在 2016 年 4 月份举行的 Kafka 峰会上,LinkedIn 在 Apache 2.0 许可协议下开源了 Kafka Monitor,并于近日详细介绍了该监控工具的架构以及他们最初的构建动机。在年初的时候,LinkedIn 曾在一篇有关Kafka 整体应用的文章中简单地提及过Kafka Monitor,但并没有详细介绍该项目的语义组成或者背后的动机。
Kafka Monitor 项目的动机有三个:
- 需要监控和测试 Kafka 部署并跟踪主干稳定性,以便他们能够尽早捕获正在开发的变更集中的问题;
- 需要不间断地在生产集群上监控 SLA,并不断地在测试集群上运行回归测试;
- 现有的监控框架无法满足其用例的扩展性、模块化需求,他们需要一个自定义的客户端库。
网站可靠性工程部门过去已经监控了输入速率、离线分区数和正在复制的分区数等指标,以确定 Kafka 集群的可用性和系统整体的健康状况。然而,问题在于,这类原始的值本身无法表明集群在终端用户体验方面是否真的可用。
在 LinkedIn 的公开出版物 Keystone Pipeline 里,他们提到了两个潜在的 Kafka 候选监控方案,微软的一个项目和Netflix Kafka 监控,但最终确定它们不适合自己的应用场景。
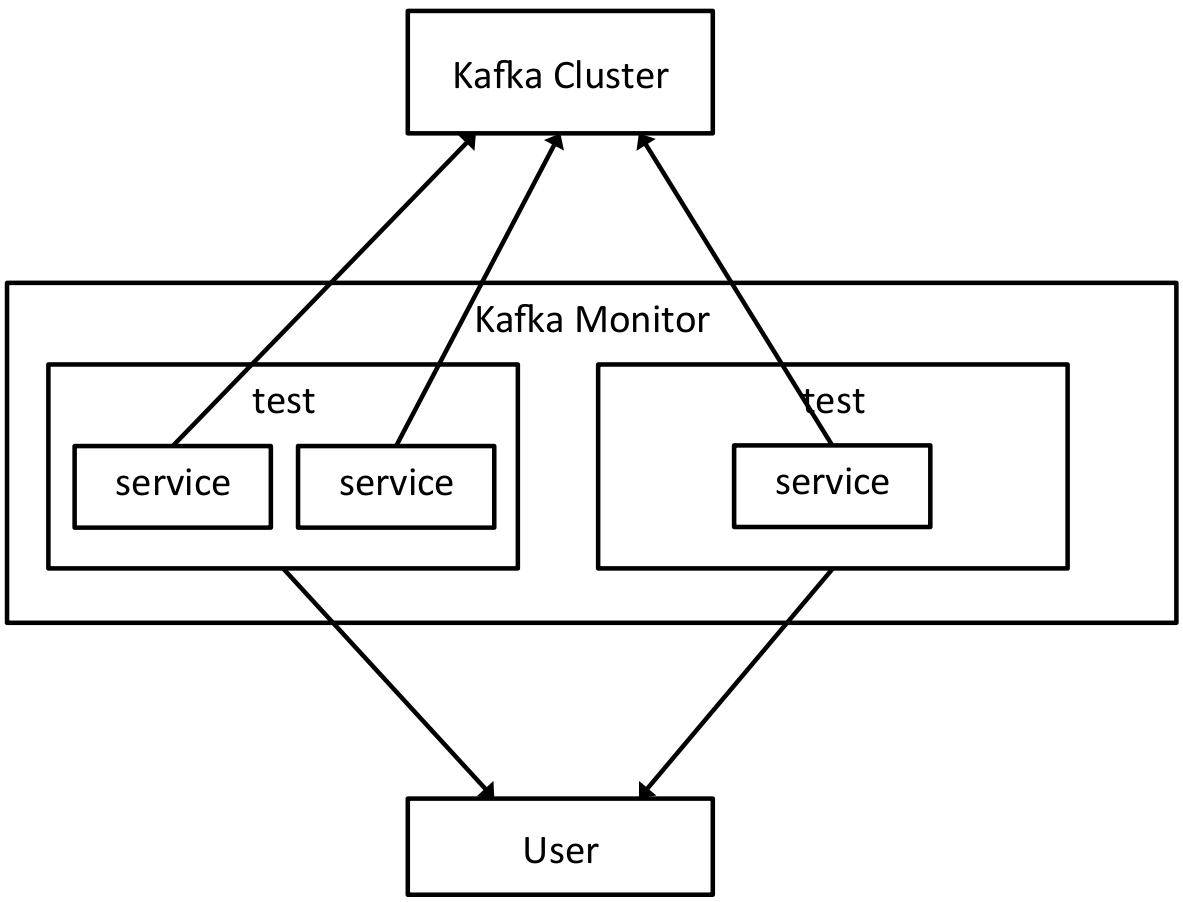
Kafka Monitor 允许开发人员组合模拟各种故障场景的模块,如 GC 中断、broker 硬杀及“滚动弹出(rolling bounces)”、磁盘故障,并随着场景进行收集有关服务运行时行为的指标。每次当生产者创建消息时抛出的异常被捕获,衡量生产者服务错误率的指标就会增加。消费者服务会跟踪一个由 Kafka 分区分割的增量索引计数器以及消息净荷的时间戳,以便度量消息丢失率、重复率以及端到端延迟。
