有没有这样的经历,也许你保存了某篇文章里的一张图片,忽然有一天你想要重读这篇文章,结果你又不能用手上的图片反向检索文章。事实上直到最近 1、2 年,很多搜索引擎采用的依然是文字驱动技术,而不是通过图像搜索。换言之,用户能不能检索出自己想要的东西,取决于这个东西在搜索引擎内部是否被分类标记,或者是否有准确的文字描述。
最近一两年是人工智能的启动元年, 人工智能已经推动计算机视觉技术达到了一个新的高度。在这个高度,业界的目标是在像素级理解图像,而不是之前的需要文字描述、分类等方式协助。这种进步帮助我们的系统认识图像里面是什么内容,图像里面是什么场景,例如是不是一个有名的旅游胜地。反过来看,这种技术可以更好地为视障人士提供帮助,帮助他们更好地使用搜索引擎搜索图像和视频。通过 Joaquin Quiñonero Candela 的文章《Building scalable systems to understand content》,我们可以大概了解一下。
构建人工智能工厂
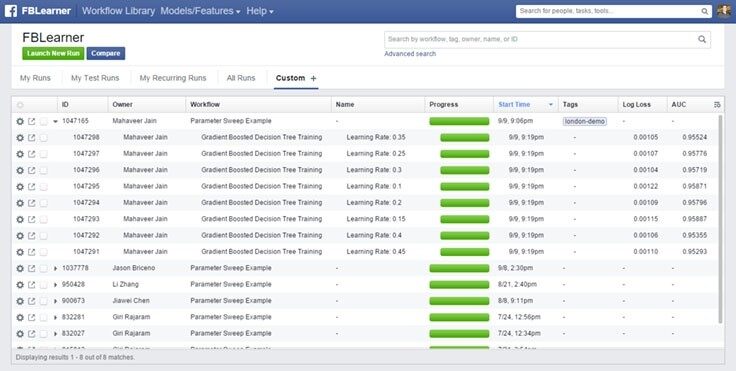
为了让 AI(人工智能)更容易地进入 Facebook 的软件大家庭,Facebook 管理层认为需要引入一个通用的平台,这个平台需要可以支持工程师自己控制集群规模,最终引入的平台叫做 FBLearner Flow。有了 FBLearner Flow 平台之后,Facebook 的工程师在运行、调试机器学习程序的时候不用再担心集群负载海量实时任务的业务负担了。Facebook 目前在 FBLearner Flow 平台上平均每个月需要运行 120 万个 AI 任务,这个数字是 1 年以前的 6 倍。
Facebook 还在不断地加强 FBLearner Flow 平台,包括提供自动化处理机器学习的工具、构建专用内容理解引擎等。此外,Facebook 也允许工程师通过编写多机运行的训练代码方式构建整个生态环境,这样的运行环境和代码可以被全公司的工程师复用。
计算机视觉平台
FBLearner Flow 平台最初起源于 Facebook 人工智能研究的一个小型研究项目,当 FBLearner Flow 平台达到了生产环境要求的时候,FBLearner Flow 平台和整个小组成员已经转换为应用机器学习团队,并作为 FaceBook 计算机视觉团队的分析引擎。
Lumos 构建于 FBLearner Flow 平台之上,它是专用于图像和视频的学习平台。Lumos 很容易使用,如果一个 Facebook 工程师想要使用 Lumos 训练和部署一个新的模型,他不需要接受针对深度学习或者计算机视觉技术的培训。Lumos 平台一直都在不断提升,无论是通过标定数据,还是通过 Facebook 各种应用程序提供的注释数据。
