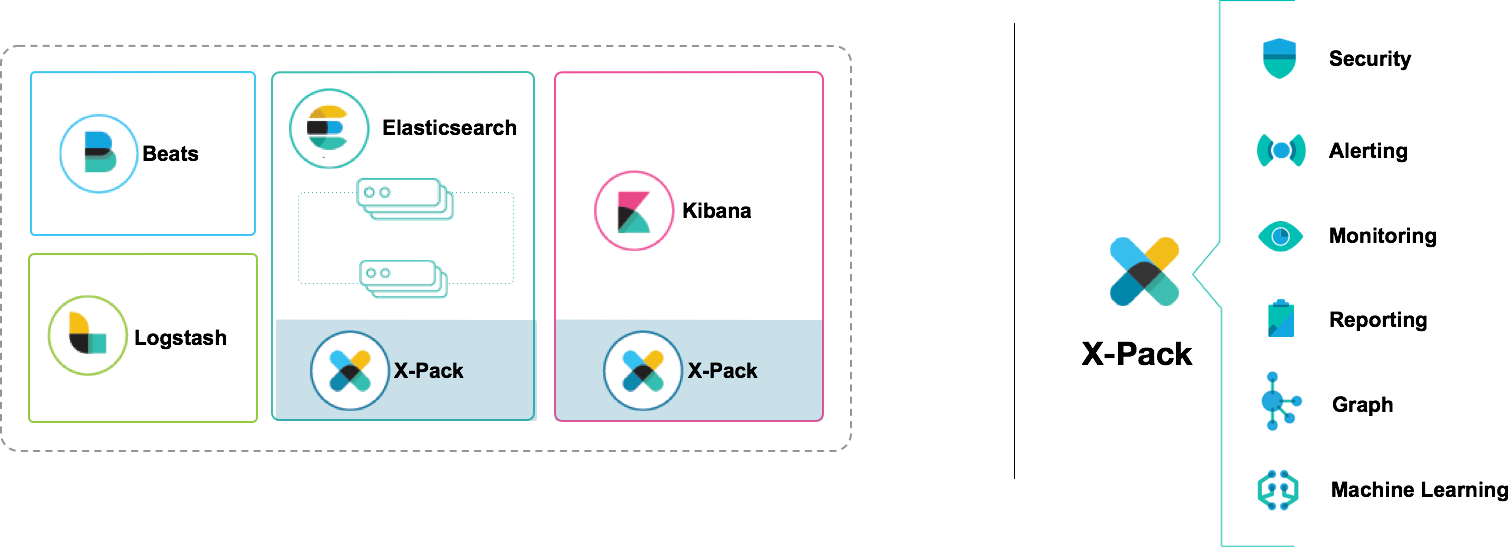
Elastic 今日在其官方博客,发布了最新版本的 Elastic Stack 5.4.0 Beta,其中最重要的新特性是对机器学习的支持。
机器学习正在渗透到各行各业,搜索领域也不例外。Elastic 今天发布的机器学习新特性,并非一蹴而就,而是源于去年的一桩收购案——2016 年 9 月 15 日, Elastic 宣布收购 Perlert 。Perlert 是一家创立于 2008 年的用户行为分析技术提供商,在无监督机器学习技术方面积累了丰富的实践经验。Elastic 在该文章中称经过 7 个月的努力,成功把 Perlert 的无监督机器学习技术集成到 Elastic Stack,并作为 X-Pack 的一员,在最新的 5.4.0 Beta 版本中发布。