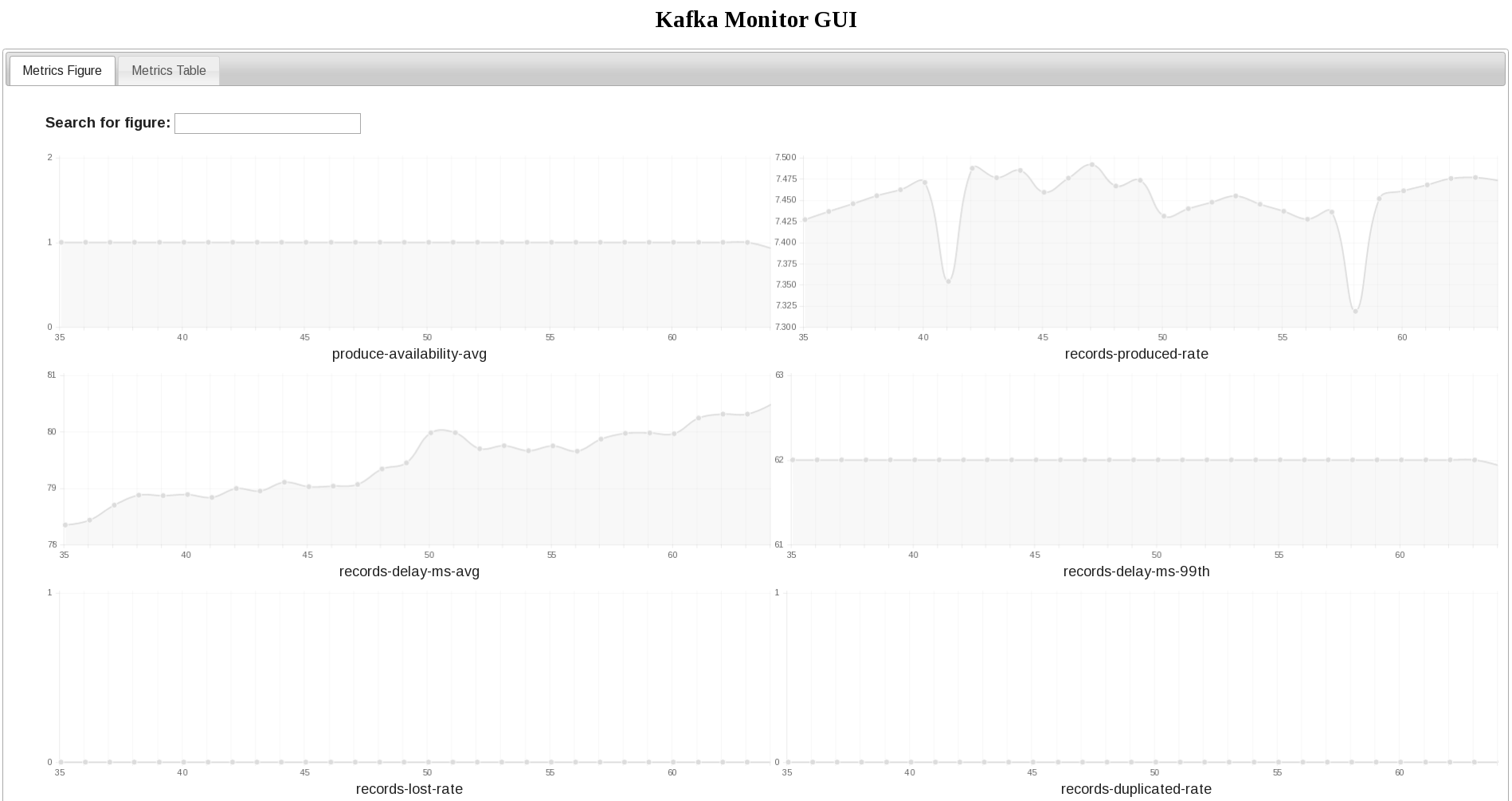
Kafka Monitor 实例运行在一个单独的 Java 进程中,运行多个测试,介于用户或消费者服务与 Kafka 集群之间。Kafka Monitor 收集的运行时指标包括生产者服务的生产效率、消费者服务的消费效率、消息丢失、消息重复和端到端延迟。多个 Kafka Monitor 跨多个 Kafka 集群运行大量的测试场景,这可以由一个复制服务通过镜像方式捕获跨集群的总体延迟指标。
Kafka Monitor 原生支持 Java,但也为非 JVM 语言提供了一个 REST 接口。这对开源社区有着特殊的意义,LinkedIn 的 Dong Lin 表示:
我们一般会脱离 Apache Kafka 主干,并每季度生成一个新的内部版本,或者吸收 Apache Kafka 的新特性。脱离主干的一个显著的好处是,部署在 LinkedIn 生产集群中的 Kafka 经常有已经在 Apache Kafka 主干中检测到的问题,他们可以在 Apache Kafka 正式版本发布之前进行修复。
Kafka 项目本身包含一些系统测试,每次代码捡入时都会运行,鉴于和 Kafka 主干的紧密关系,LinkedIn 计划实现类似的系统测试。他们希望将 Kafka Monitor 和类似 Simoorg 这样的错误注入框架以及 Graphite 或类似的框架集成,以便能够通过一个单独的 Web 服务查看 Kafka Monitor 集群生成的所有指标。





{kind=link}
{kind=link}
{kind=link}