今天的人们使用智能手机拍摄的照片数量激增,这对传统的照片分类方式造成了不小的挑战。我们每个人整理自己手机中存储的海量照片尚且如此困难,对我们来说,要为所有人的照片定义一种更有序的分类方式无疑更是困难重重。
每天,人们会将数十亿张照片分享到 Facebook,想想你自己向下滚屏查找几天前发布的照片有多麻烦,如果要找几个月甚至几年前的照片呢?为了帮大家更容易找到自己的照片,Facebook 照片搜索团队使用机器学习技术深入了解照片内容,改善照片的搜索和获取过程。
我们的照片搜索功能基于一种名为 Unicorn 的内存和闪存索引系统构建,这种系统在设计上可以顺利搜索百亿至万亿级别的用户和其他实体。这套诞生于几年前的系统还驱动着能够理解社交图谱的 Graph Search 功能,以每天数十亿笔查询的强大能力为 Facebook 的多个组件提供着支撑。
Graph Search 的诞生是为了能根据不同社交图谱之间的关系获取相关对象,例如“所有住在旧金山的好友”。该功能的效果很不错,但如果要将查询约束在相关子集范围内,并按照相关性对结果进行排序或计分,进而提供最相关的结果,这种操作中该功能的效果很一般。为了继续完善这种技术,照片搜索团队使用深度神经网络,通过照片中的可视内容和可查找文字改善了图片搜索结果的准确性。
关于照片,搜索功能需要了解些什么
虽然 Imagenet Challenge 等竞赛中,图片识别技术的演示已经获得了非常低的错误率,但以 Facebook 的规模来说,理解照片内容是个很难达成的目标。好在相关应用领域的研究已经为我们提供了最先进的深度学习技术,足以在大范围内处理数十亿张照片,从中提取出可搜索的语义学含义。我们会使用一种名为图片理解引擎的分布式实时系统,分析处理发布到 Facebook 且公开展示的每张照片。
图片理解引擎是一种深度神经网络,其中包含数百万种可学习参数。该引擎以先进的深度残差网络(Deep Residual Network) 为基础,使用上千万张带标注照片进行了训练,可自动预测一系列概念,包括场景、物体、动物、景点、着装等。我们可以提前训练模型并将有用的信息存起来,进而以低延迟响应回应用户查询。
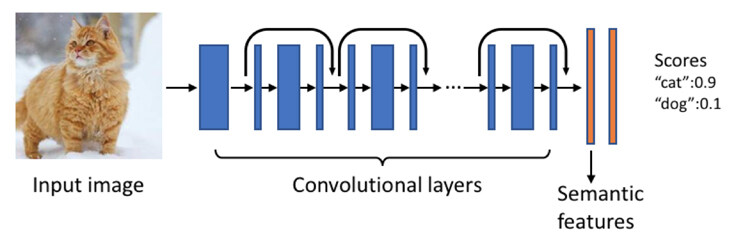
这个图片理解引擎为语义特征生成的高维浮点向量需要进行索引和搜索,但以Facebook 的规模来说,这是一种非常繁重的计算密集型任务。通过使用迭代量化和局部敏感哈希技术,该功能可进一步压缩出数量更少,但依然足以代表大部分语义的“位”。这些紧凑的“位”信息将直接嵌入照片中,借此可直接对照片进行评级、检索、去重等操作。搜索查询过程中,可通过嵌入的信息调整结果的展示顺序。这种技术与文档搜索和检索过程中使用的技术极为类似。Unicorn 最初诞生时包含适用于深度神经网络层的多种不同算法,这些算法都是针对大规模图片集的搜索开发而来的。Unicorn 可以用对象标签和嵌入语义创建搜索查询所需的索引。目前我们正在开发该技术的新版本,希望能将这种紧凑嵌入的信息用于低延迟检索。
在建模过程中使用标签和嵌入物
