Spark 的发展
对于一个具有相当技术门槛与复杂度的平台,Spark 从诞生到正式版本的成熟,经历的时间如此之短,让人感到惊诧。2009 年,Spark 诞生于伯克利大学 AMPLab,最开初属于伯克利大学的研究性项目。它于 2010 年正式开源,并于 2013 年成为了 Aparch 基金项目,并于 2014 年成为 Aparch 基金的顶级项目,整个过程不到五年时间。
由于 Spark 出自伯克利大学,使其在整个发展过程中都烙上了学术研究的标记,对于一个在数据科学领域的平台而言,这也是题中应有之义,它甚至决定了 Spark 的发展动力。Spark 的核心 RDD(resilient distributed datasets),以及流处理,SQL 智能分析,机器学习等功能,都脱胎于学术研究论文,如下所示:
- Discretized Streams: Fault-Tolerant Streaming Computation at Scale. Matei Zaharia, Tathagata Das, Haoyuan Li, Timothy Hunter, Scott Shenker, Ion Stoica. SOSP 2013. November 2013.
- Shark: SQL and Rich Analytics at Scale. Reynold Xin, Joshua Rosen, Matei Zaharia, Michael J. Franklin, Scott Shenker, Ion Stoica. SIGMOD 2013. June 2013.
- Discretized Streams: An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters. Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica. HotCloud 2012. June 2012.
- Shark: Fast Data Analysis Using Coarse-grained Distributed Memory (demo). Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Haoyuan Li, Scott Shenker, Ion Stoica. SIGMOD 2012. May 2012. Best Demo Award.
- Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica. NSDI 2012. April 2012. Best Paper Award and Honorable Mention for Community Award.
- Spark: Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. HotCloud 2010. June 2010.
在大数据领域,只有深挖数据科学领域,走在学术前沿,才能在底层算法和模型方面走在前面,从而占据领先地位。Spark 的这种学术基因,使得它从一开始就在大数据领域建立了一定优势。无论是性能,还是方案的统一性,对比传统的 Hadoop,优势都非常明显。Spark 提供的基于 RDD 的一体化解决方案,将 MapReduce、Streaming、SQL、Machine Learning、Graph Processing 等模型统一到一个平台下,并以一致的 API 公开,并提供相同的部署方案,使得 Spark 的工程应用领域变得更加广泛。
Spark 的代码活跃度
从 Spark 的版本演化看,足以说明这个平台旺盛的生命力以及社区的活跃度。尤其在 2013 年来,Spark 进入了一个高速发展期,代码库提交与社区活跃度都有显著增长。以活跃度论,Spark 在所有 Aparch 基金会开源项目中,位列前三。相较于其他大数据平台或框架而言,Spark 的代码库最为活跃,如下图所示:
