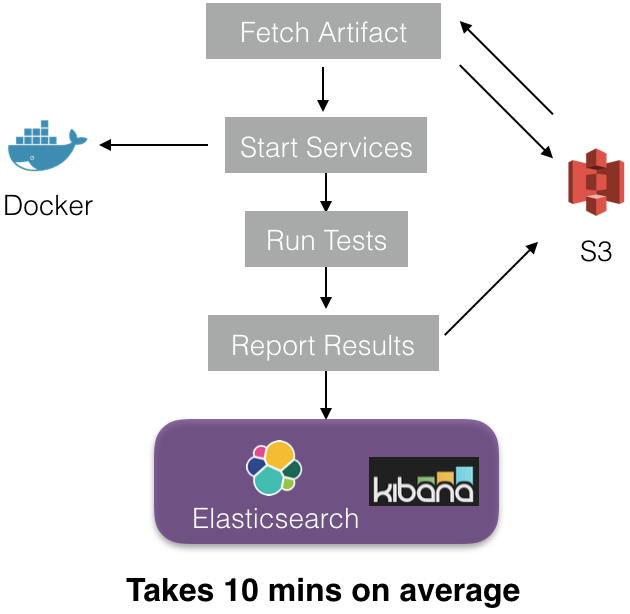
每个执行器启动一个沙箱,并从 S3 上下载软件包(它们是在第二步时上传到 S3 上的)。测试服务所依赖的 Docker 镜像被下载下来,用于启动 docker 容器(也就是服务)。在所有的容器都运行起来之后,开始执行测试。最后,测试结果和元数据被保存到 Elasticsearch(ES)和 S3 上。我们使用了内部的代理服务 Apollo 将数据写到 ES 上。
如果你处在一个分布式环境里,那么遭遇主机崩溃是一件不可避免的事情。不过,Seagull 具有容错能力。
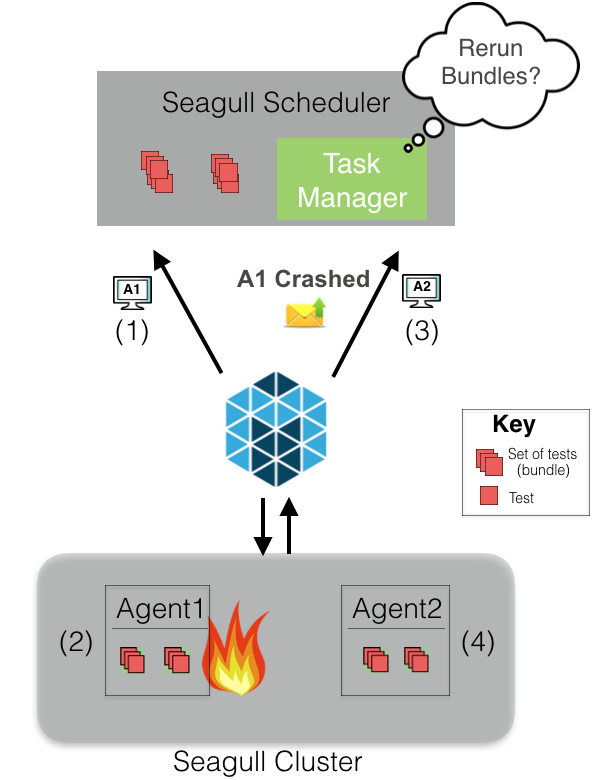
例如,假设一个调度器需要调度两个 bundle。Mesos 将代理(A1)的资源分配给调度器。假设调度器认为已经分配到足够的资源,那么两个 bundle 就会被安排在 A1 上。A1 因为某些原因发生崩溃,那么 Mesos 会让调度器知道 A1 已经崩溃了。调度器的任务管理器决定进行重试,或者直接取消任务。如果进行了重试,当 Mesos 提供了足够的资源时(比如 A2),那么 bundle 就会重新被安排执行。如果任务被取消,调度器会将这些 bundle 的测试用例标记为未执行。
6.Seagull UI 通过 Apollo 从 ES 上获取测试结果,并将它们加载到一个 UI 上,让开发人员可以看到结果。如果测试通过,就可以进行部署!
我们所谈论的规模是多大?