下文翻译自 Elastic 官方博客的文章 Introducing Machine Learning for the Elastic Stack ,原作者为 Steve Dodson ,翻译已获得授权。
博客全文:
我们很荣幸地在今天发布首个支持机器学习特性的 Elastic Stack 版本,该特性位于 X-Pack 中。加入 Elastic 就如登上宇宙飞船(译者注:指 2016 年 9 月 Perlert 公司加入 Elastic),经过 7 个月的努力工作,我们激动地宣布 Perlert 机器学习技术现已全部集成到 Elastic Stack,并真诚地期待用户的反馈意见。
注:也别太过激动,请留意该功能尚处于 5.4.0 版本的 Beta 阶段。
关于机器学习
我们的目标在于,让用户通过工具从自己 Elasticsearch 数据中获取价值和洞察力,同时我们认为机器学习对于 Elasticsearch 中的搜索和分析能力来说是一个很自然的延伸。比如你可以在 Elasticsearch 的海量数据中实时查询用户“steve”的交易记录,或者通过聚合和可视化功能来展示销量 top10 的产品,或者交易量随时间的变化趋势。而现在,借助机器学习你能更进一步来分析,比如“有哪项服务的行为改变了吗?”或者“我们的主机上有异常进程在运行吗?”这些问题,要求使用机器学习技术所需的数据,来自动构建出主机或服务的行为模型。
但机器学习目前在软件业是过热概念之一,因为根本上来讲,就是一系列用于数据驱动预测、决策支持以及建模的算法和方法。因此消除这些噪声,来介绍下我们所做的具体事情显得更为重要。
