今年 9 月,由国际知名科技媒体集团 O’Reilly 举办的 Artificial Intelligence 研讨会,及 Strata + Hadoop World 在纽约召开。TalkingData 有三位数据科学家亲临现场,与来自世界各地的 AI、大数据领域的学者、专家进行沟通。为了能够让国内的小伙伴第一时间了解到大会上各位嘉宾分享的内容,TalkingData 将与 InfoQ 全程合作,第一时间为大家带来大会现场的各种信息,并对最新技术、理论、成果进行点评,帮助大家了解到 AI 及大数据领域各大企业、研究机构的最新观点和研究成果。
路瑶 – AI 威胁论
Why we’ll never run out of jobs Tim O’Reilly (O’Reilly Media, Inc.)
在关于 AI 造成的恐慌中,失业问题是最经常被提及的问题之一。来自 O Reily 的 Tim 认为我们人类永远不会没有工作。

在十九世纪初期,内德 路德 为了避免造成纺织工人失业,砸毁了许多新发明和新机器。而他没有想到的是,随后发生的工业革命中创造了大量的机器,它们不但没有造成更多失业,反而将欧洲带入了前所未有的富庶的生活。
为什么我们不需要担心新技术造成人类失业呢?经济社会,特别在商业带动下,会趋向利润更高的方式发展。换句话说,如果一种工种的利润低了,那么人们就会转向利润更高的工作,而不是不去工作。人们就是这样从硬件为王转到智能时代,AI 将继续引领经济转型,走向更富裕而舒适的生活。未来对于大部分人来说,需要选择用哪个黑盒,而少部分人,是在创造黑盒。
我们无需对新技术恐慌。战胜微弱的对手我们依然微不足道,被强大打败却会让我们更强大。
Artificial intelligence: Making a human connection Genevieve Bell (Intel Corporation)

Genevieve 是一位人类学家。她的父亲是工程师,母亲也是人类学家。在她的讲座中,从人类学家的角度,使用人类学的方法论为我们解读 AI 对人类的影响。
人类学家在做人类学调查的时候会问一系列的问题,Genevieve 用同样的问题来问 AI。比如,你的名字是什么,如何解读人工,和智能。AI 的父母是谁,不仅仅是计算机学者,还有数学家,心理学家,社会学家,生物学家等的心血。你从哪里来,是按上世纪五十年代第一次人工智能的会议,还是要追溯到人们对人工智能最初的构想,比如十九世纪初期的弗兰肯斯坦。这样看来人工智能似乎身分不明。接下来,你能做什么?能下棋能驾驶能翻译,那么,你的梦想是什么?这最后一个问题,还需要我们和人工智能今后更深入的沟通。
How to make robots empathetic to human feelings in real time Pascale Fung (The Hong Kong University of Science and Technology)
Building and applying emotion recognition Anna Roth (Microsoft),Cristian Canton (Microsoft Technology and Research)
上午 309 会场主题为情感识别。香港科技大学的老师和微软的研究者分别从语音和图像两个角度介绍了他们在情感识别上的工作。
在香港科技大学老师的 tālk 中,首先回顾了 Ai 从基于知识规则,到基于统计模型,再到监督学习体系,现今到基于深度学习的发展过程以及在不同技术阶段出现的成果。他们基于深度神经网络建立了一套实时识别语音情感的方法。演示了讲短句加入 emotion 的效果。比如我很想你加入感情会是什么效果。


