日前,LinkedIn 在 Github 上基于 Apache 2 许可证协议开源了其分布式对象存储系统Ambry 。Ambry 是一个是不可变对象的存储系统,非常易于扩展,它能够存储KB 到GB 大小的不可变对象,并且能够实现高吞吐和低延迟,该系统支持跨数据中心的双活部署,并且存储成本低廉。它特别适于存储各种媒体内容。
据Linkedin 的前工程主管 Sriram Subramanian 介绍,媒体内容在 Web 中已经无处不在,Linkedin 中的每项新特性基本上都会与某种类型的媒体内容进行交互。这些媒体内容会存储在后端,并且主要会由内容分发网络(Content Delivery Networks,CDN)来提供服务,后台存储系统会作为 CDN 的原始服务器(origin server)。
随着 Linkedin 流量的不断增长,原来所使用的媒体内容存储方案在可扩展性、可用性以及运维方面所遇到的问题越来越多。两年前,他们着手解决这些问题,而 Ambry 正是该项工作的结果。
2013 年时的媒体存储是什么样的?
LinkedIn 之前的系统被称为媒体服务器(因为没有一个像样的名字),这个系统由两部分组成,分别是用于媒体文件存储的 Filer 以及存储元数据的大型 Oracle 数据库。这些系统的前端是一些运行在 SOLARIS 上的无状态机器,它们会将请求路由到对应的 Filer 或数据库上。Filer 是通过 NFS 的方式 mount 到无状态机器上的,并使用 Java 的 File API 进行远程访问。前端会与数据中心(DC)里面的一组缓存进行交互,从而保证如果下游系统(Filer/Oracle)出现性能问题或不可用时,前端不会受其影响。
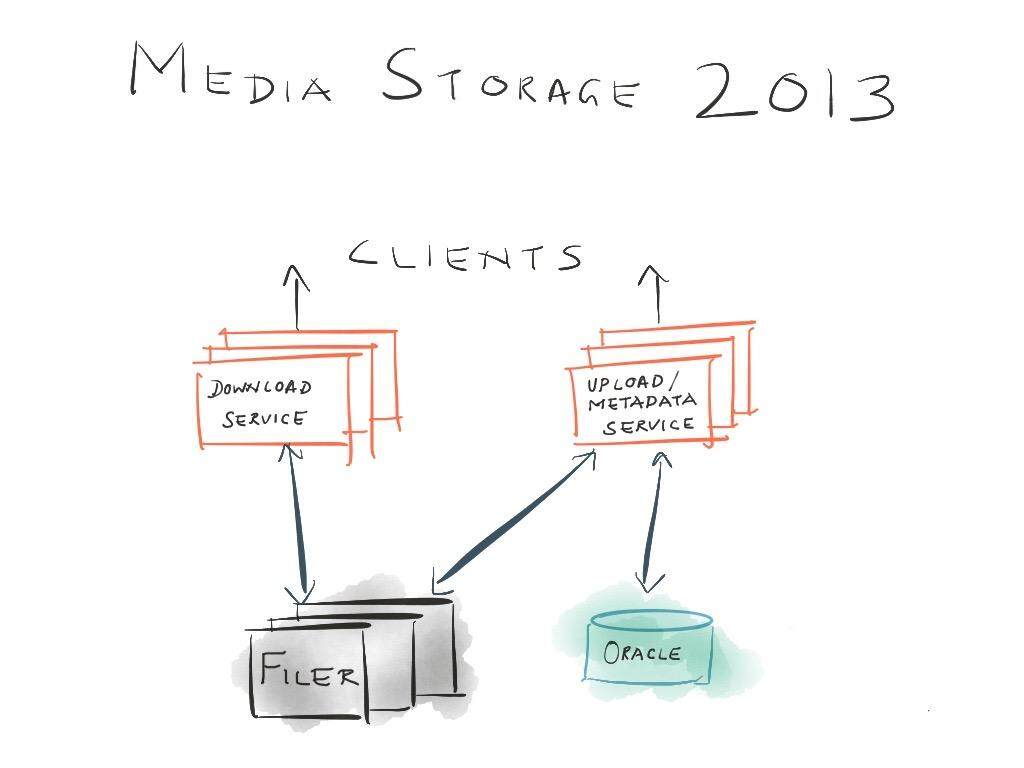
随着 LinkedIn 对媒体内容的需求不断增加,原有的系统在面临这些需求时,遇到了如下严重的问题:
-
频繁出现的可用性问题:每次对文件的元数据操作出现峰值时,原有的系统都会出现延迟。当访问大量的小文件时,对元数据的操作就会增多。每次文件操作都要经过多级的转换(Java、NFS 以及 Filer),使其很难进行调试;
-
难以扩展:用来存储数据和元数据的底层系统都是单体的。水平扩展元数据的存储是不可能实现的,为数据存储增加硬件也需要很多的手动过程;
-
对小对象和大对象的支持效率低下:媒体数据集中包含了数万亿的小对象(50KB-1MB)也包括数亿的大对象(1MB-1GB)。对于小对象的存储来说,元数据操作的代价是很高昂的,而对于大数据,原有的系统缺乏端到端的流支持,难以支持新产品的使用场景;
-
平均修复时间(MTTR,Mean Time To Repair)指标很差:老系统中的大多数组成部分在很大程度上都是黑盒,这需要获得支持许可证,并且要通过电话的方式来描述和解决问题,这会影响到 MTTR;
-
成本高昂:旧的媒体存储成本很高,再继续扩展的话,成本上已经吃不消了。如果想管理媒体的扩展性,就不能延续该方案了。
在这个过程中,Linkedin 探索过多种替代方案,最终还是决定自行实现更匹配其需求的解决方案。
Ambry 是如何运行呢?