时间序列数据的异常检测
今天发布的 X-Pack 机器学习特性,旨在通过无监督机器学习提供“时间序列数据异常检测”的能力。
未来我们计划增加更多的机器学习功能,但目前专注于,针对在 Elasticsearch 中存储时间序列数据,比如日志文件、应用和性能指标数据、网络流量或者金融 / 交易数据等的用户,提供附加价值。
示例 1——关键性能指标异常波动的自动告警
这项技术的最直接应用是,识别一个度量值或事件比率何时偏离了常规行为模式。比如,服务的响应时间是否显著增加?或者预期的网站访问用户数是否与往日同一时段明显不同?这类分析通常都会用到规则、阈值或简单统计模型。遗憾的是,这些简单方法对于实践中的数据来说都很低效,因为它们往往依赖不合理的统计假设(比如高斯分布),所以并不适用于趋势分析(长期或周期性的)或信号极易改变的情况。
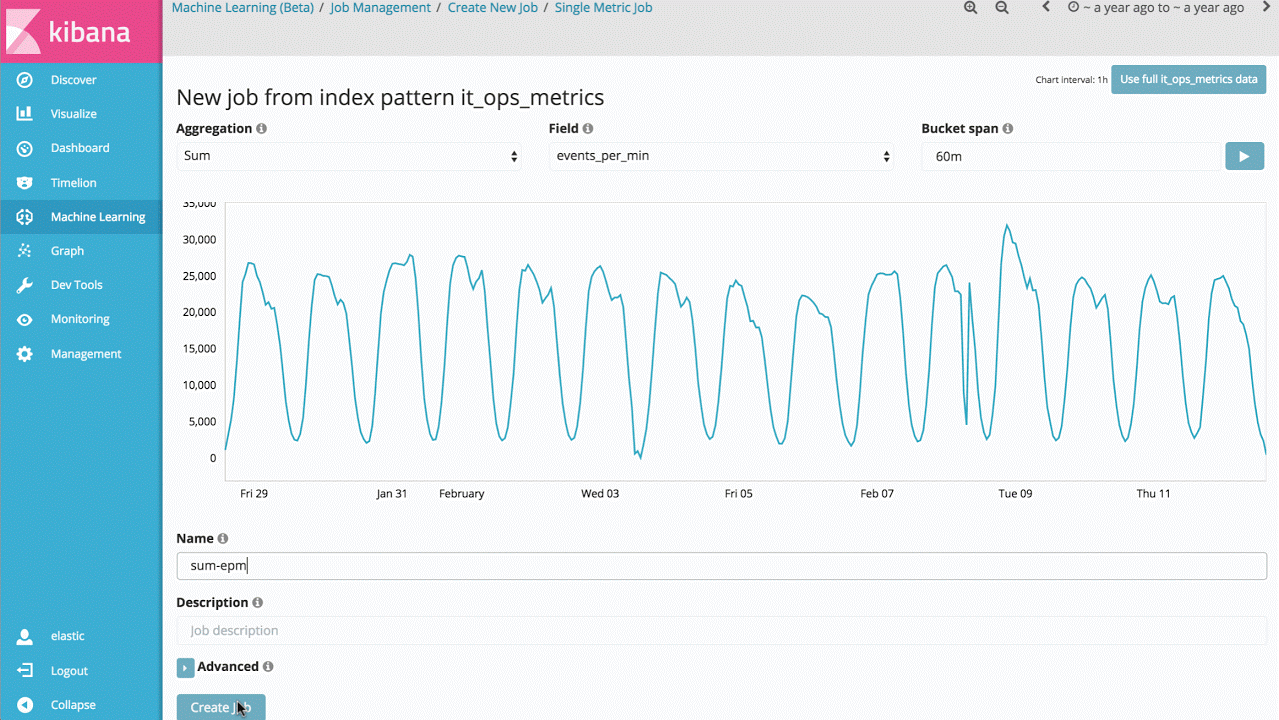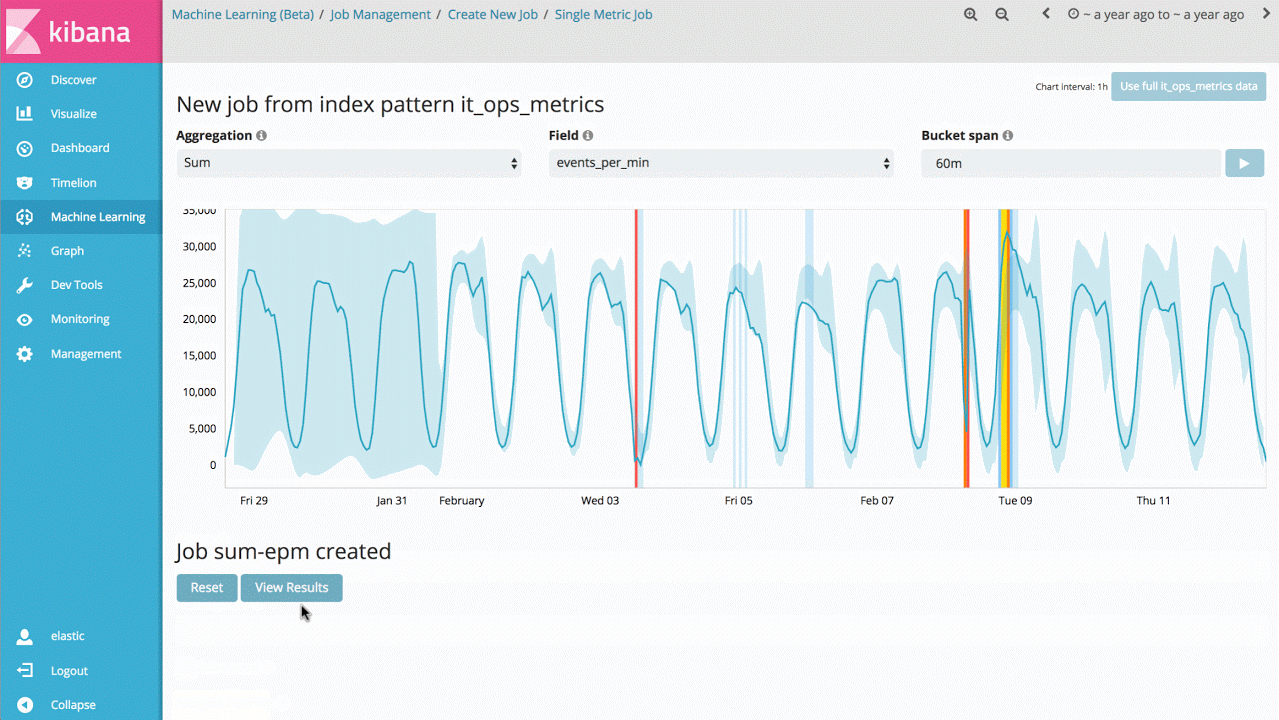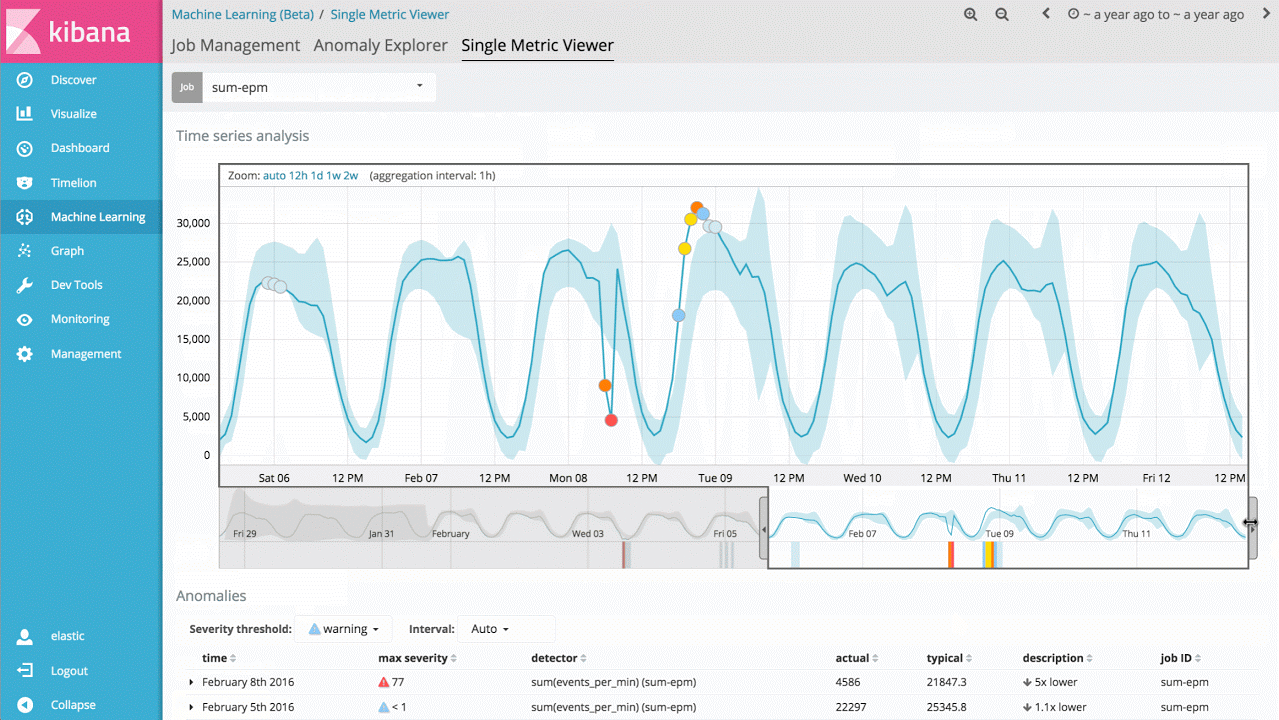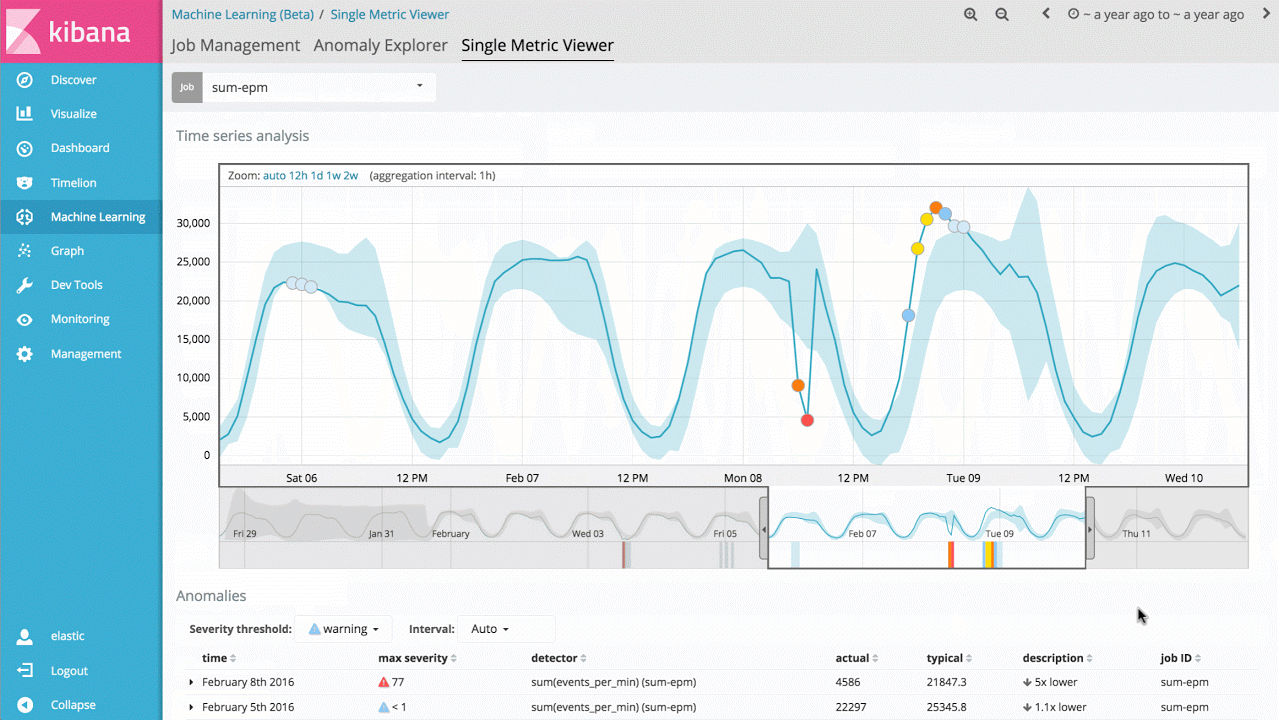
因此,对于机器学习特性第一个可以切入的,就是单指标作业,由此可以了解该产品如何学习正常模式,以及如何识别单变量时间序列数据中的异常模式。如果所发现的异常是有意义的,就可以持续地实时运行该分析,并在异常发生时告警。
虽然这看起来只是一个比较简单的应用案例,但产品背后却有着大量的无监督机器学习算法和统计模型,因此对任意信号都有鲁棒性和精确性。