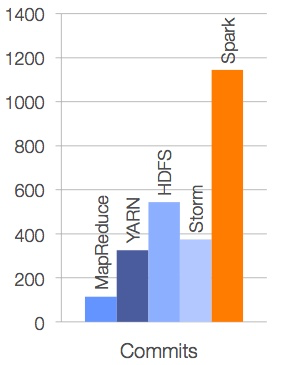
从 2013 年 6 月到 2014 年 6 月,参与贡献的开发人员从原来的 68 位增长到 255 位,参与贡献的公司也从 17 家上升到 50 家。在这 50 家公司中,有来自中国的阿里、百度、网易、腾讯、搜狐等公司。当然,代码库的代码行也从原来的 63,000 行增加到 175,000 行。下图为截止 2014 年 Spark 代码贡献者每个月的增长曲线:
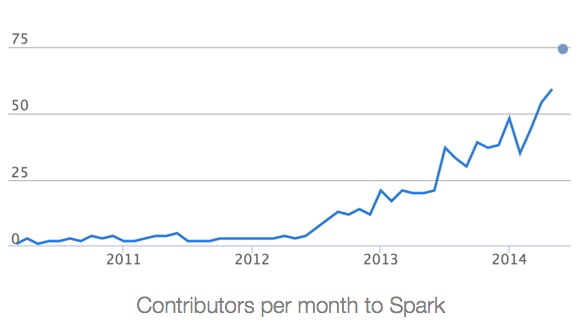
下图则显示了自从 Spark 将其代码部署到 Github 之后的提交数据,一共有 8471 次提交,11 个分支,25 次发布,326 位代码贡献者。

目前的 Spark 版本为 1.1.0。在该版本的代码贡献者列表中,出现了数十位国内程序员的身影。这些贡献者的多数工作主要集中在 Bug Fix 上,甚至包括 Example 的 Bug Fix。由于 1.1.0 版本极大地增强了 Spark SQL 和 MLib 的功能,因此有部分贡献都集中在 SQL 和 MLib 的特性实现上。下图是 Spark Master 分支上最近发生的仍然处于 Open 状态的 Pull Request:
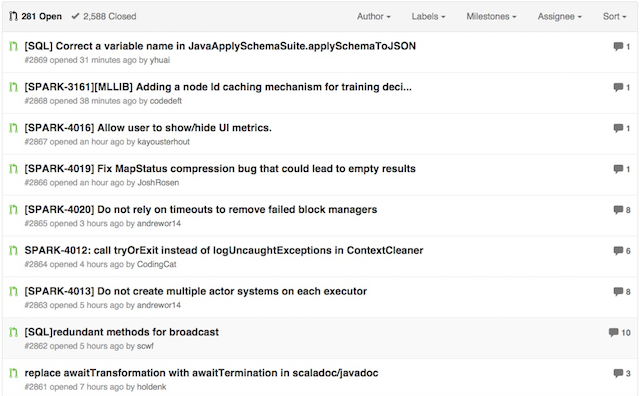
可以看出,由于 Spark 仍然比较年轻,当运用到生产上时,可能发现一些小缺陷。而在代码整洁度方面,也随时在对代码进行着重构。例如,淘宝技术部在 2013 年就开始尝试将 Spark on Yarn 应用到生产环境上。他们在执行数据分析作业过程中,先后发现了 DAGSchedular 的内存泄露,不匹配的作业结束状态等缺陷,从而为 Spark 库贡献了几个比较重要的 Pull Request。具体内容可以查看淘宝技术部的博客文章:《Spark on Yarn:几个关键 Pull Request( http://rdc.taobao.org/?p=525)》。
Spark 的社区活动
Spark 非常重视社区活动,组织也极为规范,定期或不定期地举行与 Spark 相关的会议。会议分为两种,一种为 Spark Summit,影响力巨大,可谓全球 Spark 顶尖技术人员的峰会。目前,已经于 2013 年和 2014 年在 San Francisco 连续召开了两届 Summit 大会。2015 年,Spark Summit 将分别在 New York 与 San Francisco 召开,其官方网站为: http://spark-summit.org/。
在 2014 年的 Spark Summit 大会上,我们看到除了伯克利大学以及 Databricks 公司自身外,演讲者都来自最早开始运用和尝试 Spark 进行大数据分析的公司,包括最近非常火的音乐网站 Spotify,全球最大专注金融交易的 Sharethrough,专业大数据平台 MapR、Cloudera,云计算的领先者 Amazon,以及全球超大型企业 IBM、Intel、SAP 等。
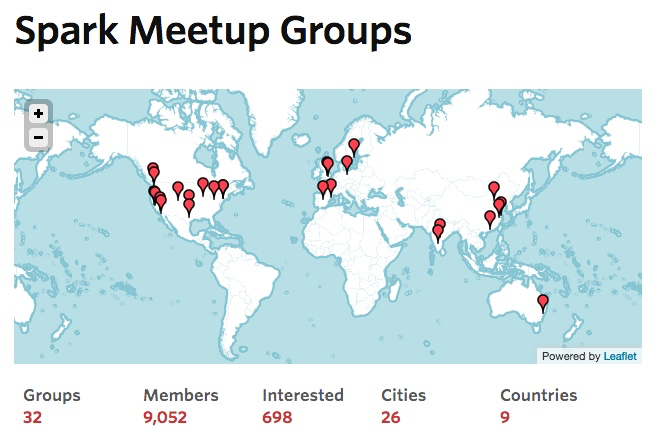
除了影响力巨大的 Spark Summit 之外,Spark 社区还不定期地在全球各地召开小型的 Meetup 活动。Spark Meetup Group 已经遍布北美、欧洲、亚洲和大洋洲。在中国,北京 Spark Meetup 已经召开了两次,并将于今年 10 月 26 日召开第三次 Meetup。届时将有来自 Intel 中国研究院、淘宝、TalkingData、微软亚洲研究院、Databricks 的工程师进行分享。下图为 Spark Meetup Groups 在全球的分布图:
Spark 的现在和未来