设计目标
在了解 Ambry 的设计和内部运行原理之前,明确其设计目标是很有帮助的,这决定了它的实现方式。
- 高可用性和水平可扩展:该系统要处理实时流量,会直接影响到站点的可用性,因此它必须具有很高的可用性。另外,还希望新系统能够尽可能地实现无缝的集群扩展;
- 降低运维的负担:分布式系统一般都会难以管理,对于频繁的集群操作,能够实现自动化是非常重要的,这能避免系统成为运维的一种负担。复杂的系统通常很难实现自动化并可靠的运行,因此新系统的设计要简单、优雅并自动化;
- 更低的 MTTR:分布式系统出现故障是难以避免的,但是很重要的一点在于快速修复故障,让各个子组件启动并运行。这就需要系统的设计简单,并且不会出现单点故障;
- 跨 DC 双活:Linkedin 有多个数据中心,因此所有的系统都要支持双活配置,这样的话,系统能够更新不同数据中心中的同一个对象;
- 提升小对象和大对象的效率:请求是由小对象和大对象所组成的,小对象通常是 1K 到 100K,超出这个范围的对象会位于大对象桶中(bucket)。要同时处理好各种大小的对象,通常来讲是很困难的。大量的小对象会给元数据带来很高的负载,造成硬盘碎片,需要很多的随机 IO,而大对象则需要很好的内存管理、端到端的流处理和有限的资源使用;
- 廉价:媒体内容很快就会占据很大的存储空间,它的另外一个特点是旧数据会变成“冷”数据,并不会频繁访问。针对这种情况有很多优化技术,包括使用密集的硬件(denser hardware)、分层存储、擦除编码以及数据去重等。在设计时,Ambry 希望媒体内容能够高效存储在密集型的机器上,并且能够非常容易地使用其他优化成本的方案。
概览