微软介绍他们做图片情感识别的流程。其中一大挑战是标注。情感标注是主观的,crowdsourcing 是 noisy 的,如何采用 tagger 的结果是很 tricky 的问题。另外在 data preprosessing 上也需要大量工作。他们用 DNN 实现了情感分类的识别,demo 是实时识别人脸的情绪。
What I learned by replacing middle-class manufacturing jobs with ML and AI Eduardo Arino de la Rubia (Domino Data Lab)
来自 domino 的数据科学家从自己的经历讲了对于 AI 代替人类,特别是中产阶级工作的感受。从两个故事讲解了 AI,ML 技术不仅代替了传统制造业的工人,也代替了传统的用基于行业经验和人工规则的数据分析师。
中产阶级这个概念诞生于工业革命之后,历史并不长久。而今以及以后会有大量中产阶级工作被机器取代。
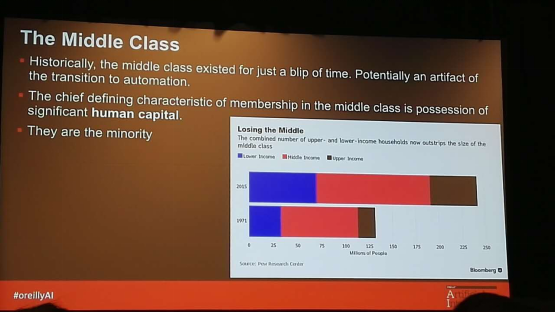
Ai 不会完全代替现有的工作,但是会使一些工作在未来消亡,近五年美国制造业的平均年龄从 40 岁上升到 44 岁,56 岁才是熟练工,这些工种不会再给年轻人工作空间。结合上午 Tim 的演讲,年轻一辈会在能产生更高利润的岗位上贡献价值 Eduardo 甚至提到一种观点,当今的生产力已经超过了生产关系,那么未来 AI 对人类社会的影响,将是深远的。
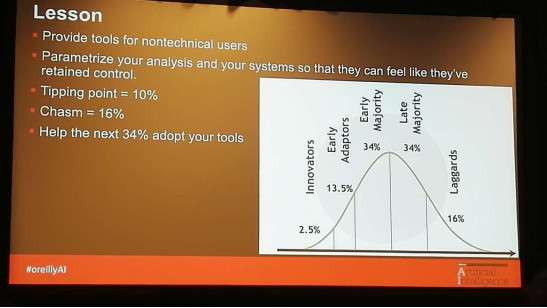
最后给出人类在新技术上的角色分布图,极少数的创造者,少数早期适应者,大部分人追随者,还有部分落伍者,看看自己属于哪一类呢。
Deep learning: Modular in theory, inflexible in practice Diogo Almeida (Enlitic)
Enlitic 是一家非常有前景的医疗 AI 公司,创始人 jeremy howard 是著名的机器学习专家。今天的主讲 Diogo 可以说是数学天才,也是 kaggle 比赛的优秀选手。Diogo 开篇直击人心,说出对 DL 两种截然不同的态度,一种认为 DL 什么都能做,一种认为只是忽悠。

之后 Diogo 从 DL 的基本逻辑讲起,介绍了 DL 在优化甚至创造上的能力。评价 DL 基本什么都可以做,如果你不考虑现实问题的话。之后讲了 DL 的挑战,困境。建议大家在使用 DL 时候不要觉得什么都可以调到最好。建议了一些 paper 继续深入了解。

在提到 DL 理论基础时,他说,当然,是没有的。引起了全场的笑声。最后他总结说,如果一个人对一件事是非常确定的,那么他一定是错的,除非,他是在说他自己并不知道这件事情,或者,他在说一件不可复现的事。
张夏天 – AI 如何推动无人驾驶以及 AI 的未来
How AI is propelling driverless cars, the future of surface transport AI 是如何推动无人驾驶汽车 – 地面交通的未来,Shahin Farshchi (Lux Capital)
Shahin Farashchi 是一位 Lux Captial 的投资人,他致力于帮助那些用技术为人类创造美好的未来的企业成功。最近 Lux Captial 投资的 Nervana(意见深度学习公司)被 Intel 以 4 亿美元价格收购;Lux Captital 还投资了 Planet Labs, Flex Logix, Zoox 等 AI 公司。
在演讲一开始,Farshchi 给出了一个让人惊悚的观点“采用会杀人的无人驾驶汽车来加速无人驾驶的未来”作为悬念,切入了无人驾驶这个目前让众人都十分关注的主题。