为了在 Elasticsearch 集群中能更本地化地运行,我们对实现也做了优化,因此百万级的事件可以在秒级完成分析。
示例 2——数千指标的自动化追踪
机器学习产品能扩展到数十万指标和日志文件,所以下一步就是同时分析多个指标;可能会是一个主机相关的多个指标、一个数据库或应用的性能指标、或者多个主机的多个日志文件。这种情况下可以简单地分区分析,并把结果聚合到一个透视窗口中用于展示整个系统的异常。
假设有一个大型应用服务的响应耗时数据,就能简单地分析每个服务随时间的响应耗时变化,并识别单个服务的异常行为,同时也能提供整个系统的异常视图:
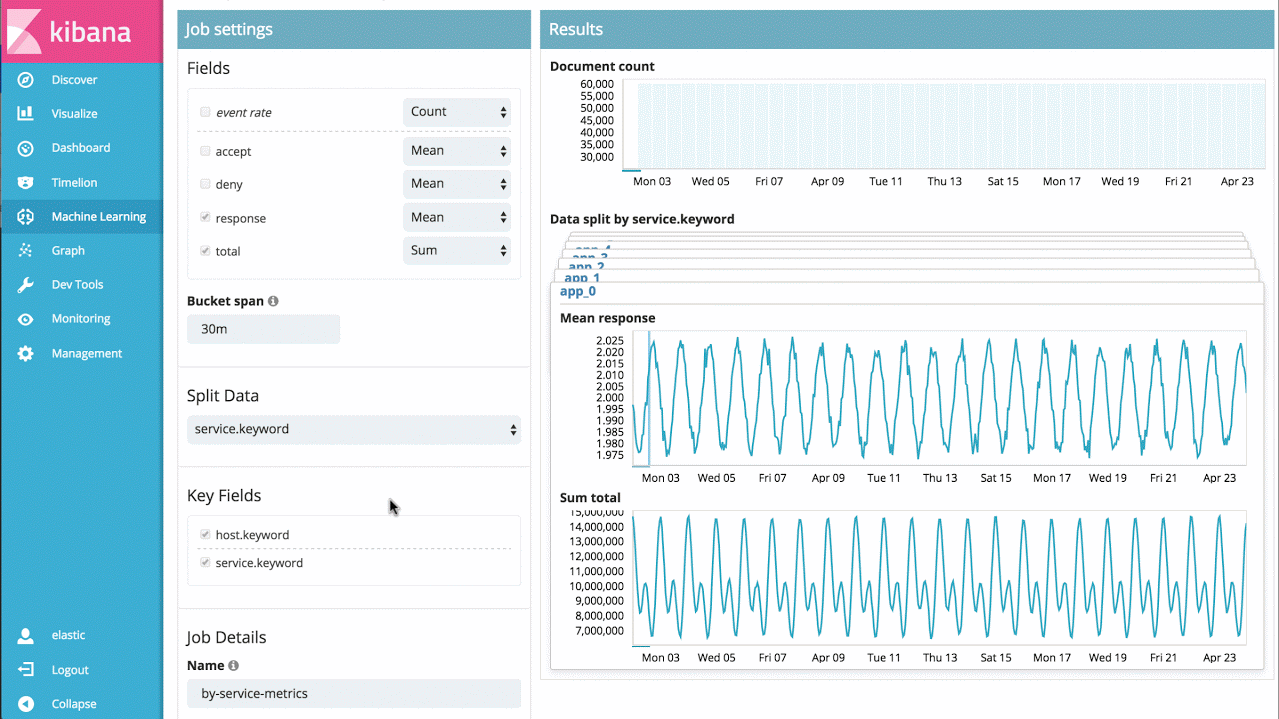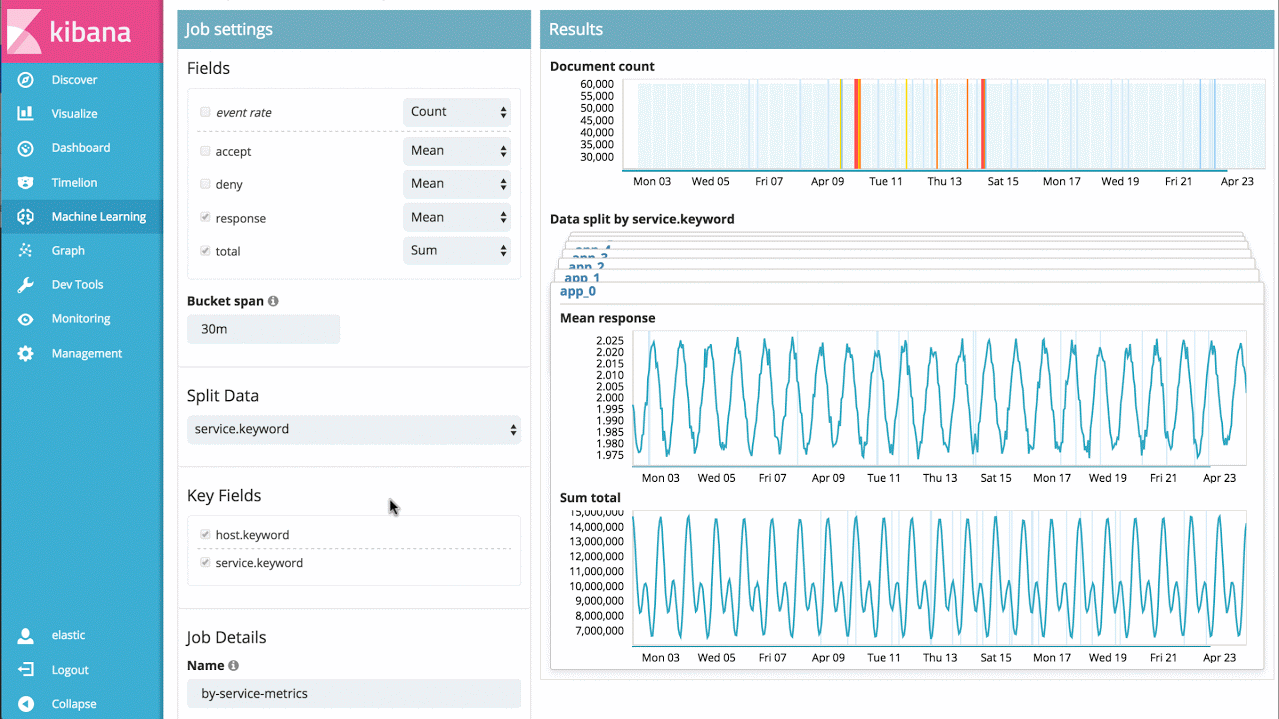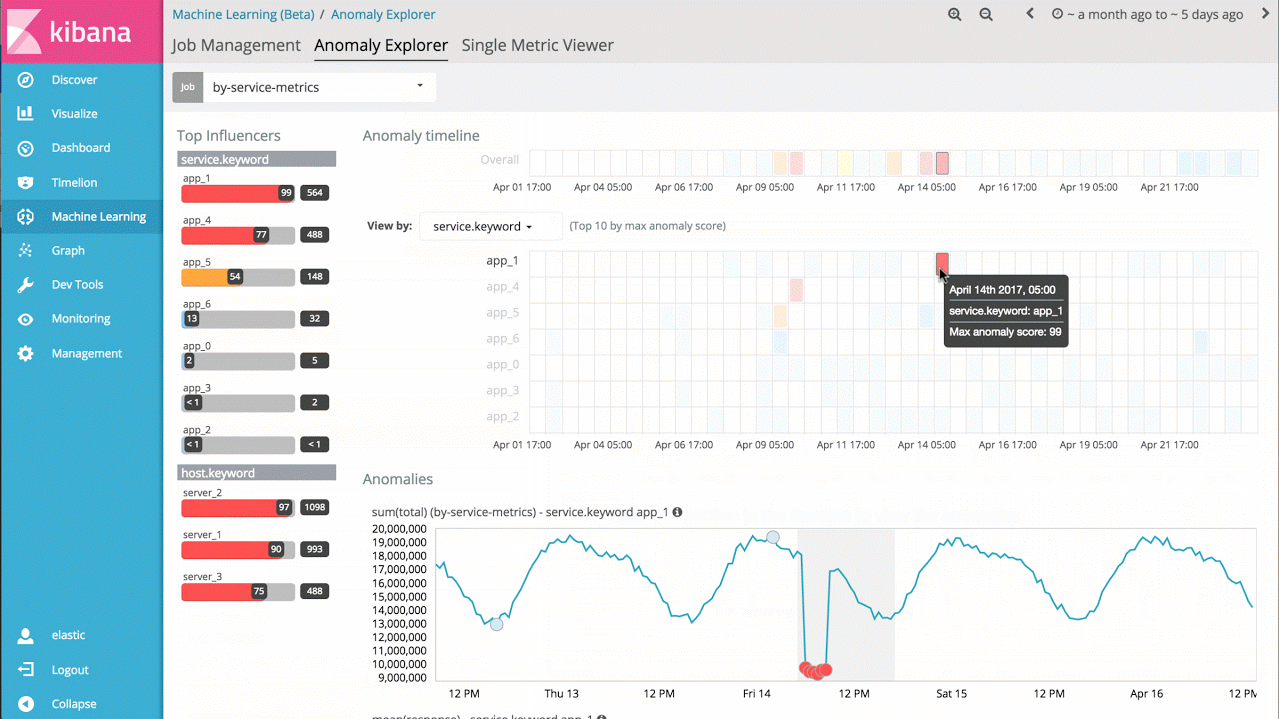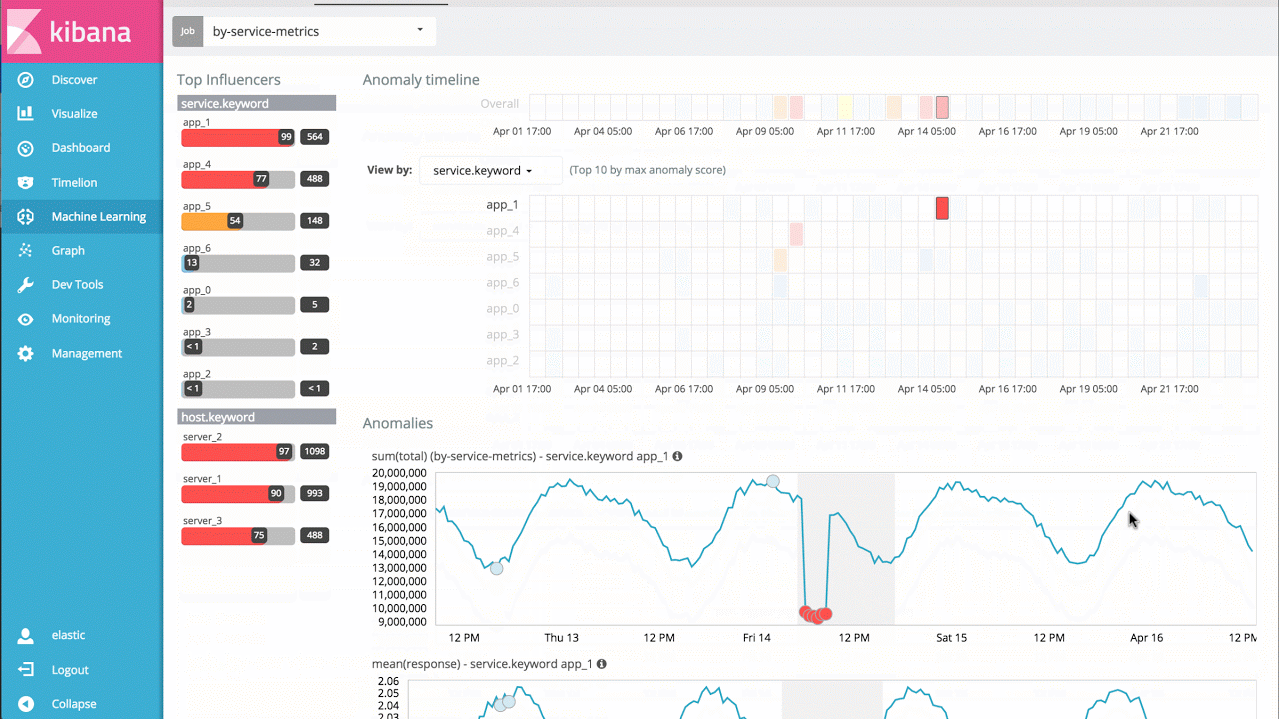