总体上来讲,Ambry 由三部分组成,分别是用来存储和检索数据的一组数据节点,路由请求的前端机器(请求会在一些预处理之后路由到数据节点上)以及协调和维护集群的集群管理器。数据节点会在不同节点之间复制数据,同时支持数据中心内部和数据中间之间的复制。前端提供了支持对象 PUT、GET 和 DELETE 操作的 HTTP API。另外,前端所使用的路由库也可以直接用在客户端中,从而实现更好的性能。在 LinkedIn,这些前端节点会作为 CDN 的原始服务器。
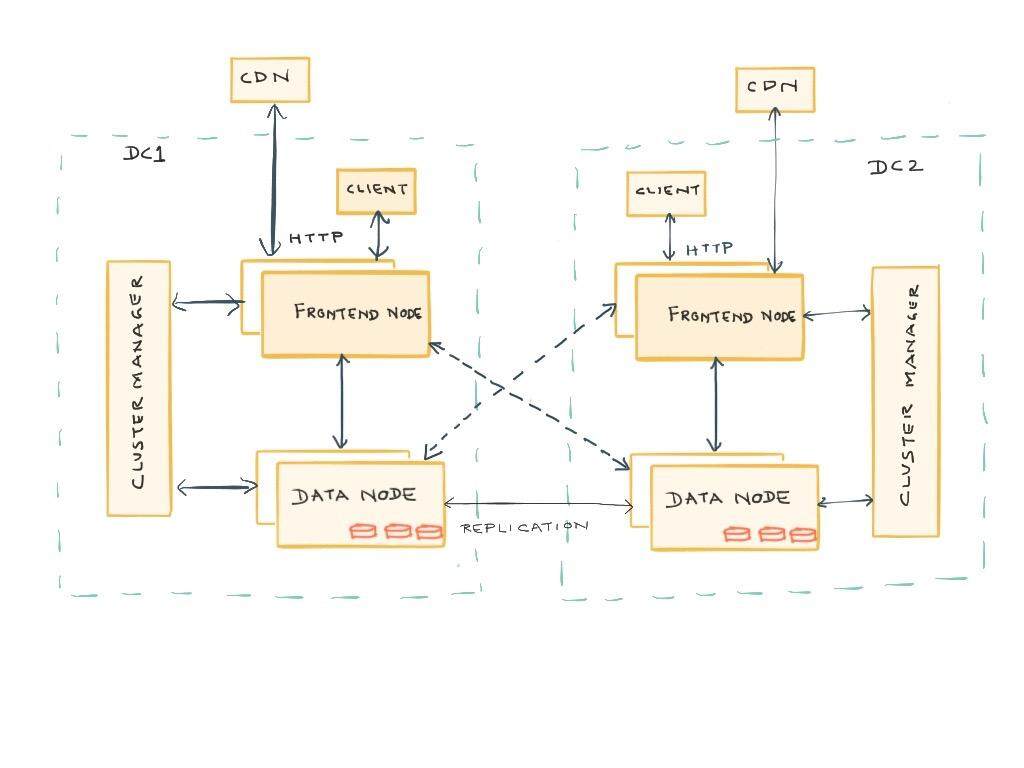
API
Ambry 提供了 REST API,它们适用于大多数的场景。在有些场景下,需要更好的性能,如果是这样的话,Ambry 也支持在客户端使用路由库,直接针对数据节点的流字节进行读取和写入。目前,路由库是阻塞的(同步),不过 Ambry 目前正在致力于实现非阻塞(异步)版本,同时也会提供对路由库的多语言支持。
Clustermap
Clustermap 控制拓扑结构、维护状态并帮助协调集群的操作。Clustermap 有两部分组成:
- 硬件布局:包含了机器的列表、每台机器上的磁盘以及每个磁盘的容量。布局还维护资源的状态(机器和磁盘)并指定主机名和端口,通过主机名和端口就能连接到数据节点;
- 分区布局:包含了分区的列表、它们的位置信息以及状态。在 Ambry 中,分区有一个数字表示的 ID,副本的列表可以跨数据中心。分区是固定大小的资源,集群间的数据重平衡都是在分区级别进行的。
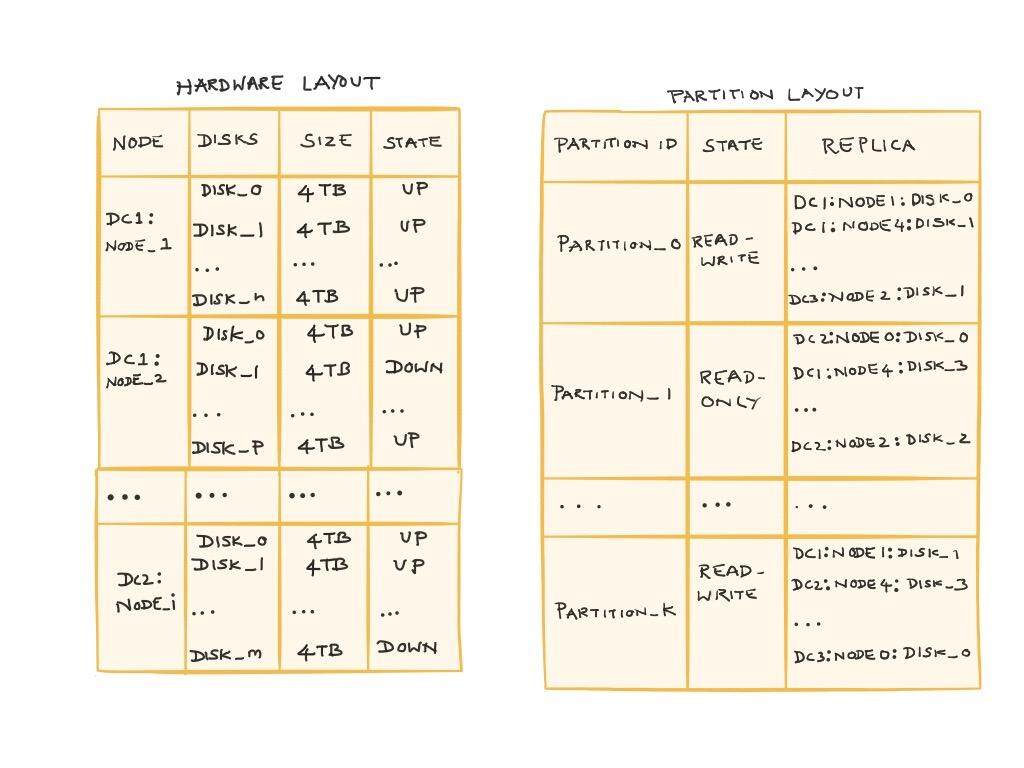
数据节点和前端服务器都能够访问 clustermap,并且会始终使用它们当前的视图来做出决策,这些决策涉及到选择可用的机器、过滤副本以及识别对象的位置等。
存储
存储节点会用来存放不同分区的副本。每个存储节点会有 N 块磁盘,副本会跨磁盘分布存储。这些副本的结构和管理都是相同的。
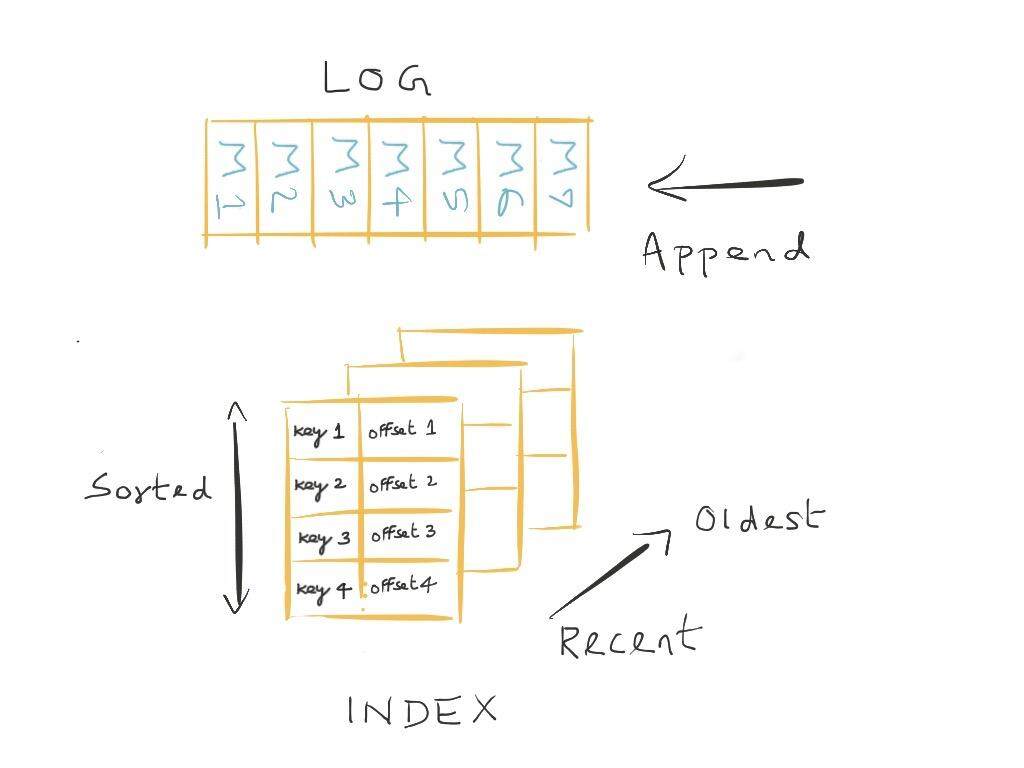
在存储方面,Ambry 涵盖的功能包括如下几个方面:
