
随着云计算大数据的发展,有越来越多的场景需要借助于实时数据处理技术,为此有很多公司开发了自己的实时处理系统,Facebook 就是其中的一员,他们构建的实时数据处理生态系统每秒钟能够处理数百 GB 的数据。本文介绍了 Facebook 在设计该系统时从易用性、性能、容错、可伸缩性以及正确性等方面考虑所做的重要设计决策,这些决策和系统如何满足秒级的延迟需求,以及在构建该系统的过程中 Facebook 所总结的经验教训。
Facebook 认为在设计一个实时数据处理系统的时候首先要想清楚下面 5 个问题:
- 易用性:处理需求有多复杂?SQL 是否足够?是否必须要使用 C++ 或者 Java 这样的编程语言?用户编写、测试和部署一个新的应用程序需要多长时间?
- 性能:允许多长时间的延迟,毫秒级,秒级,还是分钟级?单机或者总体需要多大的吞吐量?
- 容错能力:可以容忍哪些类型的错误?数据处理或输出的次数通过什么语义来保证?系统如何存储和恢复内存状态?
- 可伸缩性:数据是否支持分片从而进行并行处理?系统是否能够容易地随着数据量的变化进行调整?是否可以重新处理之前的有价值的老数据?
- 正确性:是否需要 ACID 特性?作为输入的所有数据是否都需要被处理并在最终的结果中出现?
针对这些问题,Facebook 提出了 5 个设计决策:语言范式、数据传输、处理语义、状态保存机制以及数据再处理。下面的图表展示了每一个设计决策对数据质量属性的影响:

以及不同的流处理系统所做的设计决策:
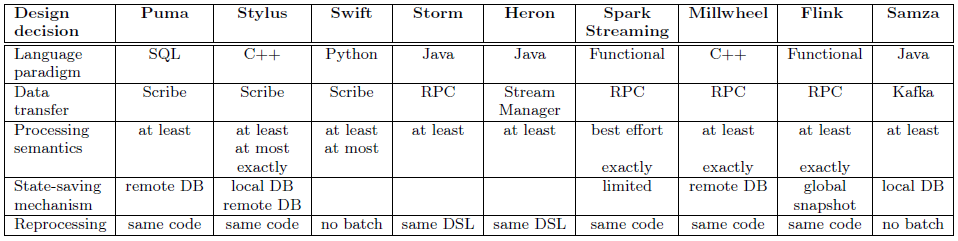
语言范式决定了编写应用程序的难易程度以及开发者对性能的操控程度。基本有三种选择:声明式,函数式以及过程式编程语言。对于 Facebook 而言,单一的某种语言无法满足所有的用例,因此他们开发了三种不同的流处理系统。
数据传输对流处理系统的容错性、性能和可伸缩性都有非常大的影响,传统的数据传输方式包括:直接消息传输、基于代理的消息传输和基于持久化存储的消息传输。Facebook 使用 Scribe,一种持久化的消息总线,来连接不同的处理节点。
处理语义包括状态语义(每一个输入事件最少被计数一次、最多被计数一次还是只被计数一次?)和输出语义(给定的输出值在输出流中最少出现一次、最多出现一次还是只出现一次?)。其中无状态的处理器只有输出语义,而有状态的处理器这两种语义都有。Facebook 对不同的应用通常有不同的状态和输出语义需求,因而开发了 Puma、Stylus 和 Swift 三个支持不同语义的系统。
状态保存机制的实现方式有很多,包括复制副本、本地数据库持久化、远程数据库持久化、上游备份以及全局一致性快照等。Facebook 实现了两种状态保存机制,其中 Puma 实现了远程数据库存储,而 Stylus 则实现了本地和远程数据库存储。
再处理的方式有三种:仅使用流处理;维护两个单独的系统,一个用于流处理,一个用于批处理;开发一个能够在批处理环境中运行的流处理系统。Facebook 采用了一种与 Spark Streaming 以及 Flink 都不同的处理方式,他们使用标准的 MapReduce 框架从 Hive 中读取数据并在批处理环境中运行流处理应用程序。Puma 应用可以运行在 Hive 环境中,而 Stylus 则提供了三种类型的处理器:无状态的处理器,通用的有状态的处理器和一个居中的流处理器。
在系统建设方面,Facebook 的主要设计目标是秒级的延迟,每秒钟能够处理几百 GB 的数据,为此他们通过一个持久化消息总线将所有的处理组件连接起来进行数据传输,同时也将数据的处理和传输解耦,实现容错、可伸缩、易用性和正确性。整个系统的架构图如下:
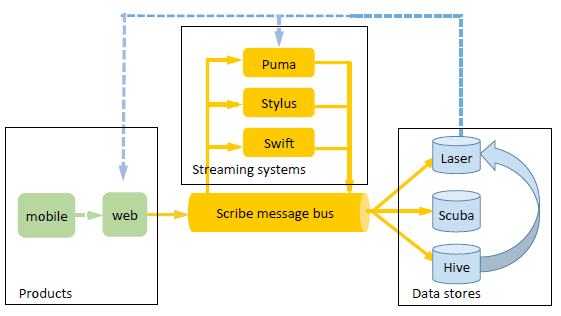
该图阐述了 Facebook 实时处理系统的数据流,数据从左侧的移动和 Web 产品中产生,然后被送入 Scribe(一个分布式数据传输系统),而 Puma、Stylus 和 Swift 等实时流处理系统则从 Scribe 中读取数据并将处理结果写入 Scribe。Puma、Stylus 和 Swift 可以根据需要通过 Scribe 连接成一个复杂的 DAG(有向无环图)。
接下来是使用该实时处理系统的一个示例应用,该应用识别一个输入事件流中的趋势事件,以 5 分钟为单位对这段时间内产生的话题按事件数排序。每个事件包含一个事件类型,一个维度 ID(用于获取事件的维度信息,例如使用的编程语言)和一个文本(用于分类事件主题,例如电影或者婴儿)。该应用有 4 个处理节点,每一个都可以并行执行,整体流程图如下:
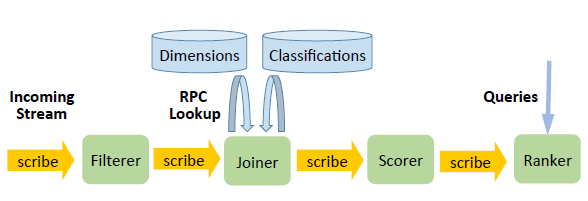
在该图中,Filterer 会根据事件类型过滤输入流,然后将输出按照维度 ID 进行分片,这样下一个节点就能够并行处理分片数据了。Joiner 通过维度 ID 从一个或者多个外部系统检索信息,然后根据事件的文本内容对其按照话题进行分类。Scorer 记录着最近一段时间内每一个话题的事件数,同时还会跟踪这些计数器的长期趋势。Ranker 则计算每 N 分钟每一个话题的前 K 个事件是什么。
最后是 Facebook 在构建该系统的过程总结的一些经验教训:首先,没有一个单独的流处理系统能够适应所有场景,针对不同的点使用不同的系统才能更好地解决问题;其次易用性不仅包括使用,还包括开发、调试、部署、监控和运维等方面;最后,流处理和批处理并不是互斥的,组合使用这两种系统能够加速数据的处理速度。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论