我们每天有 300 多个 seagull-run,高峰期每小时有 30 到 40 个。它们为此每天启动超过 200 万个 Docker 镜像。为了应付这些场景,我们的 Seagull 集群在高峰期需要差不多 1 万个 CPU 核心。
这种规模所带来的挑战
为了保持测试套件的及时性,特别是在高峰时期,我们需要确保 Seagull 集群里有数百个可用的实例。我们曾经使用过 AWS ASG 和 AWS On-Demand 实例,不过它们对于我们来说太昂贵了。
为了降低成本,我们开始使用一个叫作 FleetMiser 的内部工具来维护 Seagull 集群。FleetMiser 是一个自动扩展引擎,我们用它基于一些信号来扩展集群,比如当前集群的使用情况、管道里运行的工作负荷数量,等等。它有两个主要的组件。
- AWS Spot Fleet :AWS 的 Spot 实例比 On-Demand 实例要便宜,Spot Fleet 为使用 Spot 实例提供了简单易用的接口。
- 自动伸缩:我们对集群的使用是动态变化的,主要集中在太平洋时间 10:00 到 19:00,开发人员的主要工作都集中在这段时间。为了能够自动伸缩,FleetMiser 使用了集群的当前和历史数据。每天,Seagull 集群在 1500 个 CPU 核心到 10000 个 CPU 核心之间伸缩。
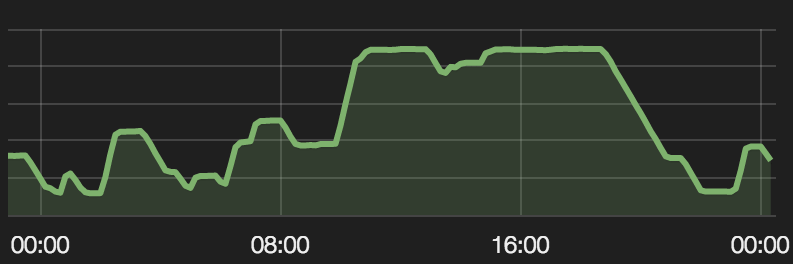
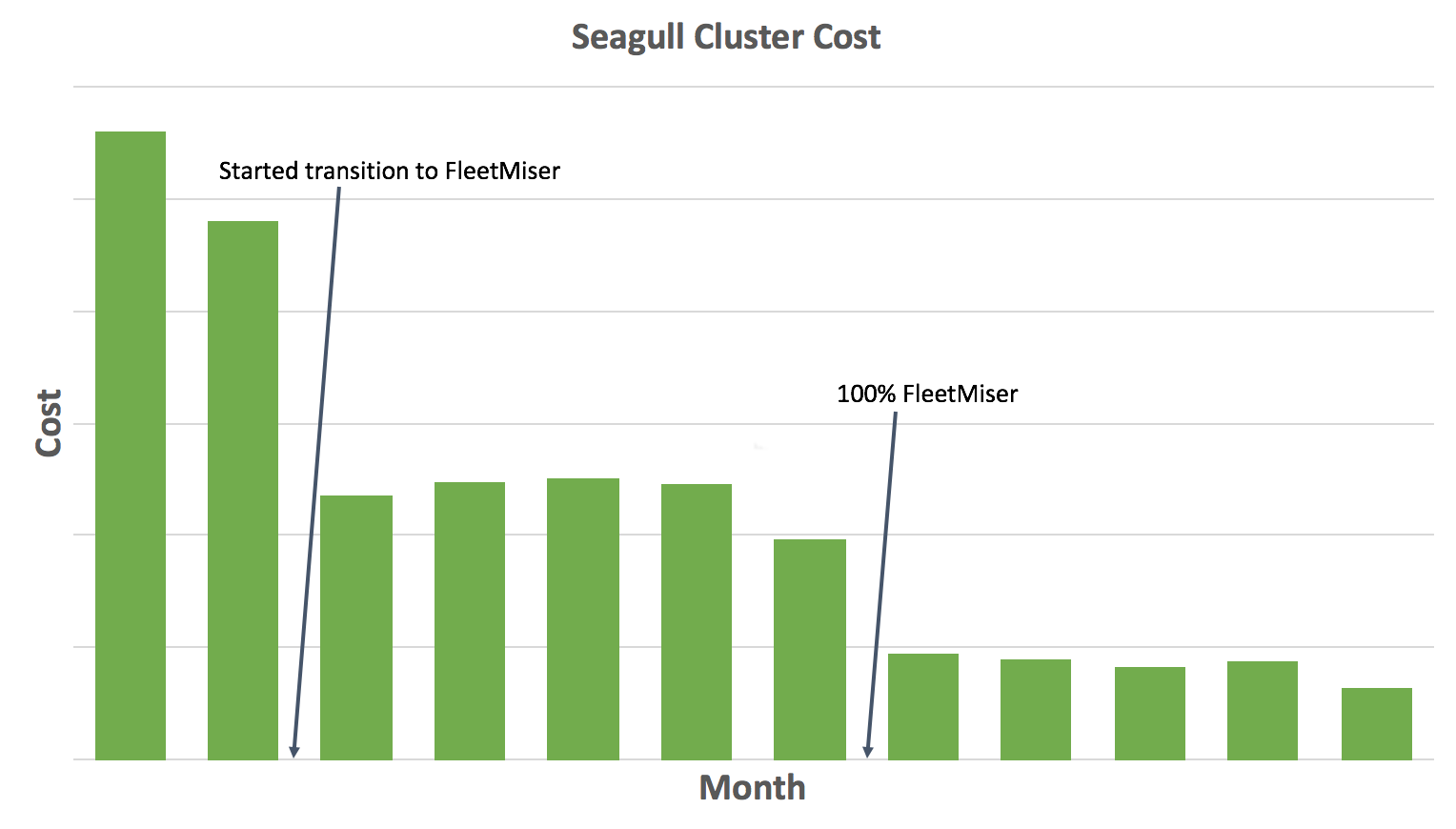
自动伸缩:几周前的容量数据
FleetMiser 为我们节省了 80% 的集群成本。而在那之前,我们的集群部署在 AWS On-Demand 实例上,无法进行自动伸缩。
我们已经达成了什么样的目标?
Seagull 将测试结果的时间从 2 天降低到 30 分钟,而且减少了大量的运行成本。我们的开发人员能够自信地提交代码,无需等待数个小时甚至数天来验证他们提交的变更没有造成任何破坏。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