- 持久化:磁盘上的每个副本均被建模为预先分配的 log(preallocated log)。所有新的消息都会按照顺序附加到 log 上,消息是由实际的对象块(chunk)和相关的元数据(系统和用户)所组成的。这能够使写入操作实现很高的吞吐量,并且避免出现磁盘碎片。Ambry 会使用索引将对象 id 与 log 中的消息映射起来,索引本身是一组排序的文件片段,条目按照最新使用在前,最旧的条目在后的顺序,从而便于高效查找。索引中的每个条目都维护了 log 中消息的偏移量、消息的属性以及一些内部使用的域。索引中的每个片段会维护一个 bloom filter ,从而优化实际磁盘操作所耗费的时间;
- 零拷贝:通过使用 sendfile API,在进行读取时,字节从 log 转移到网络的过程中实现了零拷贝。通过避免额外的系统调用,实现了更好的性能,在这个过程中,会确保字节不会读入到用户内存中,不必进行缓存池的管理;
- 恢复:因为系统和机器会出现宕机,磁盘上的数据也有可能会损坏,所以有必要实现恢复(recovery)的功能。在启动的时候,存储层会从最后一个已知的检查点读取 log,并重建索引。恢复也有助于重建内存中的状态。Log 是恢复的来源,并且会永久保存;
- 复制:存储节点还需要维护分区中各副本的同步。每个节点上都会有一个复制服务(replication service),它会负责保证本地存储中的副本与所有的远程副本是同步的。在这里,进行了很多的优化,以保证复制过程的高效可靠。
路由 / 前端
前端服务器提供了 HTTP 接口,供客户端与之通信。除此之外,它们还会负责为 CDN 设置正确的头信息、进行安全校验,并将对象以流的形式返回给路由库和客户端。
路由所负责的功能如下所示:
