在 Skipjaq ,我们关注应用在最高可持续负载状态下的性能表现。在此状态下,应用的负载不至于过饱和乃至崩溃,但也没有丝毫空闲,可以说是该应用性能最真实的体现。我们尤其关注的是,应用在临近极限情况下会产生怎样的延时。
在最近的一次有关 Web 应用延时的团队讨论当中,我提到一个通用准则:延时在服务利用率(utilisation)超过 80% 之后会呈现明显的恶化。再说得确切一点,是服务等待时间(wait time)的恶化导致了延时(latency)的恶化。
John D. Cook 为此撰写过一篇很长的文章进行说明,不过我想再补充一些更深入的说明,以便于没接触过队列理论(queuing theory)的读者们理解。
服务即队列
80% 这个数字来自于队列理论。首先,我们看一下为什么 Web 应用服务符合队列理论的模型。
假设我们正要测量一个 Web 应用(服务)的延时,该应用运行在单台服务器上。请求到达服务并被处理掉。如果在一个新请求进入的时候,该服务仍然在处理之前的其他请求,则新请求就需要排队等待。出于简化的考虑,我们假设该队列可以无限延长,并且任何进入队列的请求都仅在服务完成其处理之后才离开队列。
对于本场景而言,最简单的队列模型是 M/M/1 模型。M/M/1 是 Kendall 标记法,此处的通用形式是 A/S/c,其中 A 代表到达过程,S 代表服务时间分布,c 代表服务器的数量。
在本处简化的场景中,我们只有一台服务器,所以 c = 1。模型中的 M 代表马可夫(Markov)。马可夫式的到达过程描述了一个泊松过程:每两个请求到达的间隔时间呈指数分布,其参数为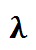 ;马可夫式的服务时间分布也描述了一个泊松过程:完成一次服务的时间呈指数分布,其参数为
;马可夫式的服务时间分布也描述了一个泊松过程:完成一次服务的时间呈指数分布,其参数为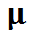 。
。
队列利用率
我们所说的服务利用率,其定义为:服务用于处理请求所花费的时间百分比。对于上述M/M/1 队列而言,服务利用率的计算方式为:
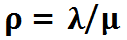
队列在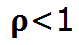 时处于稳定态,这符合直觉:如果单位时间内的新增请求数大于被处理完毕的请求数,则队列将会无限延长。
时处于稳定态,这符合直觉:如果单位时间内的新增请求数大于被处理完毕的请求数,则队列将会无限延长。
延时的计算
利特尔法则是从队列理论推演出的最有趣的结论之一。简单来说,在一个稳定系统当中,客户的平均数量(L)等于其到达率(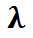 )与每个客户在系统中平均耗时(W)的乘积:
)与每个客户在系统中平均耗时(W)的乘积:

对于每一位客户而言,其在系统中的平均耗时就相当于是该客户所感受到的延时。该数值由服务时间和等待时间两部分组成。直觉上,平均服务时间基本上是固定的,所以延时的变动主要取决于等待时间的变动。
我们现在关心的是延时,所以让我们把公式转换到另一边:
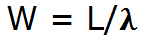
也就是说,如果我们知道系统中的平均客户数量,我们就能够计算出等待时间。在一个M/M/1 队列中,客户数量的平均数的计算方式为:
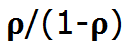
具体的推导过程不在本文中赘述,感兴趣的读者可以参阅这篇文章。
上面说过,服务利用率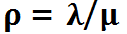 ,所以:
,所以:
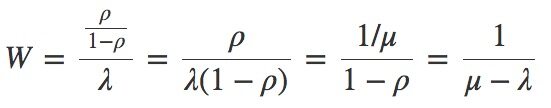
这样,我们就有了一个有关延时与到达率、服务完成率之间关联性的简化公式。现在我们进一步想要得到延时与利用率之间的关联公式,这就需要套用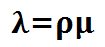 到上面的公式中:
到上面的公式中:
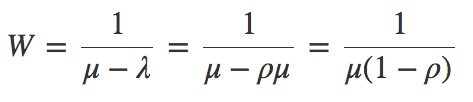
综上所述,我们已经假设服务时间是固定的,即: 是常量。所以,延时与
是常量。所以,延时与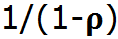 成比例关系。将该公式画成图表:
成比例关系。将该公式画成图表:
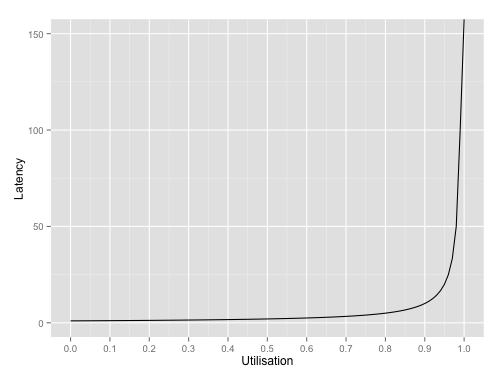
可以明显看到延时在利用率超过80% 之后就开始飙升。利用率越接近100%,延时越倾向于无限大。
结论
延时在服务利用率超过80% 之后迅速恶化。所以为了避免在生产环境手忙脚乱的处理延时问题,我们应当监控系统利用率,确保其不超过80% 的危险范围。
给系统进行性能测试的时候,让系统负载到80% 以上的结果往往都是延时无法达标,而让系统负载到接近100% 则意味着你要等很久才能拿到测试结果!




