
机器学习是 LinkedIn 公司关联营销的关键组成部分。他们使用机器学习为 feed、广告、推荐系统(比如 People You May Know )、邮件优化、搜索引擎等训练排序算法。更深一点的例子可以看 LinkedIn 的 feed 流实现[部分一,部分二],涉及到如何把机器学习应用到feed 流排序中。
这些算法在提升用户体验时起重要的作用,因此,他们需要提供给工程师们一个简单易使用的机器学习工具,使得工程师能创建高质量的机器学习模型并且模型能够快速应用到大数据集。为了满足这种需求,LinkedIn 开发了Photon 机器学习。Photon 机器学习支持Apache Spark,通过结合Spark 快速处理海量数据的能力和强大的模型训练和诊断工具,Photon 机器学习提供给研究型工程师更多的信息来决策使用哪类推荐系统算法。
Photon 机器学习在许多不同的领域为研究型工程师提供广泛的价值,现在已开源。
Photon 机器学习是什么?
Photon 机器学习提供支持大规模回归,支持带 L1、L2 和 elastic-net 正则化的线性回归、逻辑回归和泊松回归。Photon 机器学习提供可选择的模型诊断,创建表格来帮助诊断模型和拟合的优化问题。Photon 机器学习实现了实验性质的广义混合效应模型,下面会详细介绍。
在 LinkedIn 如何应用 Photon 机器学习?
典型的机器学习系统以下面的流程图表示。第一阶段是数据预处理,从在线系统清晰数据,创建数据表,特征提取。接下来的阶段是应用机器学习算法为推荐系统或者搜索系统学习得到好的评分函数,进而选择最好的模型。最后,最优模型进行在线 A/B test 发布,来测试其对用户体验的影响。
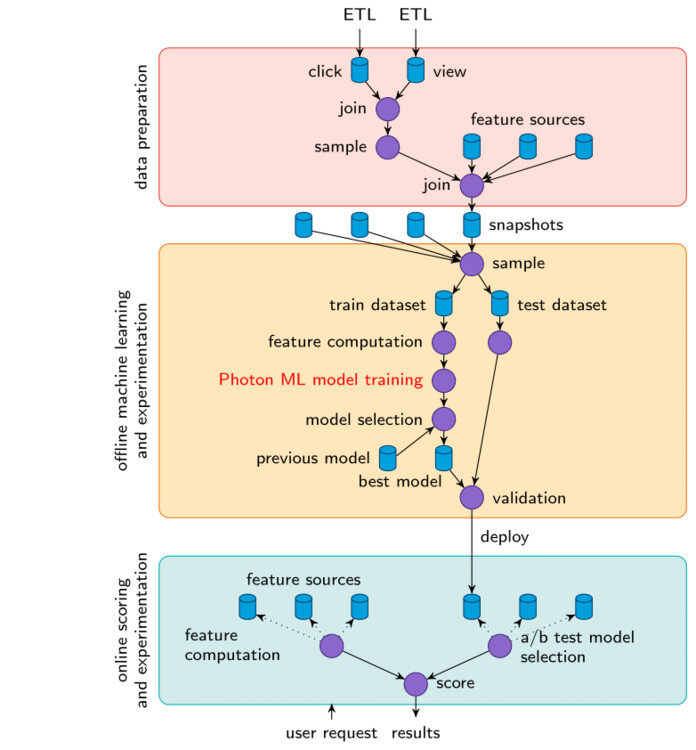
Photon 机器学习是 LinkedIn 公司模型训练的核心,可作为其它机器学习库的热插拔替代。在上面的流程图中,圆圈代表行为,圆柱体代表数据集。
如何在集群中运行 Photon 机器学习?