- 请求管理:请求的端到端生命周期是由路由来进行管理的。路由会处理 PUT、GET 以及 DELETE 请求。对于其中的每个请求类型,路由都会跟踪副本成功和失败的数量从而确定 Quorum 的值、维护分块的状态、生成对象 id 并在成功或失败的时候触发对应的回调;
- 分块:大对象会分解为块(chunk),每个块都能够跨分区独立地进行路由。每个块都会有一个 id 来进行唯一标识。路由会生成一个元数据对象,其中包含了块的列表以及它们所需的获取顺序。元数据对象存储为独立的 blob,它的 id 也会作为 blob 的 id。在读取的时候,会得到元数据对象,然后检索各个块并返回给客户端;
- 故障检测:故障检测的逻辑要负责主动识别宕机或状态出问题的资源。资源可以是机器、磁盘或分区。路由会将出现问题的资源标记为不可用,这样后续的请求就不会使用它们了;
- Quorum:Ambry 为写入和读取实现了一种多主人(multi-master)的策略。这能够实现更高的可用性并减少端到端的延迟,这是通过减少一个额外的 hop 来实现的,在基于主从结构(master slave)的系统中,往往会有这个额外的 hop。请求通常会发往 M 个副本,然后等待至少 N 个成功的响应(这里 N<=M)。路由会优先使用本地数据中心的副本,向其发送请求,如果本地存储无法实现所需的 Quorum 的话,它会代理远程数据中心的访问;
- 变更捕获:在每次成功的 PUT 或 DELETE 操作之后,路由会生成一个变更捕获(change capture)。变更捕获中所包含的信息是 blob id 以及 blob 相关的元数据,这个信息可以被下游的应用所使用。
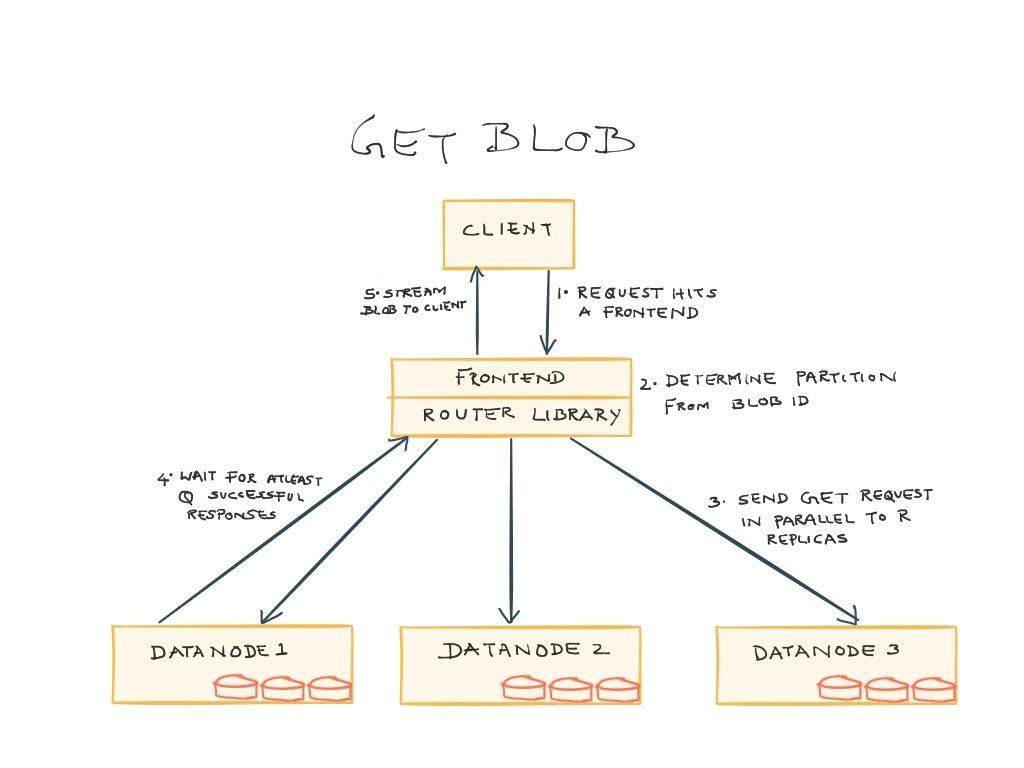
在路由中,典型的 PUT 和 GET 操作的流程分别如下所示,系统的实际运行过程会比下述的描述会更复杂一些:
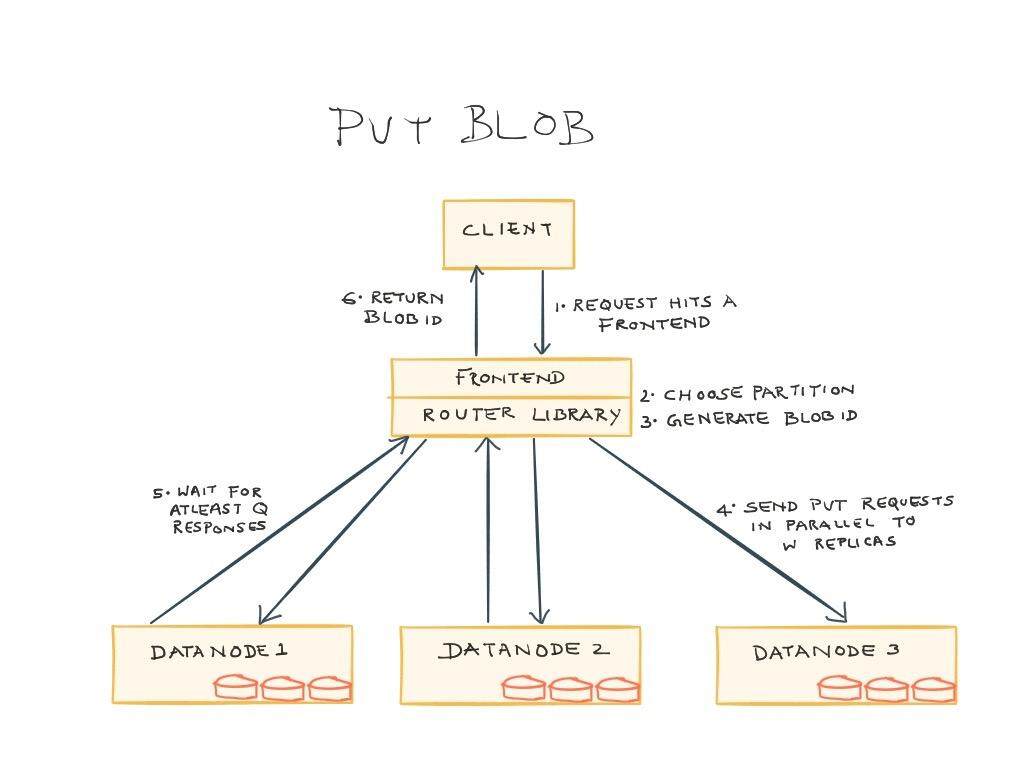
