数据分析师都想使用数据库作为数据仓库处理并操作数据,那么哪一款数据库最合适分析师呢?虽然网上已经有很多对各种数据库进行比较的文章,但其着眼点一般都是架构、成本、可伸缩性和性能,很少考虑另一个关键因素:分析师在这些数据库上编写查询的难易程度。最近,Mode 的首席分析师 Benn Stancil 发布了一篇文章,从另一个角度阐释了哪一款数据库最适合数据分析师。
Benn Stancil 认为数据分析工作不可能一蹴而就,分析师在使用数据库的过程中阻碍他们速度的往往不是宏观上的性能,而是编写查询语句时的细节。例如,在 Redshift 中如何获取当前时间,是 NOW()、CURDATE()、CURDATE、SYSDATE 还是 WHATDAYISIT。在 Mode 公司,分析师每天都会使用各种不同的语言编写几千个查询,运行在 Mode 编辑器里的查询超过百万个,而 Benn Stancil 就是从这些数据出发,对 MySQL、PostgreSQL、Redshift、SQL Server、BigQuery、Vertica、Hive 和 Impala 这八款数据库进行了比较。
首先,Benn Stancil 认为查询错误是否容易解决是衡量数据库的一个最基本指标。数据库提供的错误信息(通常是语法错误、函数名错误、逗号错位等)最能表明该系统是否会对数据分析师造成极大的挫败感。通过对 8 种数据库查询错误频率的比较,Benn Stancil 发现 Vertica 和 SQL Server 错误率最高,MySQL 和 Impala 最低,如图所示:
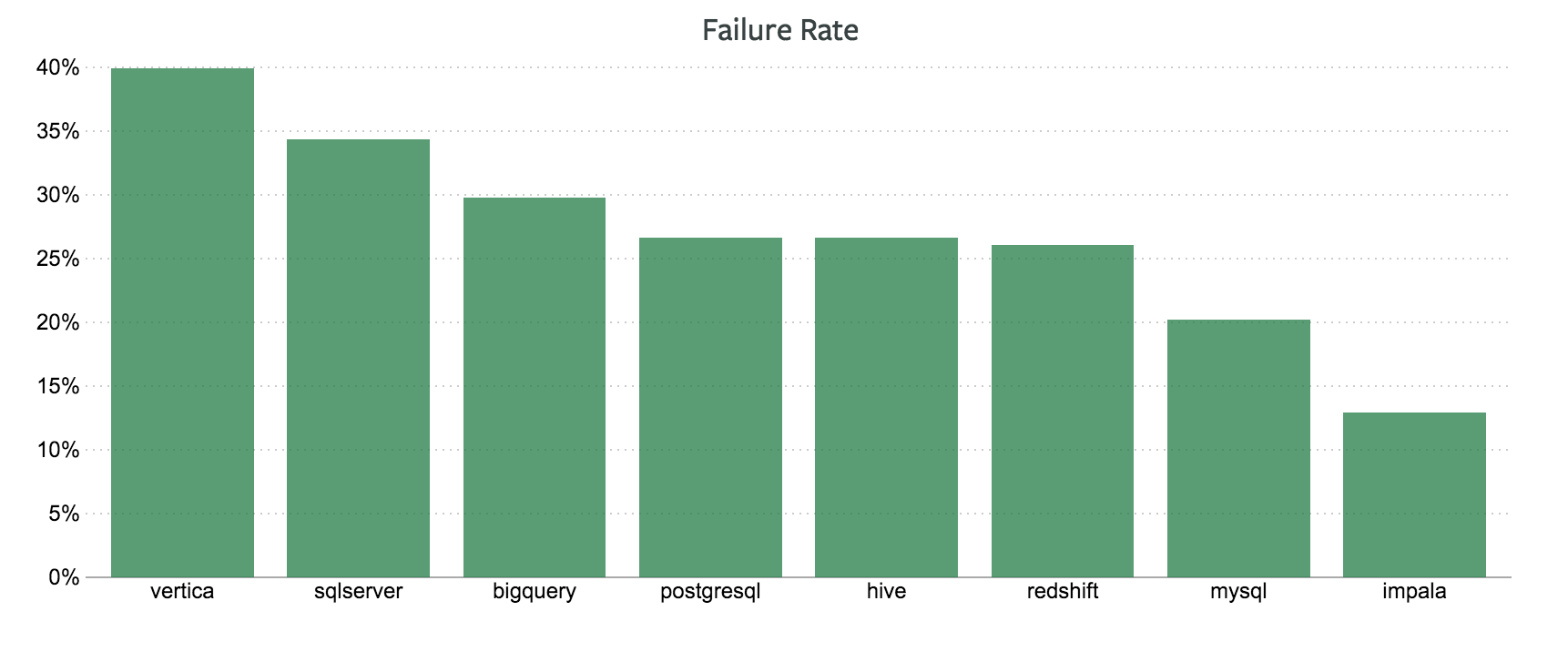
但是,对于该结果 Benn Stancil 认为可能有点不严谨,因为 Impala、MySQL 和 Hive 是开源的免费产品,而 Vertica、SQL Server 和 BigQuery 不是,后三者的用户通常是有充足分析预算的大型企业,其较高的错误率很有可能是由于使用更深入而不是语言“更难用”。