汽车的发展经过了 4 个阶段,从汽车发明到二十世纪 20 年代主要解决的是汽车的可制造性问题,即低成本大规模制造汽车的问题。从二十世纪 40 年代到 60 年代,人们主要追求汽车造型和性能,汽车变得越来越美观,车型逐步走向成熟,性能越来越好。从二十世纪 80 年代到 20 世纪末,人们变得越来越关心汽车的安全性和废弃排放,安全标准和排放标准越来越高。到现在人们开始追求汽车的自动化了。实际上无人驾驶汽车的到来可能比大家想象的要快,福布斯,华尔街时报这两年以来已经有不少关于无人驾驶汽车对汽车产业的影响。支持无人驾驶汽车的远距离雷达,中近距离雷达,摄像头,激光雷达,红外线等探测技术已经比较成熟。基于这些探测技术的巡航控制,行人探测,紧急煞车,冲撞躲避,车道捕捉,交通标志识别,盲区监测,自动泊车等等技术也有很大进展,有些已经进入商用。全球有几十家公司在进行无人驾驶技术的开发,既有 Google, Baidu 这样的互联网巨头,也有传统汽车制造商,很多出行 O2O 公司如 Uber, Lyft 也在进行这项工作,甚至 nVIDIA 这样的芯片公司也在进行无人驾驶技术的开发。出了行业巨头外,Cruise, Drive.ai 等创业公司也在做这方面的工作。
无人驾驶技术上已经逐渐成熟,但是人们对无人驾驶技术的安全性有很大的担忧。要求无人驾驶汽车 100% 的安全是不切实际的,但是可以将无人驾驶技术的安全性与人类驾驶的安全性进行对比。如果我们将每百万英里的死亡人数作为标准,要验证无人驾驶技术显著安全于人类驾驶需要 500 年的时间,如果以受伤人数作为标准,则需要 7.3 年,而如果以撞车事故数为标准则仅需要 3 年时间。人类驾驶中撞车是非常常见的事故,每 65000 次出行中就会有一次撞车事故。无人驾驶技术可以更好的避免撞车事故,因为无人驾驶技术能够更全面的掌握路况,同时可以通过人工智能从大量的行使车辆中学习,而人类只能通过自己经验逐步提高安全水平。最后 Farshchi 强调了三点:1. 对于无人 AI 驱动的产品,需要有全新的标准;2. 采用不完美的无人驾驶技术,能够拯救人的声明(减少伤亡);3. 我们需要创造一些工具来建造那些能够应对极端情况的 AI.
Deep neural network model compression and an efficient inference engine,Song Han (韩松)
韩松是斯坦福大学 5 年级电子工程博士,师从 Bill Dally 教授,一直致力于深度学习模型的压缩研究工作。

因为深度学习模型的庞大,使得在移动设备和 IoT 设备上应用有很大的瓶颈,模型前置方案有硬件存储资源的限制,电量的消耗等问题,云端方案也有电量,带宽和隐私问题。为了让深度学习能够前置,将深度学习模型进行压缩是必须的。对模型本身的压缩可以分成三步:1. 剪枝,首先对模型进行剪枝除去大量不必要的连接,然后以剪枝后的模型重新训练模型来恢复精度;2. 权重共享:简单来说就是所有权重做一维聚类,将权重组进行编码,实验发现对很多网络,仅需要 16 到 64 个权重组,即权重只需要 4-8 个 bit 来表示,就可以充分保证模型的预测精度。3. 对权重进行霍夫曼编码,进一步降低模型大小。通过以上方案,可以使得在模型精度损失非常小的前提下,将模型压缩 10-50 倍。使得深度学习模型能够放入 SRAM 缓存中,而 SRAM 内存的内耗只有 DRAM 的 1/120。
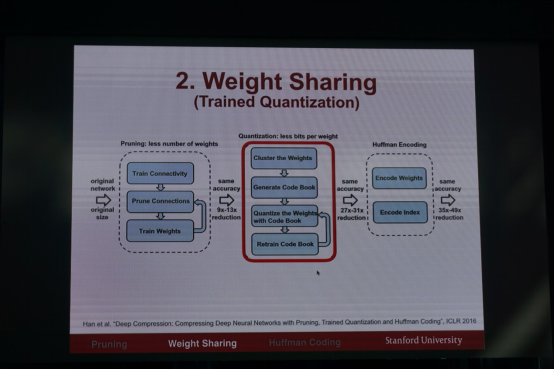
为了进一步提高压缩模型的预测速度和降低能耗,韩松博士研发了 EIE: Efficient Inference Engine on Compressed Deep Neural Networks. 基于 ASIC 的硬件加速技术,该技术充分利用了压缩后的深度学习模型的矩阵和向量稀疏性,以及维度共享的特点,使得 EIE 相比于 GPU 可以快 13 倍,而能够提高能效 3400 倍,比传统的 ASIC 技术,也能获得 2.9 倍的加速,并获得 19 倍的能效提高。
The future of AI AI 的未来,Oren Etzioni
Oren Etzioni is chief executive officer of the Allen Institute for Artificial Intelligence.
Etzioni 是 Allen Institute for Artificial Intelligence 的 CEO, Allen Institute for Artificial Intelligence 是一个非盈利的 AI 机构,致力于让 AI 为人类的公益服务。