示例 3——高级作业
最后,还有大量的更高级方式来使用该产品。比如,如果想查找与人群相比有异常行为的用户、异常的 DNS 流量或者伦敦道路上的交通拥堵,高级作业提供了一种灵活的方式,来分析 Elasticsearch 中的任何时间序列数据。
与 Elastic Stack 集成
机器学习是作为 X-Pack 的一个特性发布的,这意味着安装了 X-Pack 之后,就可以利用机器学习特性来实时分析 Elasticsearch 中的时间序列数据。Elasticsearch 集群会自动化地分配和管理机器学习作业任务,基本上跟对待索引和分片一样;这也就意味着,机器学习作业可以从节点故障中快速恢复。从性能的角度,紧密集成意味着数据从来无需离开集群,我们能依赖 Elasticsearch 聚合功能显著地提升某些作业类型的性能。紧密集成的另一个好处是,可以从 Kibana 直接创建异常检测作业并查看结果。
因为数据能现场分析而无需离开集群,所以相对于集成 Elasticsearch 数据到外部数据科学工具,这种方式有着明显的性能和维护优势。随着我们在该领域开发的技术越来越多,这种架构的优势将会愈加明显。
了解最新版本 Elastic Stack: https://www.elastic.co/cn/
查看英文原文: Introducing Machine Learning for the Elastic Stack
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




