
镜像是 Docker 项目最大的创新点之一,所有的 Docker 容器都源于镜像。不可否认镜像存储是 Docker 工作流中的重要一环,Docker Registry 是官方提供的开源项目用以保存镜像,同时它也提供了后端存储系统来解决镜像的落地问题,比如 Local Filesystem、S3、Swift。 Speedy 是由京东开源的一个分布式镜像后端存储系统,在架构设计上更好的解决了扩展性和可用性的问题。就 Speedy 项目的更多细节,InfoQ 采访了其负责人田琪。另外,田琪也是也是全球架构师峰会北京站 2015《云服务架构探索》专题的出品人。
受访嘉宾介绍
田琪,京东资深架构师。10 年互联网行业从业经验,分别就职于搜狐、新浪、腾讯、京东等公司,目前负责京东云主机及云数据库的架构及研发工作,曾在新浪微博负责新浪微博的底层平台研发工作,主导了Redis 在新浪微博的大规模定制开发与应用。之后加入腾讯负责腾讯大规模分布式存储项目的研发与架构工作,为腾讯众多业务产品线提供高可靠的存储服务。
InfoQ:能否介绍下你们的 Docker 镜像存储系统 Speedy?为什么要做 Speedy?
田琪:我们通过 Docker 搭建了我们的弹性计算云平台,服务于公司内外各项业务。在搭建整个平台过程中遇到了很多问题,存储是其中一项待解决的问题。Docker 官方提供了 Docker Registry 服务,但是最终的镜像文件落地存储并没有提供,目前支持的第三方存储服务主要是 S3、Swift 等。
我们也调研了一些开源分布式存储项目。发现主要存在几个问题:一是架构上倾向于无中心,或者一致性哈希等方式管理存储节点,运维方面我们比较担心可控性问题,另外增减机器都需要涉及文件数据的迁移,不利于线上系统稳定。二是大多开源方案都没有提供高性能的存储引擎,即只提供了数据分布的算法,但数据落地没有提供存储层的优化,这样产生大量文件时就会存在性能问题。三是针对大文件没有特别的优化措施。
认识到这些问题后,我们决定自己研发分布式存储系统,来解决和优化上述的问题。
InfoQ:能否介绍下 Speedy 整体的后端流程和逻辑?
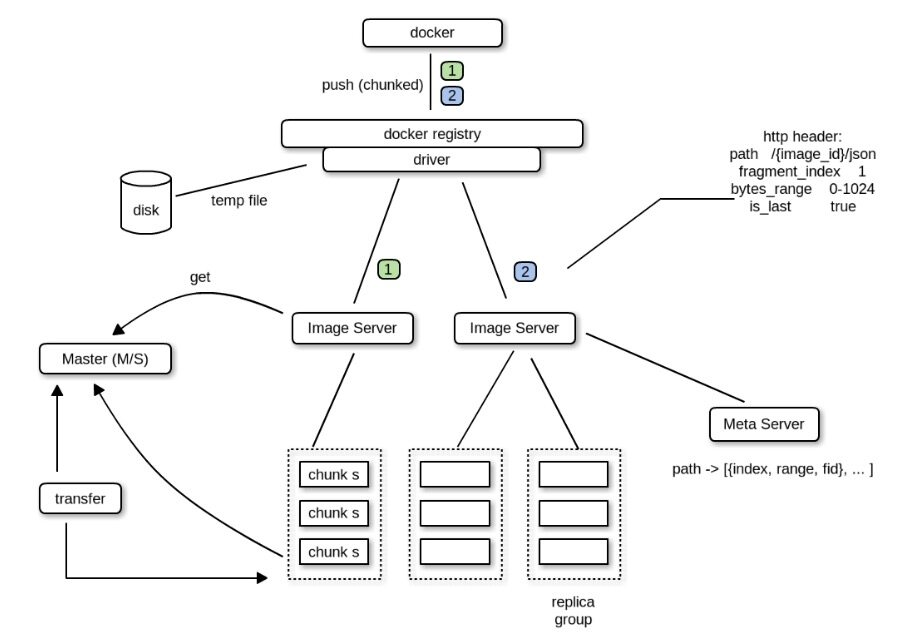
田琪: Speedy 架构如下图:
Speedy 本身主要涉及模块:
- Docker Registry Driver
- ChunkMaster
- ChunkServer
- ImageServer
Docker Registry Driver 是一个遵照 Docker Registry 1.0 协议实现的驱动,完成 Docker Registry 与后端存储系统的对接工作。ChunkServer 与 ChunkMaster 组成了一个通用的对象存储服务,ChunkMaster 是中心节点,缓存了所有 ChunkServer 的信息,ChunkServer 本身是最终镜像数据落地的存储节点,多个 ChunkServer 会构成一个组,拥有唯一的组 ID,上传这个组内的所有 ChunkServer 都成功才算成功,下载可以随机选择其中一个节点下 载。
ImageServer 本身是一个无状态的 Proxy 服务,它相当于是后面通用对象存储服务的一个接入层,Driver 发起的镜像上传、下载操作会直接发给 ImageServer,ImageServer 中缓存了 ChunkMaster 中的存储节点信息,通过这些信息,ImageServer 会进行 ChunkServer 节点的选择操作,找到一组合适的 ChunkServer 机器完成镜像的上传或下载操作。
上传流程
首先我们通过
docker push命令发起上传镜像的操作,Docker 本身会进行多次与后端存储系统的交互(这里我要简单吐个槽,合理的情况是这个结构化数据和非结构化数据分开存储,Docker 本身用 JSON 表示结构化的描述信息,也是上传到后端存储系统的,个人觉得 Docker 的元数据管理方面很混乱),最后一次交互是上传镜像的 layer 数据到 Docker Registry。如果使用默认的本地存储,Docker Registry 就直接把数据写到了磁盘上,我们这里通过自己实现的 Driver 完成与后端对象存储系统的上传工作。
我们的 Driver 首先会对源源不断上传过来的字节流进行切割,按照配置的固定大小并发上传到 ImageServer 中,并在上传的 HTTP 请求中携带了该分片的索引及位置信息。