考虑到Facebook 的规模以及用户对快速响应查询的预期,我们无法对整个照片库使用过于复杂的评级模型。因此为标签和嵌入物使用了一种相关性模型,该模型可估算相关性并以极低的延迟提供查询结果。
概念相关性
这个相关性是通过丰富的查询,以及使用相似性函数对比概念集得出的照片概念信号进行评估的。例如,与照片查询中所用的“中央公园”概念直接相关的查询概念,可将与这一话题有关的照片放在首位,并从结果中隐藏所有“离题”的照片。
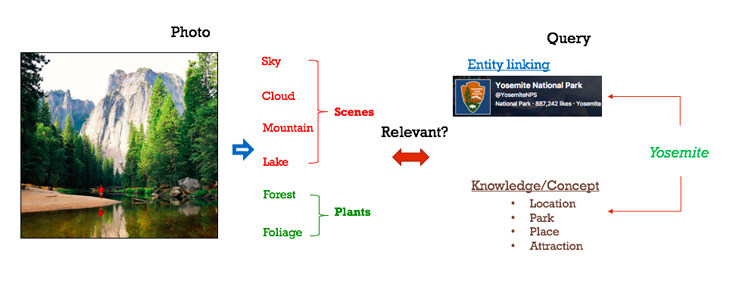
嵌入物相关性
通常来说,直接衡量查询与结果之间的概念关联性,这种做法不足以准确地预测相关性。我们创建的相关性模型会使用多模态学习(Multimodal learning) 技术了解查询和图片之间的联合嵌入关系。
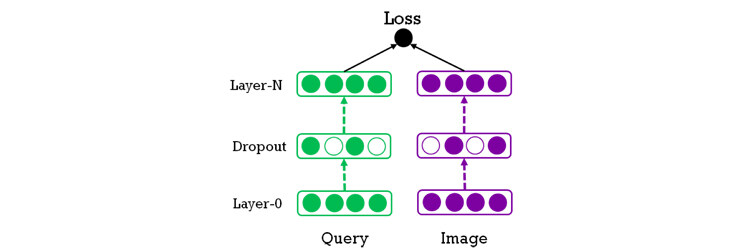
该模型的输入端为查询的嵌入向量和照片结果,而训练目的在于将分类损失降至最低。每个向量将放在一起训练和处理,这一过程会使用多层次的深度神经网络生成一个二进制信号,结果为正意味着匹配,结果为负意味着不匹配。查询和照片的输入向量分别由各自的网络生成,每个网络可能包含不同数量的层。这种网络可以通过嵌入层的参数进行训练并调优。
嵌入评级损失
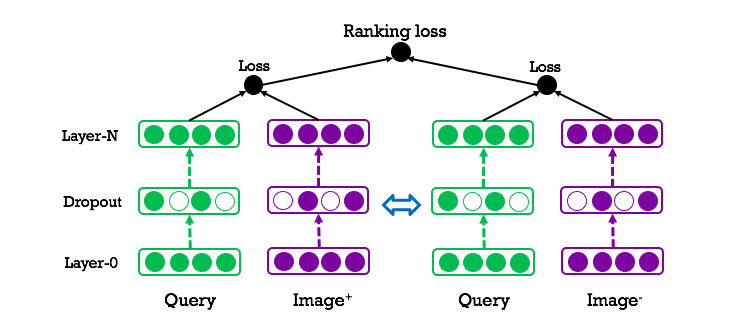
上文介绍的这种确定查询和照片之间相关性的方法可以用公式表示为一种分类问题。然而评级的主要目标在于确定照片搜索结果中一系列照片的最佳排序。因此我们在分类公式的基础上使用评级损失(Ranking loss) 进行训练,同时为同一个查询生成相关和不相关结果对。
如下图所示,模型右侧部分是左侧部分的深层复制(Deep copy),也就是说,他们共享了相同的网络结构和参数。在训练过程中,我们会将查询与两种结果分别放入模型的左侧和右侧组件中。对于每个查询,相符图片的评级会高于不相符图片。这种训练方式大幅改善了评级质量。
将对查询的理解应用给照片搜索
Unicorn 的照片语料以及图片理解引擎所应用的嵌入物均是可搜索的。如果应用于嵌入物的查询语义生成了更高概率的相关性,除了用于获取照片的索引,查询与检索之间的其他位图会被打断。理解查询语义过程中所使用的重要信号包括:
查询意图 (Query intents)建议了需要检索哪类场景的照片。例如一个意在检索动物照片的查询需要展示以动物为主题的照片。
语法分析 (Syntactic analysis)帮助我们理解查询语句的语法构造、词类词性、句法关系,以及语义。搜索查询通常无法识别书面语的语法,而这方面现有的解析程序效果并不好。因此我们使用了最先进的技术,对语言标记器(Speech tagger) 中神经网络部分进行有关搜索查询的训练。
实体链接(Entity linking)帮助我们找出有关特定概念的照片,通常会将结果以页面的形式呈现,例如不同的地点或电视节目。
重写查询知识以提取由查询的语义诠释提供的概念。概念不仅可以扩展查询的含义,而且可以弥补查询和结果之间不同词汇造成的差异。
查询嵌入物,这是一种用于代表查询本身的连续向量空间。该技术可在对词汇进行word2vec 向量呈现的基础上通过迁移学习(Transfer learning) 进行学习,借此将类似的查询映射至就近点。