深度学习的进步让 Facebook 在图像分类领域有了重大提升,比如“图像中有什么?”和“目标在哪里?”这样的问题可以通过系统回答,而且精度较之前提高了很多。Facebook 通过在给定图像上检测和分割对象的设计方案加强搜索准确度。
让我们想象一下整个流程。这些技术被应用在 Facebook,图像可以穿过深度学习引擎,穿越过程中分割图像并且识别对象和场景,进而可以让图像本身附带更多的意义。这个过程为 Facebook 的产品或者服务提供大量可以使用的数据。Facebook 的几十个小组已经在 Lumos 上通过训练和部署了超过 200 个视觉模型,针对例如不良内容检测、反垃圾邮件、自动图像字母等等目的。从 Facebook 的连通性实验室到无障碍团队都在使用这些应用程序。
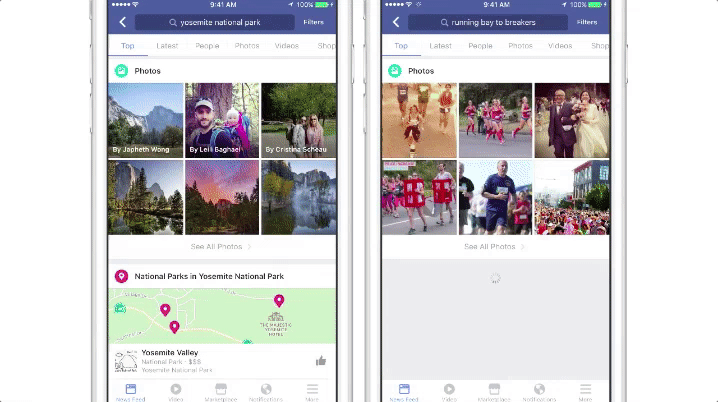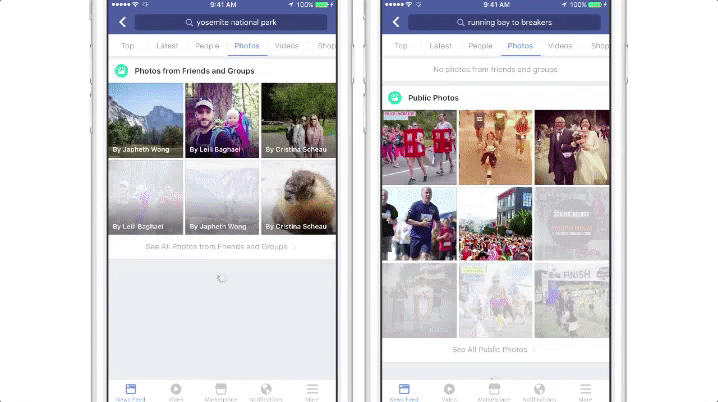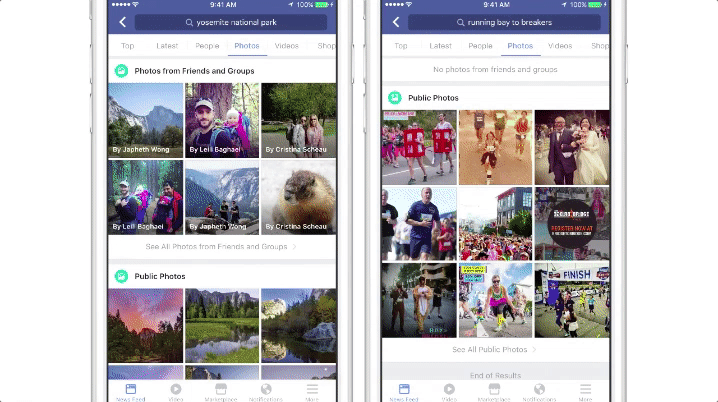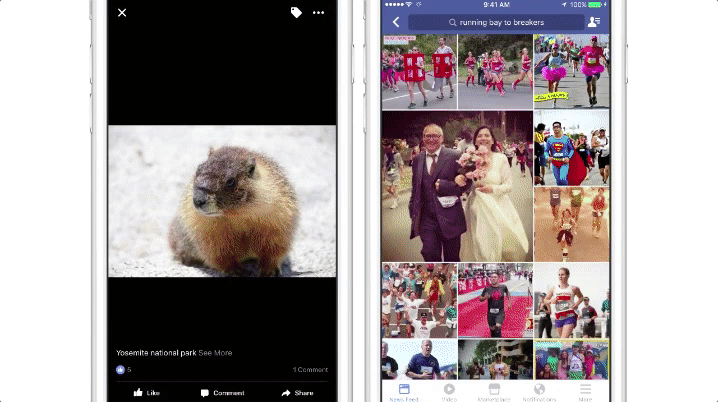
提升内容
Facebook 目前正在研究将图像识别技术应用到提升自动高亮图像文字描述(AAT),这项技术可以帮助视觉障碍人士理解图像内容。
之前的一段时间,Facebook 技术只能描述图像当中的对象。2017 年 2 月 2 日,Facebook 宣布增加了一组 12 个动作,图像描述对应可以增加类似于“走路的人”、“跳舞的人”、“骑马的人”,以及“弹奏乐器的人”等等。
AAT 的这次更新在两个部分执行,通过 Lumos 实现快速、可扩展的迭代更新。由于 Facebook 应用里面有相当多的图像包含了人类,所以 Facebook 着重提供针对人的自动描述。人工智能团队从 Facebook 应用上搜索了 13 万张包含人的图片(用户完全公开的图片)。标定人员需要假定自己在像视觉障碍人士解释图片的内容,通过一句话方式描述图片。然后 Facebook 利用这些注释建立一个机器学习模型,支持推断出图片中人的动作,进而用于 AAT 功能。
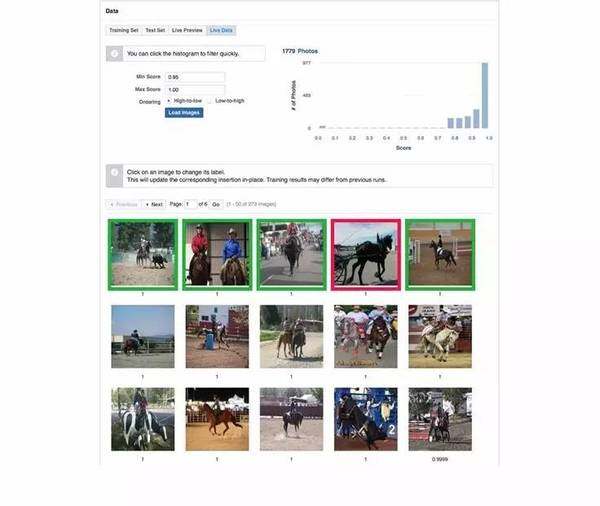
Lumos 允许这个任务快速迭代,让另一个任务通过接口使用前一次训练模型的标记。例如,如果我们正在训练“骑马的人”分类,想要去增加包括马的图片(没人骑的马),开发人员可以使用模型的一部分标定示例去学习是否图片里面有一匹马。