Spark 的特色在于它首先为大数据应用提供了一个统一的平台。从数据处理层面看,模型可以分为批处理、交互式、流处理等多种方式;而从大数据平台而言,已有成熟的 Hadoop、Cassandra、Mesos 以及其他云的供应商。Spark 整合了主要的数据处理模型,并能够很好地与现在主流的大数据平台集成。下图展现了 Spark 的这一特色:
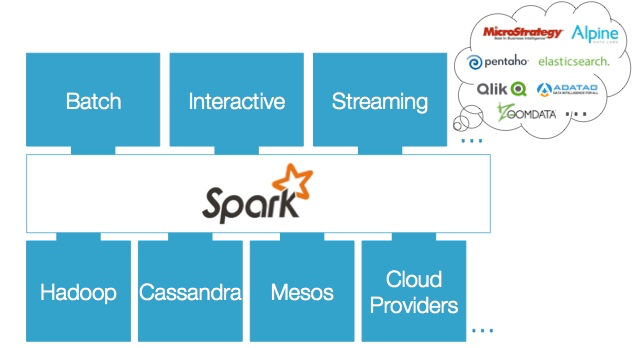
这样的一种统一平台带来的优势非常明显。对于开发者而言,只需要学习一个平台,降低了学习曲线。对于用户而言,可以很方便地将 Spark 应用运行在 Hadoop、Mesos 等平台上面,满足了良好的可迁移性。统一的数据处理方式,也可以简化开发模型,降低平台的维护难度。
Spark 为大数据提供了通用算法的标准库,这些算法包括 MapReduce、SQL、Streaming、Machine Learning 与 Graph Processing。同时,它还提供了对 Scala、Python、Java(支持 Java 8)和 R 语言的支持:
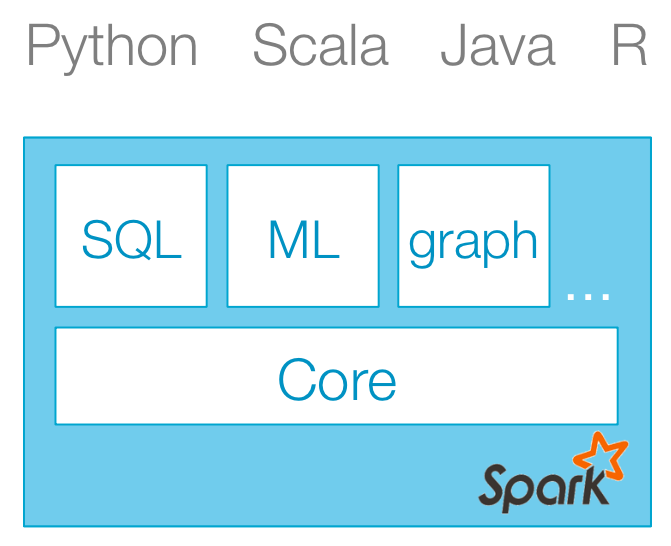
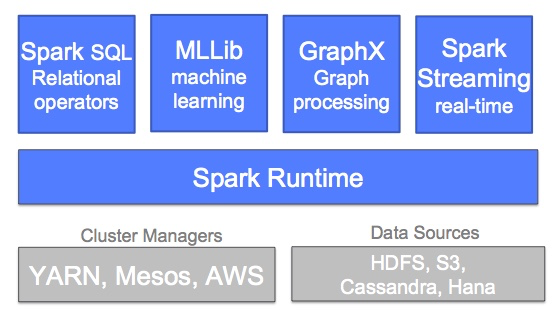
在最新发布的 1.1.0 版本中,对 Spark SQL 和 Machine Learning 库提供了增强。Spark SQL 能够更加有效地在 Spark 中加载和查询结构型数据,同时还支持对 JSON 数据的操作,并提供了更加友好的 Spark API。在 Machine Learning 方面,已经包含了超过 15 种算法,包括决策树、SVD、PCA,L-BFGS 等。下图展现了 Spark 当前的技术栈:
在 2014 年的 Spark Summit 上,来自 Databricks 公司的 Patrick Wendell 展望了 Spark 的未来。他在演讲中提到了 Spark 的目标,包括:
- Empower data scientists and engineers
- Expressive, clean APIs
- Unified runtime across many environments
- Powerful standard libraries
在演讲中,他提到在 Spark 最近的版本中,最重要的核心组件为 Spark SQL。接下来的几次发布,除了在性能上更加优化(包括代码生成和快速的 Join 操作)外,还要提供对 SQL 语句的扩展和更好的集成(利用 SchemaRDD 与 Hadoop、NoSQL 以及 RDBMS 的集成)。在将来的版本中,要为 MLLib 增加更多的算法,这些算法除了传统的统计算法外,还包括学习算法,并提供与 R 语言更好的集成,从而能够为数据科学家提供更好的选择,根据场景来选择 Spark 和 R。
Spark 的发展会结合硬件的发展趋势。首先,内存会变得越来越便宜,256GB 内存以上的机器会变得越来越常见,而对于硬盘,则 SSD 硬盘也将慢慢成为服务器的标配。由于 Spark 是基于内存的大数据处理平台,因而在处理过程中,会因为数据存储在硬盘中,而导致性能瓶颈。随着机器内存容量的逐步增加,类似 HDFS 这种存储在磁盘中的分布式文件系统将慢慢被共享内存的分布式存储系统所替代,诸如同样来自伯克利大学的 AMPLab 实验室的 Tachyon 就提供了远超 HDFS 的性能表现。因此,未来的 Spark 会在内部的存储接口上发生较大的变化,能够更好地支持 SSD、以及诸如 Tachyon 之类的共享内存系统。事实上,在 Spark 的最近版本里,已经开始支持 Tachyon 了。
根据 Spark 的路线图,Databricks 会在近三个月陆续发布 1.2.0 和 1.3.0 版本。其中,1.2.0 版本会对存储方面的 API 进行重构,在 1.3.0 之上的版本,则会推出结合 Spark 和 R 的 SparkR。除了前面提到的 SQL 与 MLLib 之外,未来的 Spark 对于 Streaming、GraphX 都有不同程度的增强,并能够更好地支持 YARN。
