Brent Ozar 是咨询公司 Brent Ozar Unlimited 的创始人和负责人,同时也是一名微软最有价值专家和 SQL Server DBA。他发表了一篇博文,介绍一种缓存存储过程结果的方案及应用场景。
在文章开头,他给出了这样一个场景:一家在线商店需要在每个物品的页面上显示用户买过的相关产品。他认为,在完美的世界中,这些数据应该在 Web/ 应用层缓存。但是,有时候,开发人员会构建存储过程来获取这类数据,而最终存储过程的调用过于频繁。
Brent 指出,对于这种已经使用了存储过程的情况,可以构建一个缓存供存储过程使用。
假如加入缓存层之前的代码如下:
CREATE PROCEDURE dbo.usp_GetRelatedItems
@ItemID INT AS
BEGIN
SELECT RelatedItemID,RelatedItemName
FROM dbo.BigComplicatedView
WHERE SoldItemID=@ItemID;
END
GO
代码一:原来的存储过程
则加入缓存层之后的代码如下:
CREATE PROCEDURE dbo.usp_GetRelatedItems
@ItemID INT AS
BEGIN
IF EXISTS(SELECT * FROM Cache.dbo.GetRelatedItems
WHERE ItemID=@ItemID)
SELECT *
FROM Cache.dbo.GetRelatedItems
WHERE ItemID=@ItemID
ELSE
SELECT RelatedItemID,RelatedItemName
FROM dbo.BigComplicatedView
WHERE SoldItemID=@ItemID;
END
GO
代码二:实现缓存(一)
代码二引入了一个新表 Cache.dbo.GetRelatedItems,其中 Cache 是新建的数据库。该表中的列比 usp_GetRelatedItems 的返回结果多了一个输入字段和一个 ID,其格式如下:
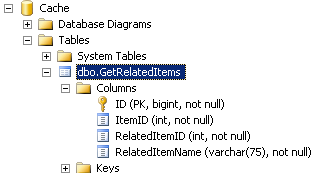
该表中的数据可以根据需要每天晚上或者每周进行一次 truncate。另外,在实际工作中实现这样一个方案时,他还会根据大量 A/B 性能测试的结果创建恰当的聚簇索引。
代码二并未对缓存表进行操作。如果数据没有缓存,其实需要将其插入缓存表,代码如下:
CREATE PROCEDURE dbo.usp_GetRelatedItems
@ItemID INT AS
BEGIN
/* 查看待查找的记录是否已经缓存 */
IF NOT EXISTS(SELECT * FROM Cache.dbo.GetRelatedItems
WHERE ItemID=@ItemID)
BEGIN
/* 缓存中没有记录,因此插入缓存 */
INSERT INTO Cache.dbo.GetRelatedItems
(ItemID,RelatedItemID,RelatedItemName)
SELECT RelatedItemID,RelatedItemName
FROM dbo.BigComplicatedView
WHERE SoldItemID=@ItemID;
END
/* 从缓存中获取记录 */
SELECT *
FROM Cache.dbo.GetRelatedItems
WHERE ItemID=@ItemID
END
GO
代码三:实现缓存(二)
他承认,这种做法会增加 SQL Server 的写负载,但他只有在面临下面这些情况时才使用这种方案:
- 操作极为密集但只读的存储过程
- 调用非常频繁(每分钟几百或几千次)
- 其结果变化频率少于每天一次(或者不关心实时精度)
- 业务需要非常快的系统改进速度,没有时间等着开发人员实现一个缓存层
最后,他指出,这只是紧急情况下让业务恢复运行的一种创可贴式方案。另外,他还推荐了一些与缓存相关的资源,包括最快的查询是不用执行的那个、选择缓存方式、通过缓存让系统更好地运行。有兴趣的读者可以进一步阅读。
感谢包研对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




