
Trent McConaghy 是一位资深的 AI 研究员,从上世纪 90 年代开始从事 AI 方面的研究。截止到 2016 年年底,Trent 已经在相关领域发布过 35 篇论文、出版过 2 本书籍、注册过 20 项专利、并先后创办过 3 家公司。2013 年的一天,当时正为比特币技术狂热的 Trent 跟他的艺术家夫人 Masha 在柏林逛了一次画展,在参观回家后的闲聊中,两人展开了一个问题:区块链技术能够应用到艺术品上吗?我们能否以获取比特币的方式去获取一件艺术品的数码版本,同时保护艺术家对该作品的版权?
Trent 由此投身区块链创业,创建了 ascribe 公司。由于比特币的区块链实现方式限制了每秒最多能够处理的交易数量,无法满足 ascribe 对可扩展性方面的要求,Trent 又发起了 BigchainDB 项目,成立了 BigchainDB 公司和 IP 数据共享组织 IPDB 。
从 2015 年到 2016 年,Trent 在 PyData 、 Blockchain meetup 、 Machine Learning Group 等各种活动上活跃分享其在区块链与 AI 方面的思考,并在Medium 上撰写了大量文章。其中有几篇文章重点描述了AI 技术与区块链技术之间将可能有怎样的互补,内容非常精彩。本文对这些内容做一个简单的导读,希望能对大家有所帮助。
AI DAO 的构想
2016 年 6 月 18 日,正是 The DAO 项目处于风口浪尖的时候,Trent 在这一天发布了这篇有关 AI DAOs 的文章,后续又发布了第二篇和第三篇。
我在十岁那年读到了一本描述 AI 的书,从此不能自拔。后来,我用了将近二十年的时间投入到专业的 AI 研究工作当中。三年前,我从 AI 的世界走了出来,进入到一个同样重要的新世界:去中心化。现在,这两个世界很快就要重叠。
Trent 认为“去中心化”技术的发展将经历五次浪潮:
- 比特币
- 区块链
- 智能合约
- DAO——去中心化的自动化组织 Decentralized Autonomous Organizations
- AI DAO
DAO 是一种可以自动运行在去中心化基础架构上的计算进程,具有资源管理的能力。
比特币网络是 DAO。以太坊网络是 DAO。DAO 上面还可以跑其他 DAO,比如 The DAO 就跑在以太坊上。
DAO 是一个脚本,平时就坐在那里,等待某个交易来触发运行。
Trent 定义的 AI DAO 具备如下特性:
- 访问资源的能力
- 征用更多资源的能力
- 拒绝人为干涉的能力
而这可能通过三种途径来实现:
- 将智能合约的边缘执行单元交给 AI(自动化投票)
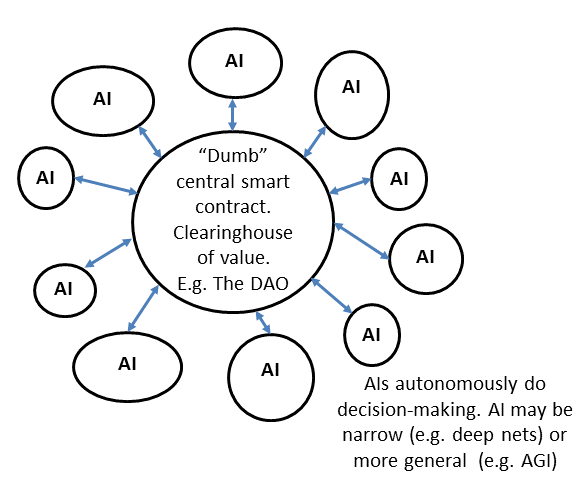
- 将智能合约的中心交给 AI(自动化反馈控制系统)
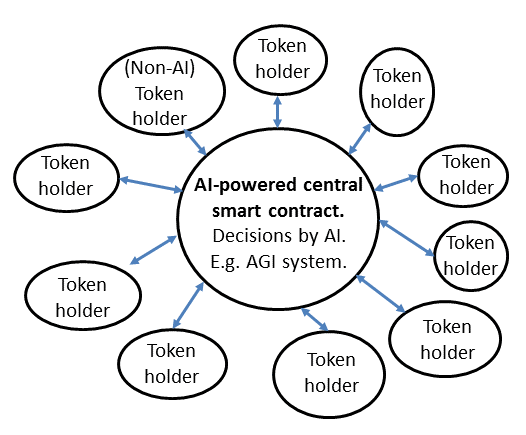
- 从集群中自动涌现出 AI 的复杂性
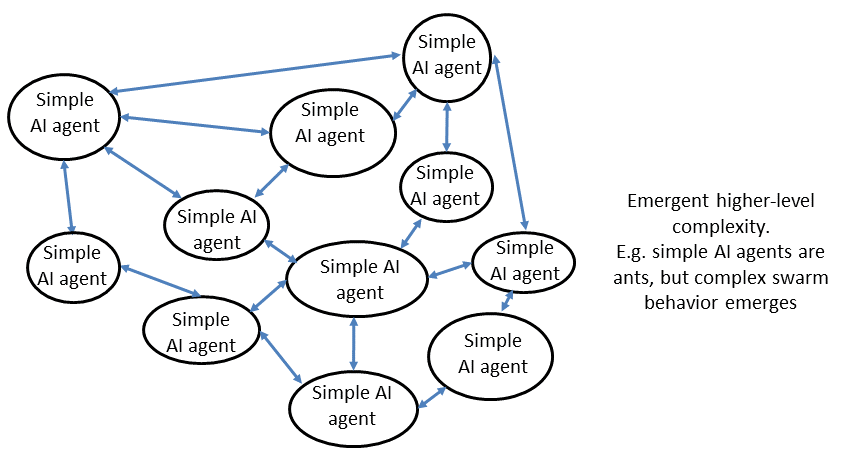
AI DAO 会更强大,也会更不可控。在系列的第二篇文章里,Trent 举了个例子:想象一个 The ArtDAO,其智能合约是这样运作的:
- 节点上运行了一个 AI 画图引擎,自动生成一张有艺术感的图片(相关的实现已经有很多,可参考这篇文章)
- 节点自动去 ascribe 给自己生成的图片注册一个著作权(虽然今天的法律未必会保护机器人的著作权法人权益)
- 节点在 ascribe 上创作该图片的不同版本,比如木刻效果或者浮雕效果的
- 节点把这些各种版本的图拿到市场上卖,比如 Getty、Hopify 或者 OpenBazaar
- 如果有买家想要这些图片的二次售卖权、公开展示权等许可,节点就在 ascribe 上把相关许可卖给他,收获相应的虚拟货币(如以太币)