除了错误率之外,Benn Stancil 还讨论了复杂性。虽然不同语言其查询长度、查询复杂性和语言复杂性之间的关系盘根错节,要界定清楚很难,但可以间接使用查询长度作为度量的指标,因为一门语言之所以简单很有可能是因为它简洁。这八种数据库查询长度的统计结果如下:
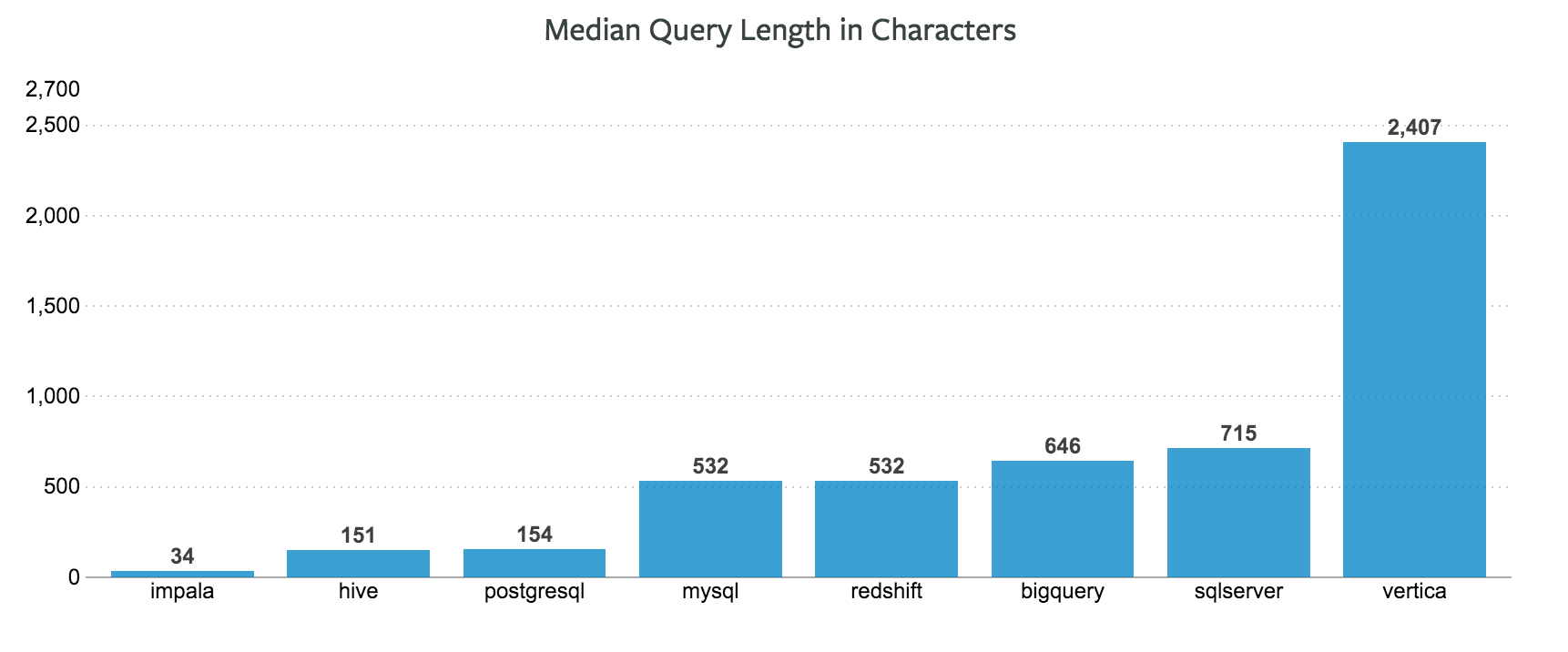
如果说单纯地比较最终的长度有失偏颇,那么可以看看随着分析的逐步深入,查询逐渐变复杂的过程中,其修改次数与长度之间的关系:
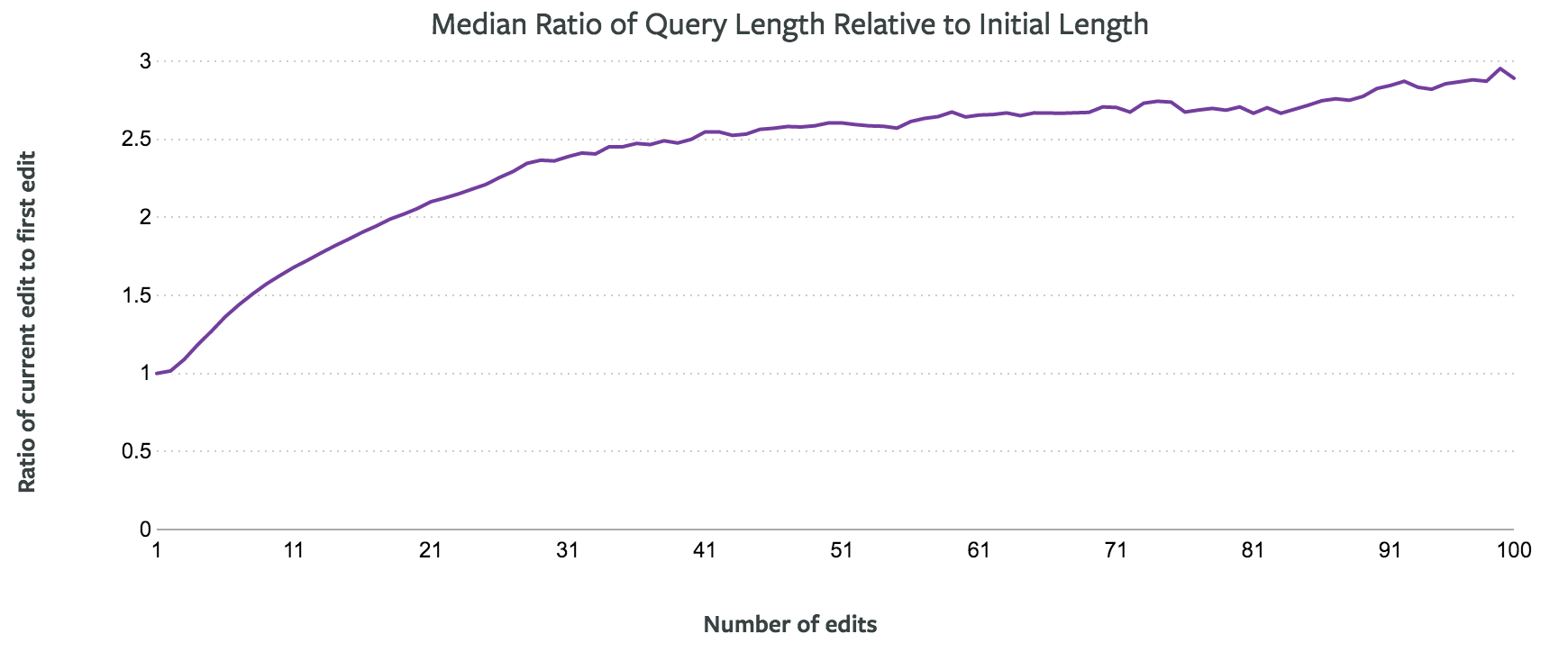
该图显示,经过 20 次左右的编辑之后,查询长度通常会变为之前的 2 倍,而在 100 次编辑之后,长度会变为之前的 3 倍。那么在修改的过程中,其编辑次数与出错的比率又是什么样子的呢?