Oren 的演讲主要想传递四个信息:
第一,机器学习现在还是 99% 都需要人工的工作,AlphaGo 只是一个神话,即使不论其问题的良好结构性,解决问题的单一性,是否能真正理解围棋,AlphaGo 的成功是整个 DeepMind 团队的努力战胜了李世石一个人。
第二,AI 的重大挑战是那些病态结构的问题,即那些没有清晰路径和方法解决的问题,比如自然语言理解的问题等。目前还看不到解决这些问题的希望。
第三,AI 成为人类的工具的可能性远大于成为人类的统治者,SkyNet 不过是好莱坞的神话,大部分人工智能专家都不认为强人工智能在 25 年内实现,有 1/4 专家认为这是永远不会发生的。
第四,AI 有巨大的潜力造福人类,比如在自动驾驶,解决信息爆炸等问题上帮助人类,当然,为了更好的应用 AI, 可能我们也需要建立一套对 AI 进行测试的标准,来保证 AI 符合人类的期望。
Deep reinforcement learning for robotics 面向机器人的深度强化学习,Pieter Abbeel,OpenAI / UC Berkeley

深度学习在计算机视觉和语音识别领域通过将大量的人工抽取 Feature 的工作用神经网络取代,用神经网络统一了 Feature Engineering 和模型训练 / 预测过程,在某些测试上取得了超过人类水平。在机器人领域,现在也开始用神经网络实现强化学习,即从感知到发出行动命令,都由一个神经网络完成。DeepMind Deep Q-Network 可以在电子游戏中实现从像素到命令的控制,并取得不错的游戏成绩,超越了之前的方法,而且该方法是通用的,可以应用在不同的环境里。基于深度学习的强化学习,在机器人的行动能力学习中取得很大的竞赛,在模拟环境下,虚拟人在完全不能走路,到能跑仅仅需要 300 来次的尝试。
目前机器人领域的前沿包括:
- 共享和迁移学习,即多个机器人一起学习并互相交换经验,加快整体学习进度;
- 基于记忆来提高学习效率和合理设定学习目标;
- 安全的学习,比如无人机和无人车的初始学习阶段要考虑飞行和移动速度,来降低风险;
- 学习目标如何与人的目标保持一致,比如无人驾驶,不仅要考虑速度和安全性,还需要考虑人的舒适性。强化学习目前的应用主要有机器手和无人驾驶。
End-to-end learning for autonomous driving 端到端的自动驾驶,Urs Muller (NVIDIA)

传统的自动驾驶技术包括一系列的步骤,通常包括感知器的整合,物体探测,定位,高清地图绘制,路径规划和自主驾驶。而 nVIDIA 的自动驾驶方案则是用神经网络取代所有过程来创建端到端的自动驾驶方案, 即传感器信号进入神经网络然后神经网络直接输出控制信号实现自动驾驶。这方案的好处大大降低了人的工作量,因为传统方法的每一步都需要大量的人工工作,特别是对探测模型等机器学习模型的训练,非常依赖人工对训练数据的标注,而这是人工非常重的工作。而这个端到端方案需要的数据仅仅是人真正驾车的操作行为和驾车时传感器数据的输入,这使得训练数据的获取变得非常容易,大大加速了自动驾驶 AI 的训练过程。
High-level APIs for scalable machine learning 大规模机器学习的高层接口,Martin Wicke (Google)

