Druid 是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。尤其是当发生代码部署、机器故障以及其他产品系统遇到宕机等情况时,Druid 仍能够保持 100% 正常运行。创建 Druid 的最初意图主要是为了解决查询延迟问题,当时试图使用 Hadoop 来实现交互式查询分析,但是很难满足实时分析的需要。而 Druid 提供了以交互方式访问数据的能力,并权衡了查询的灵活性和性能而采取了特殊的存储格式。
Druid 功能介于 PowerDrill 和 Dremel 之间,它几乎实现了 Dremel 的所有功能,并且从 PowerDrill 吸收一些有趣的数据格式。Druid 允许以类似 Dremel 和 PowerDrill 的方式进行单表查询,同时还增加了一些新特性,如为局部嵌套数据结构提供列式存储格式、为快速过滤做索引、实时摄取和查询、高容错的分布式体系架构等。从官方得知,Druid 的具有以下主要特征:
- 为分析而设计——Druid 是为 OLAP 工作流的探索性分析而构建,它支持各种过滤、聚合和查询等类;
- 快速的交互式查询——Druid 的低延迟数据摄取架构允许事件在它们创建后毫秒内可被查询到;
- 高可用性——Druid 的数据在系统更新时依然可用,规模的扩大和缩小都不会造成数据丢失;
- 可扩展——Druid 已实现每天能够处理数十亿事件和 TB 级数据。
Druid 应用最多的是类似于广告分析创业公司 Metamarkets 中的应用场景,如广告分析、互联网广告系统监控以及网络监控等。当业务中出现以下情况时,Druid 是一个很好的技术方案选择:
- 需要交互式聚合和快速探究大量数据时;
- 需要实时查询分析时;
- 具有大量数据时,如每天数亿事件的新增、每天数 10T 数据的增加;
- 对数据尤其是大数据进行实时分析时;
- 需要一个高可用、高容错、高性能数据库时。
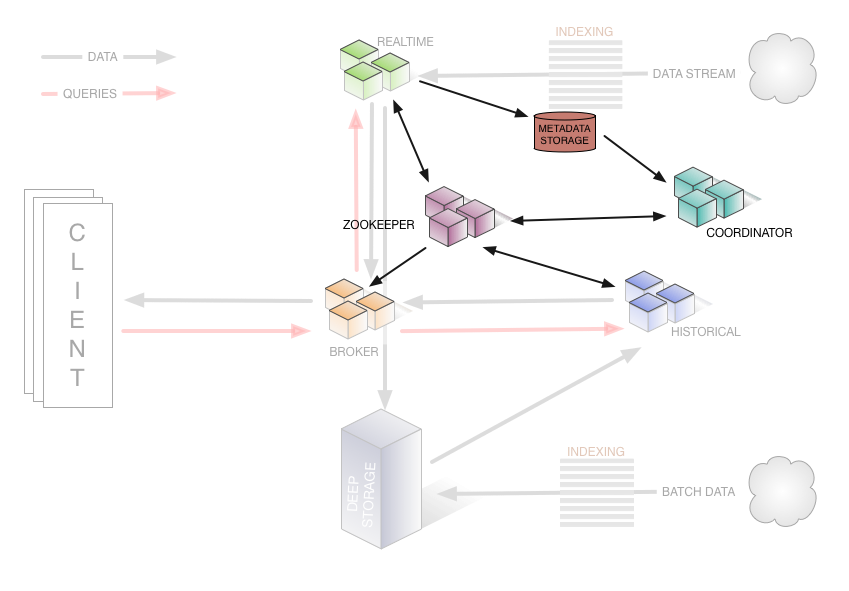
一个 Druid 集群有各种类型的节点(Node)组成,每个节点都可以很好的处理一些的事情,这些节点包括对非实时数据进行处理存储和查询的 Historical 节点、实时摄取数据、监听输入数据流的 Realtime 节、监控 Historical 节点的 Coordinator 节点、接收来自外部客户端的查询和将查询转发到 Realtime 和 Historical 节点的 Broker 节点、负责索引服务的 Indexer 节点。
查询操作中数据流和各个节点的关系如下图所示:

如下图是 Druid 集群的管理层架构,该图展示了相关节点和集群管理所依赖的其他组件(如负责服务发现的 ZooKeeper 集群)的关系:
Druid 已基于 Apache License 2.0 协议开源,代码托管在 GitHub ,其当前最新稳定版本是 0.7.1.1 。当前,Druid 已有 63 个代码贡献者和将近 2000 个关注。Druid 的主要贡献者包括广告分析创业公司 Metamarkets、电影流媒体网站 Netflix 、Yahoo 等公司。Druid 官方还对 Druid 同 Shark 、 Vertica 、 Cassandra 、 Hadoop 、 Spark 、 Elasticsearch 等在容错能力、灵活性、查询性能等方便进行了对比说明。更多关于 Druid 的信息,大家还可以参考官方提供的入门教程、白皮书 、设计文档等。
感谢徐川对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 )。
)。