在 LinkedIn 公司,Photon 机器学习运行使用 Spark on Yarn 模式,与其它 Hadoop MapReduce 应用共用同一个集群。我们可以很容易在同一个工作流中混合使用 Photon 机器学习和传统的 Hadoop MapReduce 程序或者脚本。模型训练从 Hadoop MapReduce 迁移到 Spark on Yarn 可提速 10 到 30x 倍。为了更好的使用 Spark,机器学习算法团队贡献了支持 Spark 的 Dr. Elephant。
Spark 和 Hadoop 工作流共用同一个集群,可支持 LinkedIn 已有的机器学习输入和输出格式,极大的提高 Photon 机器学习在 LinkedIn 的推广。现在许多团队在开发关联应用和安全数据科学时使用 Photon 机器学习,一些团队也在线上使用。
Photon 机器学习的发展方向:GAME
作者开源 Photon 机器学习到社区,对其他人构建和应用机器学习会有工业级别的影响。虽然当前有许多开源的机器学习库,但作者认为 Photon 机器学习是相当重要的补充。Photon 机器学习提供广义混合效应模型(GAME)。
当前,Photon 机器学习实现 GAME,支持广义线性混合效应模型(GLMix)。GLMix 模型由固定效应和多随机效应模型组成。固定效应模型对应传统模型和广义线性模型,假设每个观测变量是独立的。随机效应在固定效应的留存中附加多粒度参数(users, items, segments)获取额外的异质性。一般规则化是用来避免过拟合。并且,随机效应会引起观测变量的边际依赖。
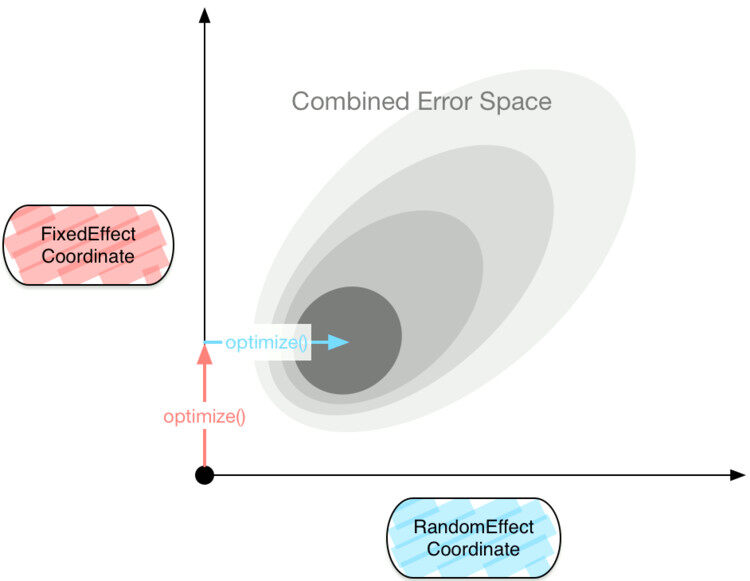
GAME 采用坐标下降法依次解决每个系数。
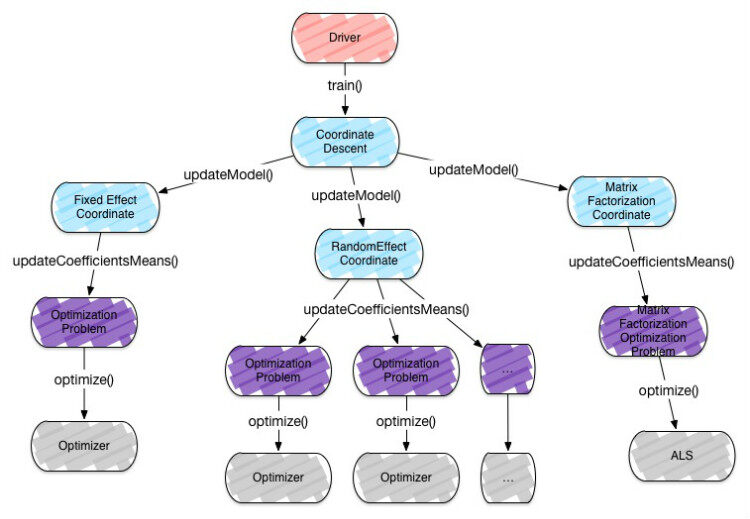
我们使用坐标下降法优化所有问题,单步按序调试每个效应,使用合适的优化器解决子问题。对于固定效应坐标,我们使用分布式回归算法按列分区数据。Spark 的 RDD 每次迭代利用本地数据优势,在不用 shuffle 数据的情况下快速优化。为了有效地解决随机效应坐标,我们根据随机变量分区数据,用单机算法解决随机效应坐标。
GAME 模型提供精确的图表来辅助研究型工程师定位问题。作者希望使用这些技术更广泛的提高推荐系统的算法。LinkedIn 公司内部使用 A/B test 显示 Photon 机器学习训练 GLMix 模型在工作推荐中提高了百分之十五到百分之三十,在邮件推荐中提高百分之十到百分之二十(基于点击率)。虽然这些 test 只是在早期阶段,但得到的结果表明 Photon 机器学习能显著的提高推荐效果。
Photon 机器学习提供的 GAME 算法训练模型,作者后续将持续提高它的稳健性和易用性。除了广义线性模型外,作者已经开发了分解式随机效应模型试验性代码,利用矩阵分解来和随机效应交互。在未来,作者将会继续用广义混合框架实现其它的机器学习算法。
英文原文: Open Sourcing Photon ML:LinkedIn’s Scalable Machine Learning Library for Spark
译者介绍:侠天,专注于大数据、机器学习和数学相关的内容,并有个人公众号:bigdata_ny 分享相关技术文章。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...









评论