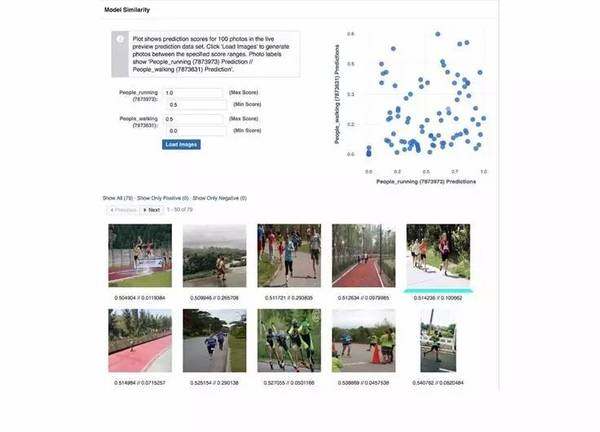
Lumos 允许通过检索和聚类相结合的方式生成训练数据。给定一组标签或搜索术语,Lumos 平台可以检索互联网上的图像的一小部分,找到匹配标签的图像。这些图像通过语义集合方式更快地分类标签,Lumos 用户选择按照用户用例对样本进行负面或者正面的注解分类,无论是在一个大规模数据集级别或者是针对数据集内部的每一张图片,都可以这样注释。这种做法可以帮助一个有初始数据集的分类任务进一步扩散,通过迭代方式训练并获得更高的精确度 / 召回分类。
AAT 应用对于 Facebook 来说至关重要,因为它解决了 Facebook 视觉障碍用户的使用问题,业界也有其他的应用程序尝试提供类似的方式解决问题,但是更多地把精力放在了搜索参数多样性上面,而不是人工智能领域。
深入理解
Facebook 宣称他们的搜索系统可以通过大量的信息以及相关图像,利用图像的理解进行快速排序。换句话说,比如我们正在搜索“黑色衬衫照片”,Facebook 系统可以自我确定是否图像中存在黑色衬衫,即便图像上没有标签信息。这些工作是通过图像分类器完成的。
为了理解图像中的内容,Facebook 团队使用了尖端的深度学习技术,使用该技术学习几十亿的图像数据,弄清楚这些图像的原始语义。
团队为了更好地对图像进行分类,使用以下几点技术:
- 对象识别:图片识别模型的底层是一个带有数以百万计学习参数的深度神经网络。它构建于最先进的深度残差网络之上,使用数千万带有标签的图像训练对象识别。它可以自动预测一系列丰富的语义,包括场景(例如花园)、对象(例如汽车)、动物(例如企鹅)、地点和景点(例如金门大桥),以及穿戴内容(例如围巾)。
- 图像嵌入:这个特性也会生成高层次的语义特征,它是深度神经网络最后几层的输出的量化版本。这些丰富的信息对于提炼图像搜索结果很有用。
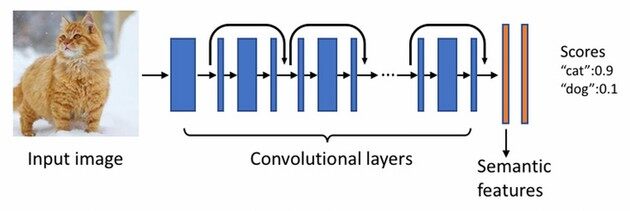
原始语义特征是高维浮点数向量,特别是当工程师不得不索引很多图片的时候,它使用了大量的存储索引。通过利用量化技术,这些特征被进一步压缩成几个 Bit,这种情况下依然可以保留大部分的语义。压缩成 Bit 级别的图片可以被直接用来作为搜索引擎排名、检索。
实现这种目标的一种方式是从图像中提取出预测的概念和类别,然后解析搜索查询并连接到实体和提取物,进而在两组概念之间使用相似性函数确定相关性。
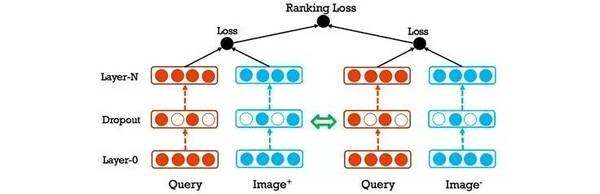