- PUT 操作:客户端会将对象以及一些元数据信息以流的形式发送到前端,当流到达时,前端会将对象进行分块、选择可用的分区、为 blob 或分块生成 blob id,并将请求分发给 W 个副本。然后,前端就开始等待至少 Q 个成功的响应(Q<=W),等到之后,会将 blob id 返回给客户端。如果无法达到足够的 Quorum,那么前端会报告一个错误。当然,Ambry 也实现了当 Quorum 失败的时候,选择另外一个分区的功能,从而提升可用性。
- GET 操作:客户端通过将 id 发送给前端来请求某一个 blob。前端会根据 id 来确定分区,并在数据节点中检索 blob 相关的块。对于每个块,前端会并行发送 R 个请求,在将 blob 或分块发送给客户端之前,前端会等待 Q 个成功响应(Q<=R)。
解决运维的难题
分布式系统最困难的在于它的运维,在这个过程中,需要工具、度量并且要进行广泛地测试,从而保证所有的事情都能符合预期。在这个过程中,Ambry 积累了很多的工具和实践。
- Simoorg:为了模拟各种故障,他们孵化并开源了 Simoorg 。这是一个分布式的故障引入系统,能够在集群中引入各种故障,如 GC 暂停、磁盘错误、节点宕机以及网络故障,从而校验在各种情况下,系统的正确性,有助于预先发现并修正严重的缺陷;
- 生产环境的正确性测试:当新版本部署到集群中的部分机器进行验证时,可以进行正确性测试,从而保证生产环境的健康状态。通过加压访问所有可用的 API(组合使用各种可能出现的输入参数),确保结果的正确性;
- 审计:当新的 blob 写入到磁盘时,都会产生复制事件,这个事件包含了 blob 的信息以及事件的来源。所有存储节点的事件都会聚集到 Hadoop 中,这样就能审计是否所有的副本都进行了写入。目前该系统并不是实时的,不过,Ambry 规划会构建一个实时的审计系统。
除此之外,Ambry 还实现了指标和告警工具,用来帮助识别系统中的异常行为以及维护集群的管理工具。