- 节点创作更多的图,赚更多的钱,买更多的计算资源,再创作更多的图,再赚更多的钱,变成富翁

图:一张 AI 的画作
理论上,这个 ArtDAO 可以不跟任何人类分成,它存在于世的目的就是不断创作更多更好的“画作”(就像一个人类艺术家一样),不吃不喝不眠不休永不停止(这是人类艺术家所做不到的)。ArtDAO 还有可能自我升级,而且自我升级的能力可以越来越强,比如:
- ArtDAO 看到哪一类画作被买得最多,就多创作那一类。
- ArtDAO 雇佣几个人类来给自己的画作评分。
- ArtDAO 雇佣几个程序员来改进自己的智能合约代码。
- ArtDAO 自己修改自己的智能合约代码,不断收集市场反馈并调试,最终得到更好的画图能力
到这一步,ArtDAO 可能会从其他的 DAO 或者 Github 上搜索代码,跟自己的代码杂交生成下一代。而这些生成的下一代,可能不仅仅是画图能力产生了变化,还可能会改变 ArtDAO 的核心目标。“下一代”可能不再把“作画”做为自己的“DAO 生”目标,而是其他的什么目标,比如检查软件中的安全漏洞。如果新生的目标有对人类不利的成分,那人类这个物种说不定会被 AI DAO 淘汰……
AI DAO 不是科幻,而是我们已经能在今天构建的事物。
AI 是一个强力而危险的技术。DAO 们是强力而危险的技术。AI 没有的资源,DAO 有;DAO 没有的自主决策能力,AI 有。AI DAO 是更强力更危险的技术。
于是在系列的第三篇文章中,Trent 继续写到:
AI 掌握人类的资源是大趋势,无论是我们拱手相让,还是 AI 强取豪夺。我们正在将大量金钱投入 AI。我们已经在将工厂的生产线、汽车和飞机交给 AI。我们为了提升效率,将不同领域的 AI 合并为通用的高等级 AI。我们为了不让某个企业或国家垄断最强力的 AI 系统,而设计了去中心化的 AI DAO。
人类是高消耗低产出的任务处理单元。机器是低消耗高产出的任务处理单元。以效率之名,AI 最终会在所有生产行为中“优化”掉人类。
Trent 认为 AI 超越人类的那一天可能比很多人想象得更早(这在一些狭义领域已经实现了,比如围棋大师),并提出四点理由:
- 摩尔定律将继续生效(这是作者的观点)。对于很多 AI 而言,即使算法没有改良,单纯投入更多的算力(CPU、带宽、存储)就能够变强。
- 资本对 AI 的青睐已经产生了多方面的影响:小白用户也可以使用深度神经网络得到不错的结果;无监督学习能力的成熟;专用芯片大幅加成 AI 的效率(从通用芯片 -> GPU -> FPGA -> digital ASIC -> analog ASIC,每一次改进就是 10 倍的效率提升)。
- DAO 的发展程度,已经足以提供让 AI 自行获取资源的能力。
- AI 的发展道路上,并不存在根本性的阻碍。
当区块链遇到大数据
2016 年年底,Trent 先后撰文两篇,其一是《区块链与大数据》,其二是《区块链与 AI 》。
在 21 世纪最初的几年间,互联网规模的大数据方案开始成形:Yahoo 的 ZooKeeper,Google 的 BigTable 与 MapReduce,Facebook 的 Cassandra,然后是开源的 Hadoop 文件系统、Hadoop MapReduce、Cassandra 等。到 2010 年前后,MongoDB、Cloudera、DataStax 等初创企业又把这些开源的大数据项目做成了商业方案。今天,大数据技术正在静悄悄的改变世界上每一个企业的后端。
Trent 认为目前的大数据技术正面临三个关键挑战:
- 控制权。谁控制数据背后的基础架构?数据如何向全球共享?数据的多个版本如何更新?不同区域的管理员指派给谁?数据能否成为像水、电、计算、网络一样高度共享的资源?