机器学习快速的变得越来越复杂。其复杂性来自三个方面,异构系统逐渐增多(CPU, GPU, TPU, ASIC…etc), 分布式系统越来越普遍,而机器学习模型也变得越来越复杂。TensorFlow 开源依赖,有很多优点受到大家认可,如灵活性,可移植性,高性能。但是用 TensorFlow 写比较复杂的模型还是比较复杂的工作,尤其是对于那些用得多的模型,让大家做很多重复构建模型的工作是非常低效的。因此,最近 TensorFlow 添加了高层接口,对于常用的模型,可以用很少的语句来进行创建。
同时,为了方便 TensorFlow 在集群上的并行,TensorFlow 将很快支持 kubernetes, Mesos 和 MARATHON,这样就解决了机器学习的分布式问题。另外,Google 将在 Google Cloud 上推出 Machine Learning Platform, 该平台基于 TensorFlow, 基于 Scale 进行训练和预测,能够与 Google Cloud 无缝集成。Google Cloud Machien Learning Platform 使得我们不需要关心底层的异构系统和分布式,基于此,可以让我们更专注于将我们的想法在 TensorFlow 上实现。
阎志涛 – ChatBot 的那些事儿
Humanizing AI development:Lessons From China and Xiaoice at Microsoft
上午的第四个主题演讲来自于微软研究院的关于小冰的演讲。提到小冰,国内的做人工智能的都不陌生,作为一个从 hackthon 产生的项目,微软小冰从 2014 年 5 月一推出就吸引了业界的注意,现在已经发展到了第四代,并且进入到了日本。ChatBot 今年无疑是非常火热的一年,小冰作为其中的典型的代表,一路发展到现在,也逐渐的找到了自己的应用的场景。在这个主题演讲中介绍到,小冰现在已经有 4 千万的用户,能够普通的聊天、做计算、进行图片识别等等。并且在与京东合作,作为购物助手、客服、可视化商品搜索等等。
一些对于 Chatbot 行业来讲,社交、智能助手等等无疑也是比较容易找到实际应用场景的领域。在参会的过程中,笔者也在尝试与微信中笔者加入的群中的 chatbot 聊天,而且能够清楚的感觉出那仍旧是个 bot,不知道 chatbot 合适能够通过图灵测试,通过图灵测试的 AI 将会给世界带来什么呢? 让我们拭目以待,期待 chatbot 的进一步发展吧。
Only humans need apply:Adding value to the work of very smart machines

这个 session 的演讲者 Tom Davenport 来自于 MIT,同时也是 International Institute for Analytics 的联合创始人。在这个 session 中,主要的问题就是在 AI 往前发展的过程中,什么样的工作会逐渐被 AI 取代? 我相信这是很多人都关心的问题。随着 AI 技术的发展,未来无疑有很多的工作会被 AI 取代,Bill Gates, Elon Musk 都对 AI 的发展表示了一定的担忧,未来的机器智能和人的智能该如何共处? Tom Davenport 对这个问题的看法是比较中立的态度。在他看来,服务性的工作未来会被 AI 替换掉,比如秘书、汉堡厨师、出租司机、酒店前台、呼叫中心代表、服务器和网络维护工程师等等。
但是对于未来的知识性的工作,工作的替换是缓慢的,并且是人和机器一起工作来完成。未来将是智慧的人类帮助智慧的机器或者智慧的机器帮助智慧的人类,看到这里不由的想起了 T11 的时候 TalkingData CEO 崔晓波提出的新的贝叶斯定律 - SmartDP 是数据 + 人的智慧 + 机器智能,我也相信这是 AI 发展的比较现实的未来,具体到更远的未来,那就等着奇点来临吧!
Pratical AI Product Development

这个主题来自于 Fast Forward Labs 的 Hilary Mason,这是个帮助企业实施数据科学项目和产品的咨询公司。整个演讲的内容对于笔者来讲还是很有些共鸣。首先的问题是什么是一个产品?这里 Hilary 给了自己的一些理解。另外如何开发一个 AI 产品,Hilary 认为现在的开发软件的组织形式和方法都需要针对 AI 进行相应的改变。因为 AI 产品不像软件产品,软件产品都是确定性的,而 AI 产品则是不确定性的。对于 AI 产品来讲,需要深入了解业务问题,然后就是数据、数据、还是数据,最后是 AI 能力。AI 产品的开发是一个实验性的过程,因此要设置合适的里程碑,采用最简单的可以 scale 的算法,并且随时根据反馈调整。另外,对于用户体验,AI 产品也应该有很大的不同。这些思路,在我们做数据相关的产品时,也很有共鸣,对于传统的软件技术人员、产品经理来说,如果想要开发 AI 或者数据产品,观念上需要一定的转变才行。
Transforming your industry with Cognitive Computing