Spark 的应用
目前,Spark 的正式版本得到了部分 Hadoop 主流厂商的支持,如下企业或平台发布的 Hadoop 版本中,都包含了 Spark:

这说明业界已经认可了 Spark,Spark 也被许多企业尤其是互联网企业广泛应用到商业项目中。根据 Spark 的官方统计,目前参与 Spark 的贡献以及将 Spark 运用在商业项目的公司大约有 80 余家( https://cwiki.apache.org/confluence/display/SPARK/Powered+By+Spark)。在国内,投身 Spark 阵营的公司包括阿里、百度、腾讯、网易、搜狐等。在 San Francisco 召开的 Spark Summit 2014 大会上,参会的演讲嘉宾分享了在音乐推荐(Spotify)、实时审计的数据分析(Sharethrough)、流在高速率分析中的运用(Cassandra)、文本分析(IBM)、客户智能实时推荐(Graphflow)等诸多在应用层面的话题,这足以说明 Spark 的应用程度。
但是,整体而言,目前开始应用 Spark 的企业主要集中在互联网领域。制约传统企业采用 Spark 的因素主要包括三个方面。首先,取决于平台的成熟度。传统企业在技术选型上相对稳健,当然也可以说是保守。如果一门技术尤其是牵涉到主要平台的选择,会变得格外慎重。如果没有经过多方面的验证,并从业界获得成功经验,不会轻易选定。其次是对 SQL 的支持。传统企业的数据处理主要集中在关系型数据库,而且有大量的遗留系统存在。在这些遗留系统中,多数数据处理都是通过 SQL 甚至存储过程来完成。如果一个大数据平台不能很好地支持关系型数据库的 SQL,就会导致迁移数据分析业务逻辑的成本太大。其三则是团队与技术的学习曲线。如果没有熟悉该平台以及该平台相关技术的团队成员,企业就会担心开发进度、成本以及可能的风险。
Spark 在努力解决这三个问题。随着 1.0.2 版本的发布,Spark 得到了更多商用案例的验证。Spark 虽然依旧保持年轻的活力,但已经具备堪称成熟的平台功能。至于 SQL 支持,Spark 非常。在 1.0.2 版本发布之前,就认识到基于 HIVE 的 Shark 存在的不足,从而痛下决心,决定在新版本中抛弃 Shark,而决定引入新的 SQL 模块。如今,在 Spark 1.1.0 版本中,Spark SQL 的支持已经相对完善,足以支持企业应用中对 SQL 迁移的需求。关于 Spark 的学习曲线,主要的学习内容还是在于对 RDD 的理解。由于 Spark 为多种算法提供了统一的编程模型、部署模式,搭建了一个大数据的一体化方案,倘若企业的大数据分析需要应对多种场景,那么,Spark 这样的架构反而使得它的学习曲线更低,同时还能降低部署成本。Spark 可以很好地与 Hadoop、Cassandra 等平台集成,同时也能部署到 YARN 上。如果企业已经具备大数据分析的能力,原有掌握的经验仍旧可以用到 Spark 上。虽然 Spark 是用 Scala 编写,官方也更建议用户调用 Scala 的 API,但它同时也提供了 Java 和 Python 的接口,非常体贴地满足了 Java 企业用户或非 JVM 用户。如果抱怨 Java 的冗赘,则 Spark 新版本对 Java 8 的支持让 Java API 变得与 Scala API 同样的简洁而强大,例如经典的字数统计算法在 Java 8 中的实现:
JavaRDD<String> lines = sc.textFile("data.txt”);
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);
显然,随着 Spark 的逐渐成熟,并在活跃社区的推动下,它所提供的强大功能一定能得到更多技术团队和企业的青睐。相信在不远的将来会有更多传统企业开始尝试使用 Spark。