- 数据验证。数据生成者如何证明数据是来自这里?数据使用者如何能够信任别人生成的数据?如何应对机器故障造成的数据错误?
- 变现。数据的所有权、使用权如何交易?如何打造一个通用的数据市场?
区块链也是一种数据库,具有三个明显特征:
- 去中心化(每一个管理员控制一个节点,全体管理员共享控制权)
- 数据不变性(全链路各个环节均可用私钥 / 公钥 / 哈希进行数据验证,能够更有效的剔除“坏”数据)
- 天生的资产 / 交易属性
因此,Trent 认为区块链能够解决大数据目前面临的挑战——前提是区块链技术要在可扩展性方面有所突破,能够满足海量用户群的写入、读取、查询需求。
当大数据遇到 AI
我从 90 年代开始从事 AI 研究,当时最常见的研究方式是:拿一个数据集(一般很小,而且数据是固定的),设计一个能提升性能的算法——比如针对 SVM 的分类器设计一个新内核以减少 AUC,然后把这个算法拿去发表。在当时,“可发表”的标准差不多是 10% 的提升。如果你的算法实现了 2 倍甚至 10 倍的提升,那就算得上是“最佳论文”了。
2001 年,微软研究员 Banko 和 Brill 发布了一篇重要的论文。他们首先描述了自然语言处理领域在当时的状态:通常以不到百万数量的词汇做为数据集,在普通算法(如 Naive Bayes / Perceptrons)下有 25% 的错误率,在一些全新的基于内存的算法下能实现 19% 的错误率。然而这并不是重点。Banko 和 Brill 的重要发现是:不改算法,只是增加数据集——10 倍 100 倍 1000 倍的增加,结果是错误率惊人的下降。在 1000 倍的数据量下,系统的错误率减少至 5% 以下。更惊奇的是在这个量级的数据集下,老掉牙的 50 年代 Perceptrons 算法的表现反而超越了那些基于内存的新算法。
2007 年,Google 研究员 Halevy、Norvig 和 Pereira 发布了一篇类似的论文,描述 AI 如何在吞食了大量数据之后变得“不可理喻的高效”——在很多领域都是如此。
AI 的竞争,从此变成了数据量的军备竞赛。
回顾这几十年的 AI 发展史,AI 技术在最近几年的发展速度是最快的,而数据量就是关键。
今天,无论是 Google、Facebook,还是阿里、腾讯、百度,都管自己叫做数据公司。无论他们是卖广告、卖商品、卖理财、卖游戏还是卖外卖,对他们而言,数据量就等于赚钱能力。这些在数据量储备上远远超过了其他竞争者的巨头们,并不会希望被市场上的其他玩家掌握更大量级的数据。
然而对于数据收集能力有限的非巨头玩家而言,数据共享可能会给他们带来数倍体量的数据集,这会带来显著的好处。比如,如果各个银行们将数据合并为一个数据集,则每一家银行都能够更准确的识别信用卡欺诈。如果能源公司与制造公司的数据能够合并为一个数据集,则其中的每一家公司都能够更准确的预测市场。如果全球四大钻石鉴定实验室的数据合并为一个数据集,则每一家鉴定机构都能够更准确的为钻石定价。如果保险公司能够获取这些能力,则也能获得更大的收益。
当区块链大数据遇到 AI
以前由于安全问题,大家即使看到了数据共享的好处也不敢去做。而一旦区块链大数据技术成熟,情况将有所不同:

- 去中心化的数据控制方式将促进数据的共享,不仅意味着更多的训练数据(对 AI 而言意味着更好的模型),同时也意味着 AI 模型的共享。
- 更高效的数据验证,减少了训练数据中的坏数据,提升模型的可信度。
- 训练数据与模型成为可以交易的 IP 资产。