这个专题来自于 IBM 的 Research,提到认知计算,就需要提到 IBM 了,认知计算是 IBM 这几年极力在推广概念,基本就是推广 IBM 的 watson 和 bluemix。基本讲的是 watson 使用的领域,包括医疗、财务、教育、生产制造等等,另外就是介绍 waston cloud 和 bluemix。希望未来每个人都有一个 watson 支持的认知助手。这里最后 IBM 认为未来是人的智慧 + 机器的智能,我只能说英雄所见略同了,这之比 SmartDP 少了 Data,但是 Data 又是两种智慧的基础。
Benefits of scaling machine learning
很遗憾这个没拍到第一页 slides,只好放第二页的 slides。这个演讲的内容相对比较干,Reza 是 Stanford 的顾问教授,同时是 Matroid 的创始人,曾经在 databricks 开发机器学习库。在这个主题中,Reza 以 3D 图像识别为例子,引入规模化机器学习的必要性,然后开始介绍在 Spark 上如何优化矩阵计算,从而引出了 Spark TFOCS,在 Spark 上的 TFOCS 基本遵循 Matlab 上的 TFOCS,这无疑是一个福音,另外 Matroid 的相关的论文,获得了 KDD2016 的最佳论文,有兴趣的可以找来看看。
Unlock the Power of AI: A fundamentally different approach to building intelligent system.

在当今这个时代,开发智能应用系统还是有很多的技术和算法的门槛。我们需要工程能力、数据科学能力、业务知识的综合才有可能开发出一个智能系统。如何降低这个门槛就变成了很重要的问题,这个主题的演讲者是 Bonsai 公司的 CEO。Bansai 公司在 Strata AI 开幕前一天刚刚宣布完成了 600 万美金的 A 轮融资,他们的主要业务就是抽象 AI 能力,使得 AI 开发对于普通人都可以完成。他们有一套叫做 linkling 的开发语言,同时提供 AI 引擎,CEO 在现场就用 linkling 开发一个智能小游戏,整个过程还是挺让人惊讶的,降低人工智能开发门槛,无疑是这个行业往前进的很重要的一步。
The Need for speed:Benchmarking DL workloads

这个专题来自于百度硅谷深度学习研究院,整个片子铺垫的是百度做的深度学习相关的项目,包括无人车、翻译、对话系统等等,以这个为引子,说明了对于深度学习来将,性能非常的重要,可是如何衡量性能呢?百度硅谷研究院开源了针对深度学习的性能测试框架 -DeepBench,整个演讲并没有太多关于 DeepBench 的细节描述,有兴趣的可以去 github:
https://github.com/baidu-research/DeepBench
作者介绍:
路瑶:TalkingData 数据科学家 前阿里巴巴算法专家,瑞士洛桑联邦理工大学访问学者,清华大学自动化系硕士。2016 年加入 TalkingData 任数据科学家,负责图算法、时间序列分析等方向。TalkingData 全球算法大赛技术负责人。
张夏天:TalkingData 首席数据科学家,北京邮电大学硕士毕业,长期从事数据挖掘,机器学习相关领域的研究和应用工作。曾在 IBM 中国研究院,腾讯数据平台部,华为诺亚方舟实验室任职,2013 年加入腾云天下任首席数据科学家,全面负责数据挖掘工作,包括移动应用推荐系统、移动广告优化、移动应用受众画像、移动设备用户画像、游戏数据挖掘、位置数据挖掘等工作。同时负责大数据机器学习算法的研究和实现工作。发表学术论文 10 篇,申请专利 9 个。
阎志涛:现任 TalkingData 研发副总裁,领导研发了公司的数据管理平台 (DMP)、数据观象台等产品,并且负责公司大数据计算平台的研发。目前专注于构建一个融合多种计算模型,支持机器学习和数据挖掘的大数据计算平台。关注 Spark、Hadoop、HBase、MongoDB 等技术。超过 15 年的 IT 领域从业经验,一直从事大规模分布式计算系统、中间件、BI 等相关工作。
本科毕业于北京大学大气物理专业,硕士毕业于华北计算计算技术研究所,研究方向为分布式计算系统。在加入 TalkingData 之前,历任 IBM CDL 资深架构师,Oracle 亚太区首席中间件技术顾问,BEA 亚太区首席中间件技术顾问等职务。参与一系列跨国以及大型的国内的中间件、BI 等项目。