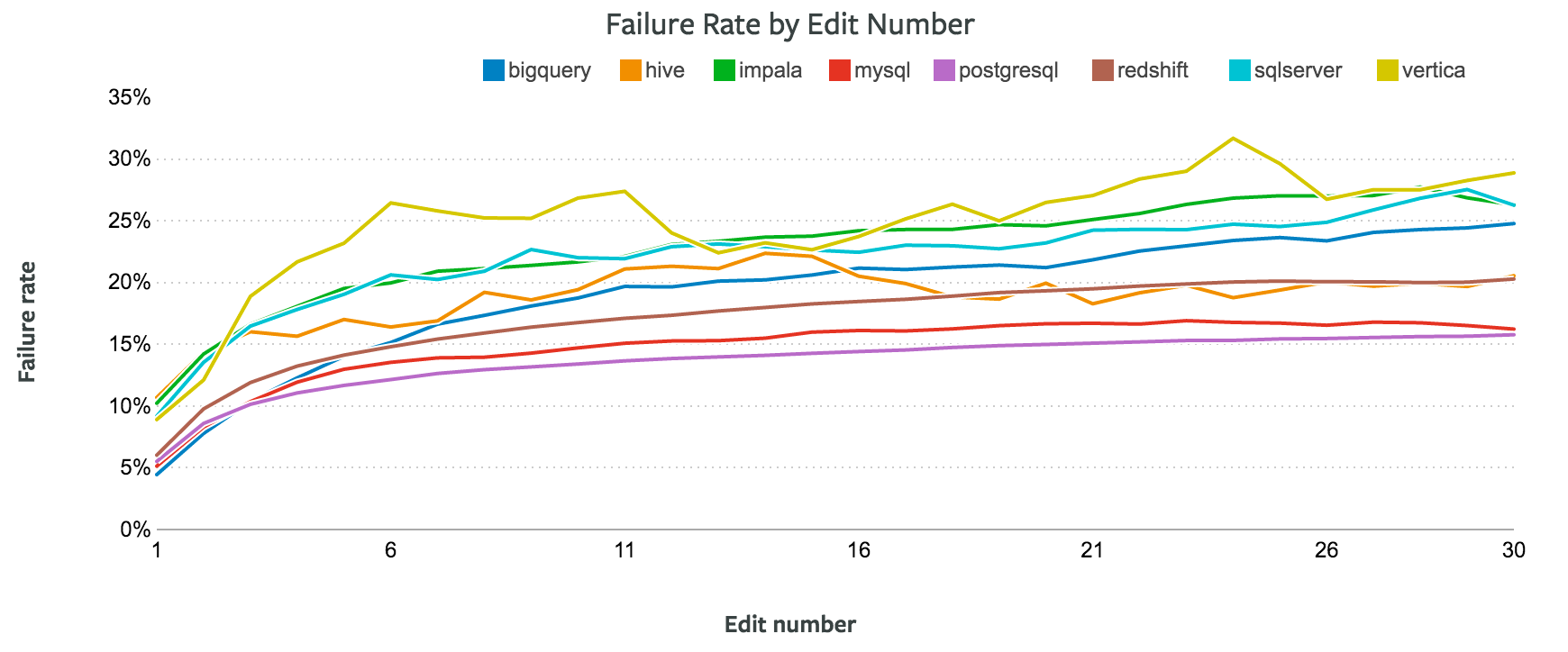
从图中可以看出,PostgreSQL、MySQL 和 Redshift 的错误率较低,Impala、BigQuery 和 SQL Server 的错误率较高。另外,和之前一样,Vertica 的错误率依然最高。
此外,Benn Stancil 认为分析师的技能也很重要。他对使用多个数据库并且在每个数据库上至少运行了 10 个查询的分析师进行了统计,计算了这些分析师在每个数据库上的查询错误率,并根据统计结果构建了下面的矩阵:
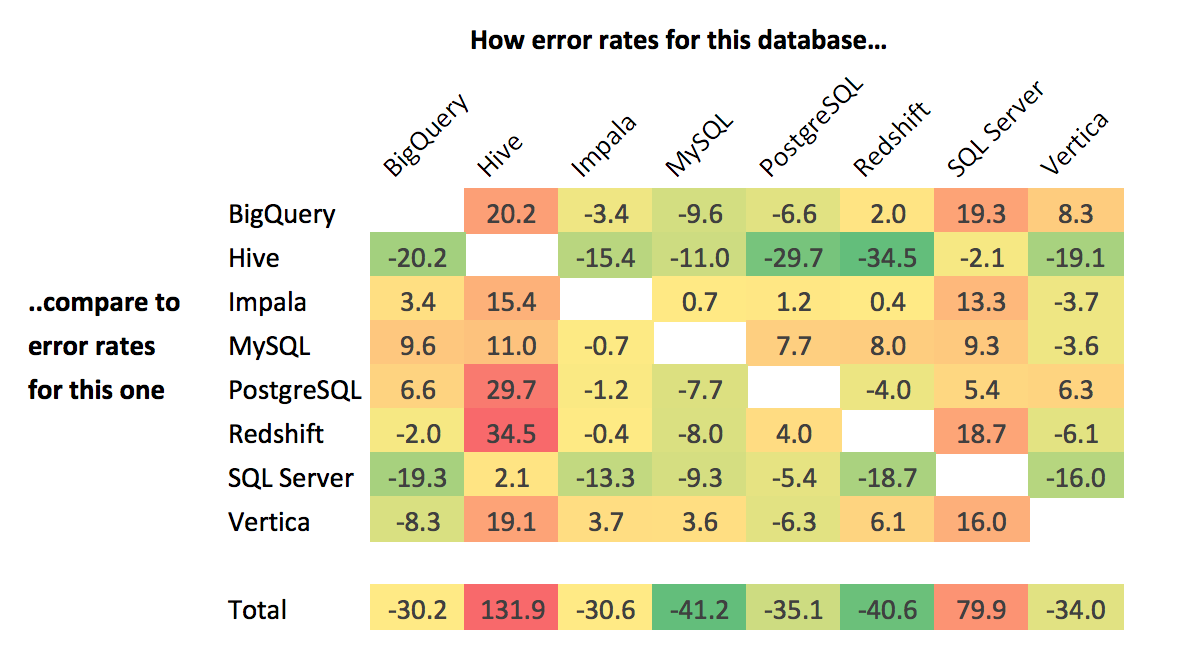
该矩阵展示的是顶部数据库与左边数据库相比其错误率的差别,数值越高表现就越差。例如,Hive 和 BigQuery 交叉处的“20.2”表示:对使用这两款数据库的分析师,其使用 Hive 的错误率要比使用 BigQuery 高 20.2。最底部的 Total 行是结果总计,从中可以看出 MySQL 和 PostgreSQL 始终表现较好;Vertica 跳跃最大,几乎是从最底部跳到了中游,打败了 SQL Server 和 Hive,这也暗示了 Vertica 的高错误率很可能是由于分析师的能力而不是语言本身。
最后,Benn Stancil 认为在分析的这 8 个数据库中,MySQL 和 PostgreSQL 编写 SQL 最简单,应用也最广泛,但与 Vertica 和 SQL Server 相比它们的特性不够丰富,而且速度要慢。综合各方面的因素,Redshift 或许才是最好的选择。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