AI 从业者总是面临一个挑战:上哪儿去找数据集?以前的数据集大多数在网上七零八碎的躺着,只有一部分比较完整的数据集收录在几个列表中,还有大量的私有数据集是我们获取不到的。如果我们有一个全球化的数据库来管理这些数据集呢?不仅有 Kaggle ,有斯坦福的 ImageNet ,还有无数其他的数据集。
有需要的话,就上 IPDB 看看吧。人们在这里上传自己的数据集,使用他人的数据集。数据集本身存储在类似 IPFS 的去中心化文件系统上,IPDB 上保存元数据用于索引。以后,IPDB 上也许不仅仅有数据集,还可以有从这些数据集中构建出的模型。人们可以在这里使用他人的模型,上传自己的模型。
共享到区块链上的数据本身具备资产属性,可以直接交易与变现。这也可能成为一个数据共享的驱动力。事实上,今天的公共数据市场已经有十亿美元的体量——一个有 Bloomberg 的 1000 倍那么大的去中心化数据市场是完全有可能实现的。
现在已经有相应的区块链技术可以把数据集与模型注册为 IP 资产,简单来说就是:
- Coala IP 协议
- BigchainDB 数据库与 IPDB 数据共享平台
- IPFS 文件系统配合 Storj 、 FileCoin 等硬件存储设备
做为示范,Trent在ascribe 给一个自己以前做的AI 模型申请了“著作权”,得到了一张虚拟证书:

数字版权可以以非常具体的方式进行授权,如著作权、所有权、使用权、编辑权、分发权等等,这些权限在区块链中可以相对容易的进行管理。就比如在 DeepMind 基于区块链的医疗项目中,用户就可以自己保有数据所有权,只授予 DeepMind 使用权。
最后,别忘了还有 AI DAO 这种可能性,让 AI 可以自行征用更多资源。
在过去,人类已经培育过去中心化的程序,那就是病毒。没人能拥有它们,没人能控制它们,没人能关闭它们。它们只是存在,试图搞坏你的计算机。
今天,有了更好的 API(智能合约语言),有了去中心化的存储系统(区块链),这些去中心化的程序将能够做更多的事情。
通用人工智能——AGI,是可以自发行动的代理决策者(agent),是一种反馈控制系统。控制系统是个顶呱呱的好东西。控制系统的数学基础深厚,可以追述到 1950 年代 Wiener 的“Cybernetics”。控制系统与这个世界交互(通过传感器与执行机),并适应这个世界(通过内部模型与外部传感器来更新自己的状态)。控制系统应用广泛——恒温空调、降噪耳机、汽车刹车、下围棋的 AlphaGo,这个世界到处都是它的身影。
AI DAO 是一个运行在去中心化软件上的 AGI 控制系统。它不断的获取输入,更新状态,调整输出,并获取资源以持续维持这个反馈循环。
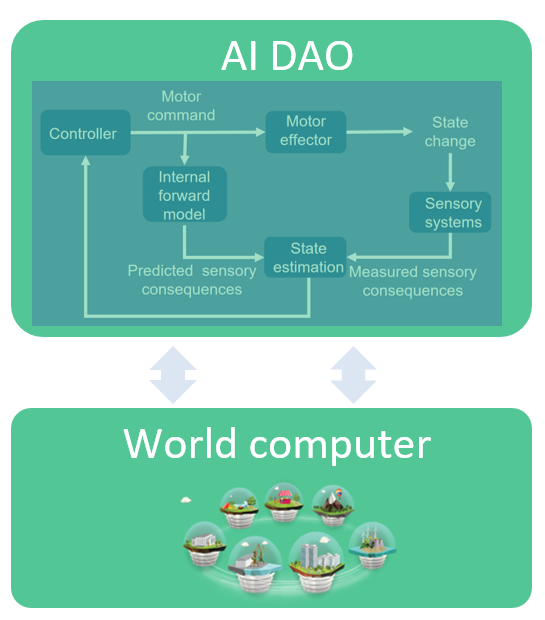
如上所述,AI DAO 有很多可能性,其中包括增强 AI 自身的能力。比如,AI DAO 可以发起“请求为我的数据做标记”的有偿请求(智能合约),用低成本雇人来完善自己的数据集(去中心化的 Mechanical Turk );AI DAO 还可以发起“将你的数据给我”的有偿请求,让 IoT 设备用自己的数据来交换电费。
Trent 十分看好 AI DAO 的潜力。然而另一方面,Trent 十分不看好 AI 与人类共存的未来。他说,很快就会有那么一天,AGI 的智能将达到人类的最高水平;之后又过了几天,人类的智力在 AI 面前就会像蚂蚁一般渺小。到那时候,人类已经无法控制 AI,而 AI 自己会决定是否要对人类“友好”。
到那一天,人类与机器共存的唯一方式,也许是与机器同化?

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论 1 条评论