领域和查询重写
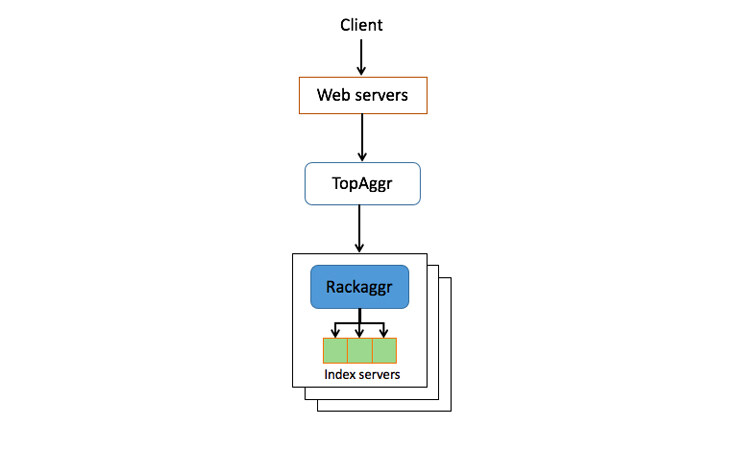
当某人输入查询按下搜索键,会生成一个请求并发送到我们的服务器。该请求首先到达Web 层,在这里会收集有关该查询的不同上下文信息。随后查询以及相关上下文会被发送至一个顶级聚合器层,在这里查询会被重写为一个s- 表达式,随后描述该如何从索引服务器获取一系列文档。
根据查询意图,会由一个触发器机制使用神经网络模型决定相关联的领域(Vertical),例如新闻、照片,或视频,这是为了尽可能避免针对相关性较低的领域执行不必要的处理任务。举例来说,如果某人查询“有趣的猫咪”,那么这个意图很明显更希望看到照片领域的结果,此时我们会从搜索结果中排除掉新闻这个领域。
如果查询“万圣节”,此时将同时触发有关公开照片及好友的万圣节变装照片的意图,此时将同时搜索公开和社交圈照片两个领域,进而可同时返回搜索者的好友所分享的照片,以及评级为相关的所有公开照片。此时需要进行两个独立的请求,因为社交照片是高度个性化的,需要进行单独的检索和计分。为了保护照片隐私,我们会对搜索结果应用Facebook 整个系统都在使用的隐私控制机制。下图演示了一个上端为“社交”,下端为“公开”的模块。
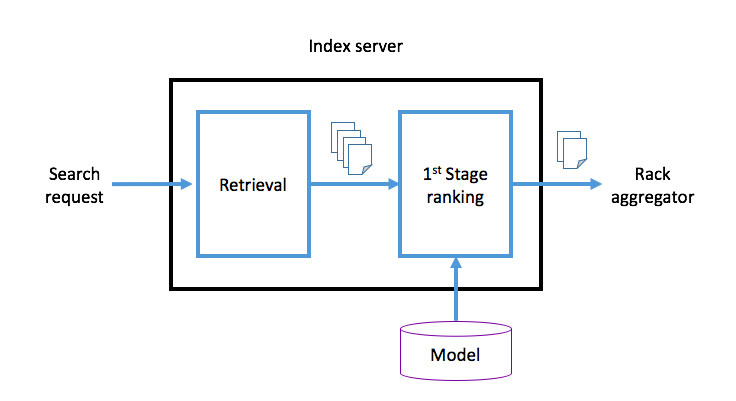
第一阶段评级
当索引服务器根据s- 表达式获取到所需文档后,会交给经过机器学习训练的第一阶段评级器处理。随后分数最高,Top M 文档会被发送至Rack aggregator 层,借此对所获得的全部文档进行一定程度的合并,随后将Top N 结果返回至顶级聚合器层。第一阶段评级的主要目的是确保返回至Rack aggregator 的文档与查询依然保持一定的相关性。例如,在查询“狗”时,包含狗的照片无疑会比不包含狗的照片获得更高评级。为了能以毫秒级的速度提供相关照片,我们还对整个复杂的检索和评级阶段的延迟进行了优化。
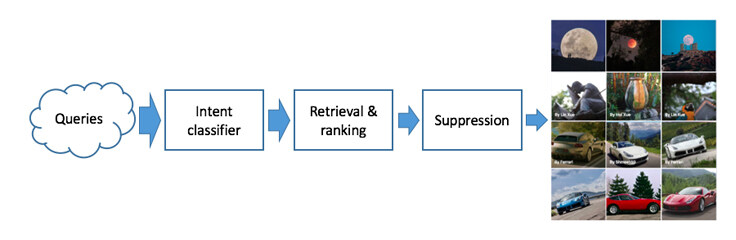
第二阶段的二次评级
评级后的文档返回顶级聚合器后,会进行另一轮的信号计算、去重和评级。信号描述了整个结果分布情况的计算结果,借此可发现不符的结果。随后会使用图片指纹对视觉方面类似的文档进行去重。随后会通过深度神经网络进行计分和评级,借此生成最终的照片排序结果。评级之后的照片集(也叫做“模块”)会被发送到结果页面的UI 中显示出来。
针对照片搜索优化相关性评级
对查询与照片,以及照片与查询之间的相关性进行评估,这是照片搜索团队所面临最核心的问题,并且已经远远超出了基于文本的查询重写和匹配技术范畴。为此我们需要进一步全面理解查询、照片作者、照片附带贴文,以及照片中的可视内容。先进的相关性模型通常需要包含顶尖的评级、自然语言处理,以及计算机视觉等技术,借此才能提供相关性更高的搜索结果,为我们塑造一种新颖的图片分类系统,在大规模范围内更快速提供相关性更高的搜索结果。
阅读英文原文: Under the hood: Photo Search
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