对于 Facebook 团队来说这是一个好的开端,但是 Facebook 并没有止步于预测图像分类,他们进一步使用了查询和图像联合嵌入方式,动态提升准确率和查全率。
Facebook 采用这种方式从多方面解决排名问题。此外,Facebook 也在图像之间使用了一种相似性测量办法,确保图像搜索结果多样性。
后续计划
Facebook 团队确实做了大量的工作,将 FBLearner Flow 平台纳入到了生产环境使用。Facebook 团队表态还有很长的路要走,目前仅仅触及了自服务式计算机视觉平台的皮毛。未来将会利用 FBLearner Flow 平台建立训练更多的模型,用于 Facebook 各个产品领域。
相关知识
- 机器学习与数据挖掘的区别
不管是数据挖掘,还是机器学习,都是以统计学为基础。统计学着重于数据的收集、组织、分析和解释,可以分为描述性统计学和推断统计学。描述性统计学注重的是对数据整理与分析,得出数据的分布状态、数字特征和随即变量之间的关系进行估计和描述,可以细分为数据的集中、离散和相关性分析。推断统计学侧重于通过样本数据推断总体。数据挖掘在通过算法得到的结果上,采用描述性统计学解释问题。而机器学习则是侧重于通过推断统计学来实现自学习。 - Deep Neural NetWork(深度神经网络)
2006 年,Hinton 利用预训练方法缓解了局部最优解问题,将隐含层推动到了 7 层(参考论文:Hinton G E,Salakhutdinov R R. Reducing the Dimensionality of Data with Neural NetWorks[J].Science,2006),神经网络真正意义上有了“深度”,由此揭开了深度学习的热潮。这里的“深度”并没有固定的定义,在语音识别中 4 层网络就能够被认为是“较深的”,而在图像识别中 20 层以上的网络屡见不鲜。为了克服梯度消失,ReLU、maxout 等传输函数代替了 sigmoid,形成了如今 DNN 的基本形式。单从结构上来说,全连接的 DNN 和多层感知机是没有任何区别的。值得一提的是,高速公路网络(Hignway Network)和深度残差学习(Deep Residual Learning)进一步避免了梯度弥散问题,网络成熟达到了前所未有的一百多层。 - Deep Residual Network(深度残差网络)
它的主要思想是在标准的前馈卷积网络上,加一个跳跃绕过一些层的连接。每绕过一层就产生一个残差块(Residual Block),卷基层预测加输入张量的残差。
感谢刘志勇对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