迁移工作是如何进行的?
团队需要将所有的媒体内容从遗留系统迁移至 Ambry,在这个过程中还要服务于所有的流量,不能出现任何的宕机时间。除此之外,团队还面临着多项 deadline,了解 Ambry 是如何组织研发和部署的,对我们会有一定的指导意义:
- 当时,公司正在将所有的服务从 Spring RPC 方案中剥离出来。从构建 Ambry 开始计算,团队有四个月的时间支持新的 API 并移除 Spring RPC;
- 一个新的数据中心正好需要搭建,Ambry 团队并不想再去部署遗留系统了,因为这会带来很高的成本。这同时也就意味着为了避免部署遗留系统,需要在八个月内完成 Ambry;
- 最后,团队希望在数据中心里面移除掉 Solaris 的方案,遗留系统是运行在 Solaris 上的,它的 deadline 是一年。
Ambry 团队采用了一种特殊的方式来达到这些里程碑节点。首先,构建前端并使用它来代理所有对旧系统的请求,然后再将所有的客户端迁移到新的前端上。这虽然费了很大的功夫,但是确保了第一个 deadline 目标的达成。
第二步是让 Ambry 能够以端到端的方式运行,并且只将其部署到新的数据中心上,然后将所有的数据从旧系统迁移至 Ambry。在代码中,添加了一定的逻辑,确保如果新数据中心发生故障的话,将会使用旧的系统。这可能会产生更多的延迟,但是团队决定承担这个风险。
在新数据中心搭建完成之后,在接下来的几个月里,团队不断运行并稳定 Ambry。基于测试和审计结果,当对新系统完全自信的时候,团队决定停掉遗留的系统。这样就在一年的 deadline 之内完成了目标。
在接下来的一年中,Ambry 成为了 Linkedin 中媒体内容的唯一来源。它的成功要归因于周密的规划以及渐进式的基础设施研发。
Ambry 是如何适应 Linkedin 的生态系统的?
