通常,人们提出的问题反映了人们在一个特定的时期内最感兴趣的内容。这可以是新近上映的电影的情节,也可以是对即将到来的总统大选的预测。近日,Quora 数据科学家陶雯雯撰文介绍了他们如何运用自然语言处理(NLP)技术从提交到 Quora 的问题中挖掘用户感兴趣的内容。他们的主要研究成果如下:
- 识别特定时期内与当时事件紧密相关的单词,其中的主要挑战是处理问题集中的自然语言数据。通过选定恰当的问题集合,并关注特定词性的单词,他们使用标准 NLP 技术 TF-IDF 获得了一个令人信服的单词集合。
- 综合运用专门为自然语言数据而设计的统计检验和基于图的聚簇技术,他们可以发现能够强有力地代表特定 Quora 历史时期的单词语境。这样,关于一个单词为什么对于特定的历史时期而言非常重要,他们就能够自动提取更多的信息。
- 他们还能够识别出这些语境如何随时间演进,而这可以让他们从 Quora 的讨论中看到更广泛的世界中人、企业和事件的关系。
本文接下来将分别介绍上述三个方面的内容。
按季度识别最有代表性的单词
由于他们最感兴趣的内容是提问者所提的问题是关于什么主题的,所以他们使用词性标注来过滤问题文本中的关键词,并且只保留名词。此外,考虑到不同国家的人有不同的背景、文化和兴趣,他们根据提问者的国籍划分了问题集合。
选取最有代表性的单词有许多方法,最简单的是根据词频排序,但这种方法无法排除常用词。为此,他们选择了 TF-IDF 方法。在具体实现上,TF 为单词在特定国家特定季度的非匿名问题中出现的次数,IDF 为单词在特定国家所有问题中出现的次数,减去该单词在特定国家特定季度的非匿名问题中出现的次数,公式如下:
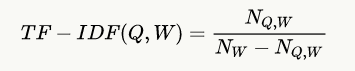
其中,Q 表示特定季度,W 表示特定单词。
该方法可以提供合理的结果,但为了提高所识别出的单词和当时事件的相关性,他们对识别出的单词进行了进一步的过滤。例如,只保留在特定季度里被三个提问者使用过的单词。另外,去掉 NLTK 中定义的停用词以及在 NLTK Brown 语料库中出现超过 10 次的单词。下图是进一步过滤排序后生成的一个“单词云(word cloud)”示例:

(美国,2011 年第 2 季度)
在 2011 年,Quora 刚刚在硅谷成立,最具代表性的单词大多数与重大技术和政治事件相关。例如,近场通信(NFC)服务推动了移动支付的广泛应用,人们在预测 Groupon、Zynga 和 Yelp 的 IPO,等等。
代表性单词的语义语境
对于单词云中的单词的代表性,有的很容易解释,有的并不明显。为此,他们基于单词共现频率设计了一种自动提取单词语境的方法。与生成单词云的过程相比,他们使用了一个更大的单词集合:去掉了停用词,但并没有去掉名词之外的其他单词,也没有限制单个提问者使用某个单词的次数。他们按照如下条件对单词对进行了过滤:
-
最少共同出现了 4 次;
-
共现次数超期望值,即
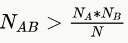
-
随机共现的概率小于 5%。
其中,为单词 A 和 B 实际的共现次数,N 为非匿名问题的数量,()为出现单词 A(B)的问题的数量。使用这些规则,他们构建了一个图,顶点表示单词,边连接满足上述条件的单词对。对于每条边,他们使用下面的公式赋予一个权值:
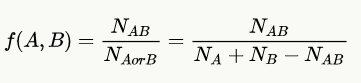
通过这种方法,他们识别出图的连通部分,并命名为“语义簇(semantic clusters)”。那些包含最有代表性单词的语义簇是他们重点关注的。下图是一个语义簇示例:
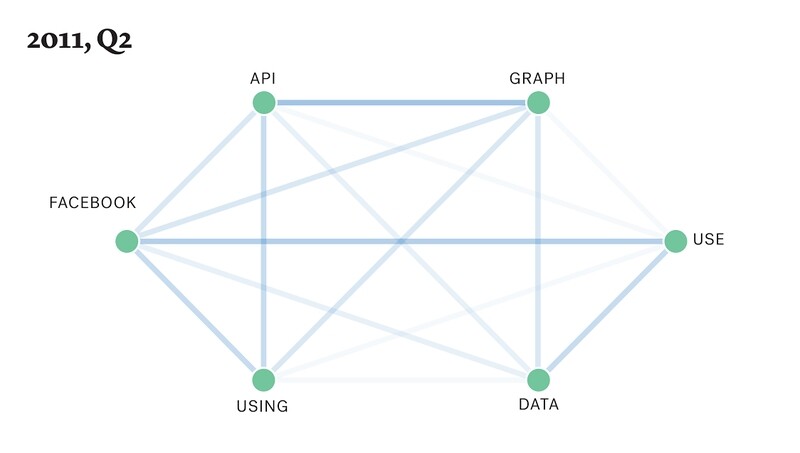
(美国,2011 年第 2 季度)
该语义簇表示,Facebook 在 2011 年 6 月推出了研究 Facebook 社交图谱的工具 Graph API Explorer 。
单词关系随时间演进
在生成单词语义簇之后,他们进一步研究了单词语境随时间的演进。他们从多个季度中选取了最具代表性的单词,他们称为“关注词(focus word)”。对于每个单词 A 及每个与 A 关联的单词 B,他们使用前文定义的 f(A,B)计算两者在 2012 年到 2015 年之间不同季度里的共现频率指标。接下来,他们就使用这些值分析单词之间关联关系随时间的变化情况。下图是一个单词语境演进示例:
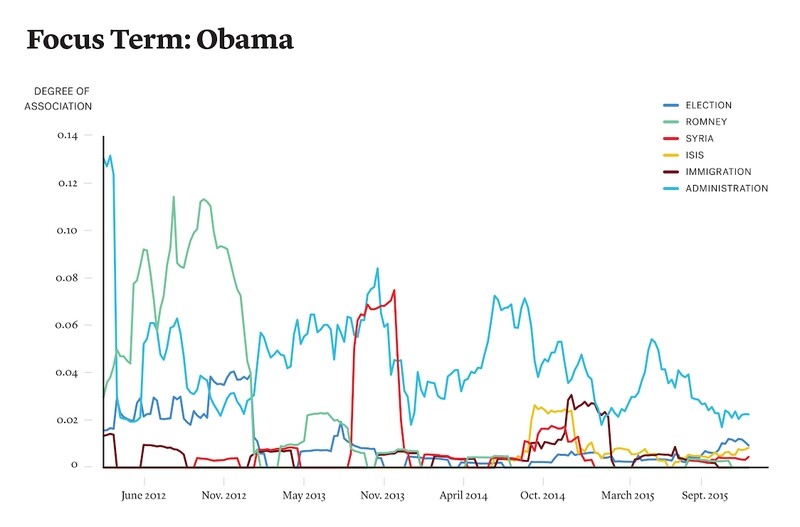
(关注词:Obama)
可以看出,在 2012 年总统大选之前,Barack Obama 经常和 Mitt Romney 一起被提及,而在 2013 年 8 月前后同 Syria 相关的问题更显著了。
总之,他们使用 NLP 技术分析问题文本,提取最有代表性的单词,并使用单词云的形式将它们可视化。然后,他们使用语义聚簇方法识别出相关度较高的一组组单词,即语义簇。最后,他们分析了一个单词的语境如何随着时间变化。更多示例和参考文献,请查看原文。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




