
Apache Samza 是一个开源、分布式的流处理框架,它使用开源分布式消息处理系统 Apache Kafka 来实现消息服务,并使用资源管理器 Apache Hadoop YARN 实现容错处理、处理器隔离、安全性和资源管理。近日,从 Apache 官方博客中得知,开源的分布式流处理框架 Samza 历经 18 个月的孵化期后终于升级成为 Apache 的顶级项目。Samza 由 LinkedIn 于 2013 年 9 月开源并作为孵化项目贡献给Apache。
LinkedIn 的工程部和运营部的高级副总裁 Kevin Scott 在公布消息的博文中说到:
Samza 能够被广泛的使用并成为 Apache 的顶级项目真是令人兴奋,开发 Samza 是为了帮助解决 LinkedIn 流数据处理高性能的挑战,Samza 已经成为 LinkedIn 业务架构的核心部分。
Improve Digital 的 CTO Garry Turkington 在博文中说到:
Improve Digital 已经积累了丰富的 Samza 经验,这使得 Improve
Digital 使用 Samza 能够构建出功能强大的流数据处理平台。此外,Samza 能够升级成为 Apache 顶级项目真是太棒了。
Samza 非常适用于实时流数据处理的业务(如同 Apache Storm ),如数据跟踪、日志服务、实时服务等应用,它能够帮助开发者进行高速消息处理, 同时还具有良好的容错能力。在 Samza 流数据处理过程中,每个 Kafka 集群都与一个能运行 Yarn 的集群相连并处理 Samza 作业。Samza 的一个简单处理过程如下图所示:
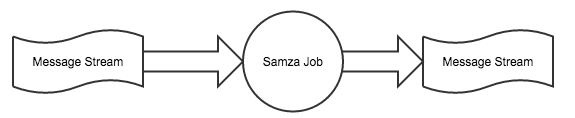
Samza 的主要特征如下:
- 简单的 API:Samza 提供了一个简单基于回调且兼容 MapReduce 的消息处理 API。
- 状态管理:Samza 提供了一个基于 LevelDB 的 Key/Value 数据库来存储历史数据,从而实现了有状态的消息管理。
- 容错处理:每当集群中的一台机器发生故障时,YARN 将会透明地将相关任务迁移到其他机器上。
- 持久性:Samza 使用 Kafka 保证消息的有序处理,并能够持久化到分区,不存在发生消息的丢失的可能。
- 可扩展性:Samza 在每个层结构都是可分区和分布式的,Kafka 提供了有序、可分区、可追加、容错的流;YARN 提供了一个分布式、供 Samza 运行的容器环境。
- 可插拔 / 开箱即用:Samza 提供了一个可插拔特性的 API,该 API 使得 Samza 不仅能够使用 Kafka 和 YARN,还能够使用其他的消息系统和执行环境。
- 资源隔离:通过使用 YARN 实现了对 Hadoop 安全模型和资源隔离的支持。
LinkedIn、Microsoft、 Confluent 、Oracle、 Hortonworks 、 Uber 和 Improve Digital 等众多著名公司都在为 Samza 贡献代码。Samza 已在商务智能(BI)、金融服务、医疗保健、安全服务、移动应用、软件开发等行业得到了广泛应用,其用户包括企业移动应用提供商 DoubleDutch 、欧洲领先的实时广告技术提供商 Improve Digital、金融服务公司 Jack Henry & Associates 、移动商务解决方案提供商 MobileAware 、基于云的微服务提供商 Quantiply 、社交媒体商务智能解决方案提供商 VinTank 等。
此外,实时 / 流计算框架除了 Samza 外,还包括 Google Dremel 、 Apache Drill 、Apache Storm 以及 Apache S4 等。有兴趣的读者可以通过官方提供的 Hello Samza 工程尝试下 Samza,或者参见 Background 页面以获得更多关于 Samza 的信息。读者还可以阅读 LinkedIn 资深 SRE Jon Bringhurst 发表的一篇博文,该篇博文主要阐述了LinkedIn 是如何利用Samza 与Yarn、Kafka 进行扩展的,它能够帮助大家深一步地了解Samza。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

暂无签名

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论