
2014 年 3 月 15 日,在由 @百度主办、 @InfoQ 负责策划组织和实施的第 48 期百度技术沙龙活动上,来自百度联盟大数据机器学习技术负责人夏粉,和搜狗精准广告研发部技术经理王晓博,各自分享了其在机器学习方面的实战经验。他们的话题涉及“广告数据上的大规模机器学习”和“大数据场景下主题检索应用”这两个方面,本文将对讲师各自的分享做简单的回顾,同时提供相关资料的下载。
主题一:广告数据上的大规模机器学习(下载讲稿)
一个好的广告匹配系统,需要在解决上述挑战的同时,使用尽可能少的资源挖掘尽可能多的数据价值,提升广告匹配效率。围绕这个目的,夏粉老师以广告点击率预估问题为例,讲解如何利用大规模机器学习技术搭建一个容纳万亿特征数据的、分钟级别模型更新的、自动高效深度学习的、高效训练的点击率预估系统。
计算广告学与 CTR预估
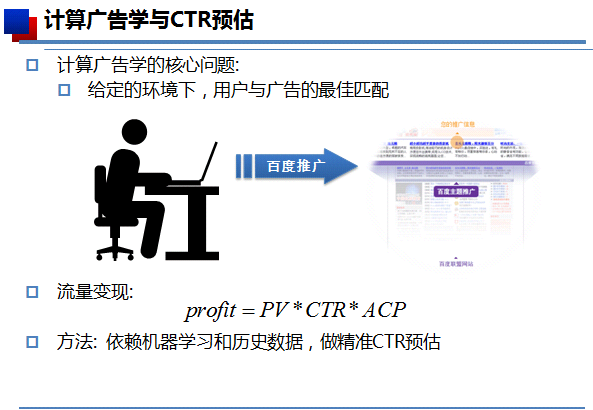
计算广告学所面临的最主要挑战是在特定语境下特定用户和相应的广告之间找到“最佳匹配”。语境可以是用户在搜索引擎中输入的查询词,也可以是用户正在读的网页,还可以是用户正在看的电影,等等。而用户相关的信息可能非常多也可能非常少。潜在广告的数量可能达到几十亿。因此,取决于对“最佳匹配”的定义,面临的挑战可能导致在复杂约束条件下的大规模优化和搜索问题。
“我们用机器学习来做广告数据,如何把 CTR 如何做好,这需要梳理整个处理流程。把整个流程全部梳理完以后,我们才能发现有哪些可做点对点击预估有影响”,蒋锦鹏说。
大规模机器学习

特征规模大:训练样本,每天上百亿级别的访问量;特征类型复杂,广告、用户、流量、季节、节假日等。数据大、特征多、类别不平衡、噪音大。
特征之间存在高度非线性关系: e.g., 不同用户(男、女),在不同年龄段,喜欢点不同广告;同一广告,在不同时间段,点击也不同;异或问题。
数据训练频繁:策略定期更新,策略调研,频繁调用模型训练程序
模型时效性
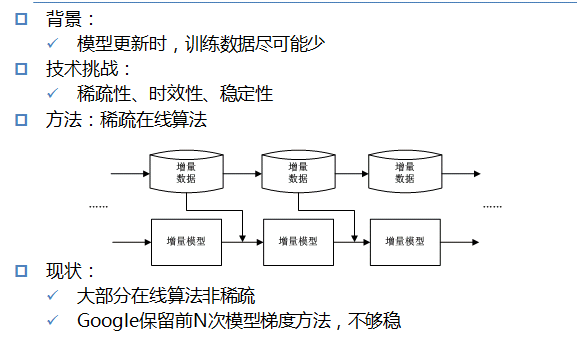
稀疏性: 模型需要模型保存的信息尽可能少;
时效性: 模型训练数据近可能少;
稳定性: 模型需要的数据信息尽可能多;
Google: 保留前 N 次模型的梯度及模型,信息损失大,模型不够稳
主题二:大数据场景下主题检索应用(下载讲稿)
通常大家碰到的数据集最多也就是几万到几十万篇文章这个量级,但在企业的实际场景中,如果遇到亿级数据该如何处理?如何利用有限的计算集群资源处理呢?
超大的文集,王晓博围绕这一难题向大家介绍了 LDA 主题模型训练系统以及它在线上预测时需要面对的问题和解决办法。
- 主题检索模型理论基础
- 大数据场景下的挑战
- 构建一个高效的训练系统
- 模型在商业广告检索中的应用
发展过程——VSM
向量空间模型是一个开创性的概念:
优点:文档可以被表示成一个实数向量;
不同长度的文档都能够被表示成定长的数列;
引入与向量相关的计算方法。
问题:文档被映射在词空间,向量维度太高;
理解能力弱,对语义分析的支持不强通信选型
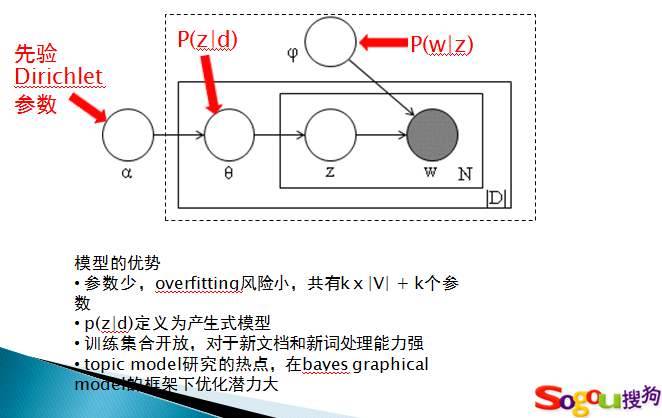
LDA 模型简介
OpenSpace(开放式讨论环节)
为了促进参会者与我们每期的嘉宾以及讲师近距离交流,深入探讨在演讲过程中的疑问,本次活动依然设置了 Open Space(开放式讨论)环节。在 Open Space 的总结环节,几位话题小组长分别对讨论的内容进行了总结。
夏粉:深度学习话题在现在大数据时代将会越来越火,我在演讲时算是为大家抛了个砖,互动过程中大家问了许多实际的问题,希望我的解释能给大家带来一些帮助。
王晓博:关注机器学习的同学热情很高,夏老师讲的干货很多,但只要不涉及关键商业化数据,比如百度广告点击的具体数字,这些模型公布出来对大家的学习还是很有好处的。希望下次主办方能准备相关话题,这样在 Open Space 时,讲师可提前做一些准备,为听众做更针对性的解答。
会上,一些参会者也通过新浪微博分享了他们的参会感受:
爱新觉罗小牙:和百度比,我们还处于石器时代。。
豪_CHANGE : @夏粉 _ 百度夏老师,您能讲下这个计算广告的数十亿特征具体就包括哪些吗。如何得到的?
范斌_ :#百度技术沙龙#提前将近一个小时来,人都快满了。大家拿着iPhone,iPad,kindle。看书,学习,讨论。程序员都这德行。
有关百度技术沙龙的更多信息,可以通过新浪微博关注 @百度技术沙龙,或者关注 InfoQ 官方微信:infoqchina,InfoQ 上也总结了过往所有百度技术沙龙的演讲视频和资料等,感兴趣的读者可以直接浏览内容。
特别提示:第48 期百度技术沙龙将在4 月19 日,周六,在北京车库咖啡举行,主题为《大规模分布式存储实战解析》,欢迎关注 @InfoQ 、 @百度技术沙龙获取后续的活动信息。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论