ImageServer 在收到该分片上传请求后,根据自己从 ChunkMaster 中同步过来的 chunk 信息来动态选择一组 ChunkServer,并将分片上传到该组 ChunkServer 中的所有实例上,都成功才返回成功。并将分片索引位置信息及上传成功返回的文件 ID 提交给 MetaServer 保存 Driver 在收到所有分片的上传成功返回后,再返回给前端 Docker,整个上传流程结束。
下载流程
首先 Docker 通过
docker pull请求下载镜像,同样在真正下载数据开始前,Docker 同 Docker Registry 以及后端的存储系统间也会产生多次的数据交互,这里省略,最后一步是下载对应的 Image Layer 数据。Docker Registry 在收到下载请求后首先通过 ImageServer 从 MetaServer 里获取到该文件 path 对应的分片信息,主要是分片的个数,及每一片的索引,然后将这些分片下载请求并发的发送给 ImageServer 服务器。ImageServer 收到分片下载请求后,查询 MetaServer 获得对应的文件 ID,该文件 ID 中包含有 ChunkServer 的位置信息,随后请求相应 ChunkServer 下载数据并返回给 Driver。Driver 收到分片下载的数据后,会根据分片的位置索引进行 排序,按文件分片顺序返回给 Docker。
InfoQ:相比来说,Speedy 有哪些优势?
田琪:我们系统设计主要考虑几点:
- 架构倾向于简单、可控、容易部署
- 提供 Linux C 编写的高效存储引擎,存储上将多个小文件合并成一个大文件存储,减少元数据 存储空间开销和性能开销,同时在原生文件系统上通过预分配空间方式,提供接近裸盘的读写性能,但兼具原 生文件系统的易用性。
- 针对大文件做优化,提供断点续传、失败重试等功能。
InfoQ:Speedy 的官网提到目前已经支持 Registry 1.0,接下来有没有计划支持 2.0?
田琪: Registry 2.0 主要是针对安全和性能方面做了一些改进,具体可以参考 GitHub 上的说明。目前已经可用。Speedy 项目已经给官方提交了针对 Speedy 的 Registry 2.0 的驱动,正在等待官方合并。
InfoQ:Speedy 的性能如何?
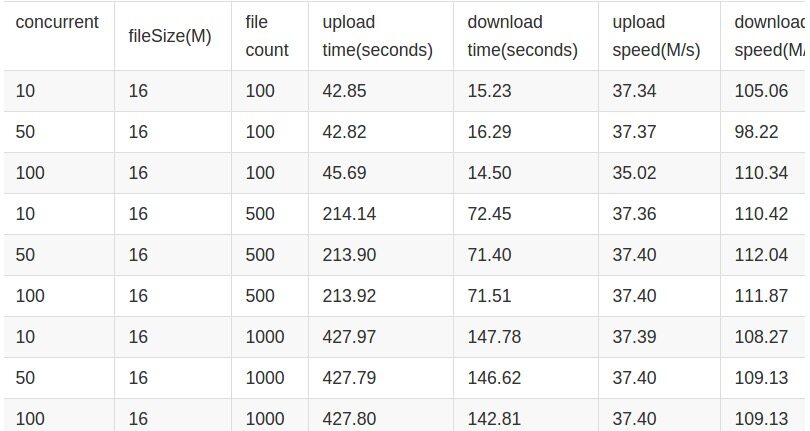
田琪: Speedy 提供了高性能的存储引擎,整体系统的瓶颈在于网这一层,我们的测试数据如下,可以看到在千兆网络环境下,上传和下载都达到了网卡的性能瓶颈而不是存储本身,上传是下载性能的 1/3,原因是由于上传是三副本的原因,后续我们考虑引入 Erasure Code 的方式,仍有性能提升空间。
InfoQ:Docker Registry 的单点问题,你们有好的解决方案吗?
田琪:我们在线上部署是通过无状态部署多点的方式来解决 Registry 单点问题的,Docker Registry 1.0 服务本身内部没有任何本地存储,所有元数据信息都是通过后端存储系统落地的,所以可以无状态多点部署来解决。
InfoQ:Docker Registry 的权限控制,京东内部是如何处理的?
田琪:由于我们的 Docker 弹性计算云服务是服务于公司内部和生态用户,即实际是一个私有云服务,我们内部本身也不需要搭建类似 Docker Hub 的服务,所以并没有严格的权限控制问题。
InfoQ:Docker Registry 1.0 的并发性能并不好,从你的分析来看,主要的并发瓶颈在哪里?
田琪:这个问题可以从整体 Docker 上传镜像流程说起,这个流程本身有很多待改进的地方,从镜像生成的驱动到 Docker Registry 1.0 的设计都有提升空间,比如镜像生成驱动部分使用 Device Mapper 等方式都是需要通过比对本地文件系统文件来生成 Diff Layer,之后与 Docker Registry 1.0 产生多次元数据的交互,最后才会发起 Layer 本身数据的上传下载请求,并且针对大文件也没有任何优化,不支持断点续传等功能。这些环节在 Docker Registry 2.0 中有很多改善,相信后续也会持续发展。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论