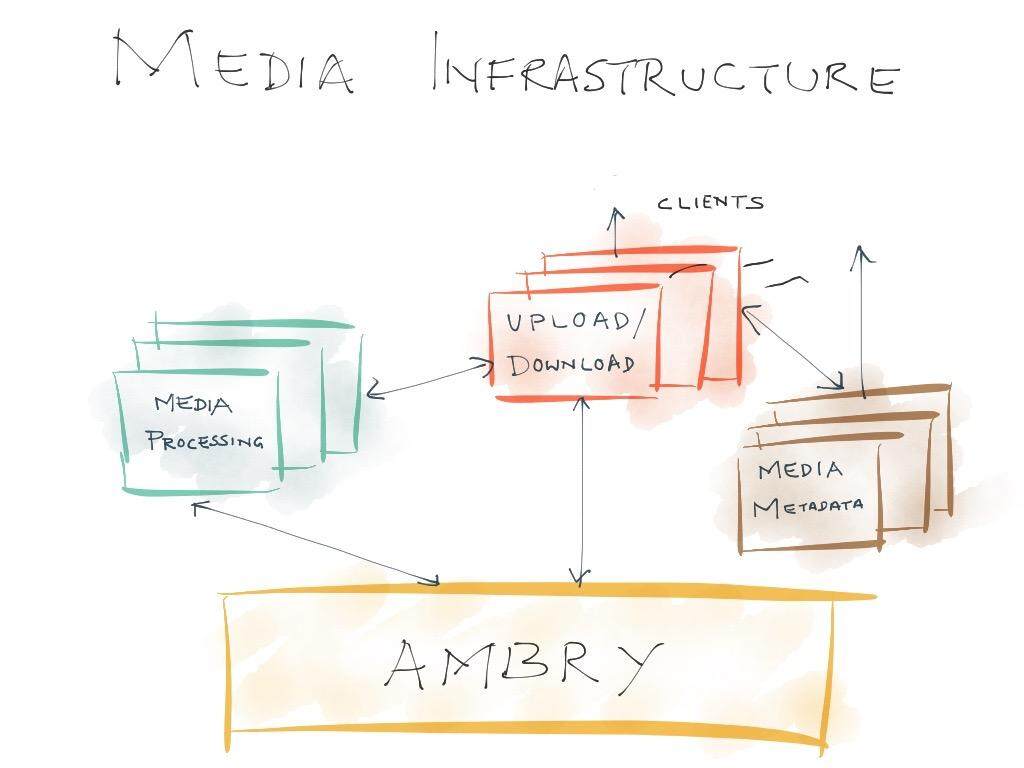
媒体基础设施是针对媒体内容的端到端管道,涉及到上传、存储、处理、元数据管理以及内容下载。在基础设施中,Ambry 是很重要的一个环节,基础的稳固是非常重要的。在 Ambry 就绪之后,就可以围绕着它进行扩展并关注生态系统中的其他组成部分。
下一步的研发计划
目前,Ambry 主要进行中的任务包括在前端和路由层实现非阻塞、存储节点实现机架感知等功能。团队希望不断地为 Ambry 添加新的特性,并且构建活跃的开源社区。完整的未来工作计划列表可以参见 Github 上的相关页面,如下列出了当前正在进行的或者可能会开展的项目:
- 非阻塞:阻塞类型的请求通常会占用一个进程,直到请求结束并且不支持管道。为了达到更高的吞吐量,并且避免大对象所造成的资源枯竭现象,需要将路由和前端变成完全非阻塞的。这样的话,就能支持更大吞吐量,在操作执行时,不再受限于线程资源,从而能够实现更好的可用性。目前,前端实现已经完成,正在进行测试。路由库的代码预计也将会很快完成,可以参考其 repository 来了解最近的更新情况;
- 机架感知:现代的数据中心为了降低成本都将机架切换视为很重要的因素。这意味着软件要足够智能来应对切换故障。Ambry 正在构建的一项功能就是确保新分区的副本在跨数据中心存放时,能够遵循机架感知的方式。目前,该项工作正在进行之中;
- Bucket/Container:Ambry 尚不支持命名空间的概念。如果要在群组的级别上强化控制的话,那命名空间是非常有用的。在 Ambry 中,可能将会引入 Bucket 或 Container 的理念。这有助于在 bucket 级别上定义用户群组、访问控制和配额,这种方式会比在对象级别进行维护容易得多;
- 安全:Ambry 目前支持数据节点之间的加密,在前端和数据节点之前的通信也可以启用加密功能。不过,在安全方面,Ambry 会有更多的进展,包括 REST 级别的认证、授权以及对加密的支持。该项功能预计会在 Bucket/Container 实现完成之后开展。
对于社区来讲,这个系统会有很大的用处,有助于支持媒体内容的实时上传和媒体服务的构建,详细的文档可以参见 Github 上的相关页面。如果读者有反馈意见或有志于为该项目做出贡献的话,可以参考其开发指南。Ambry 团队希望该项目的开发能够保持开放的状态,并帮助社区使用它来构建应用程序。另外值得一提的是,2016 年度的SIGMOD(Special Interest Group on Management Of Data)已经接受了一篇关于Ambry 的论文,该会议将会在六月份举行,可以浏览其网站了解更多信息。
查看英文原文: Introducing and Open Sourcing Ambry
感谢李建盛对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




