Netflix 的推荐和个性化功能向来精准,前不久,他们公布了自己在这方面的系统架构。
3 月 27 日,Netflix 的工程师 Xavier Amatrain 和 Justin Basilico 在官方博客发布文章,介绍了自己的个性化和推荐系统架构。文章开头,他们指出:
要开发出这样的一个软件架构,能够处理海量现有数据、响应用户交互,还要易于尝试新的推荐方法,这可不一点都不容易。
接下来,文章贴出了他们的系统框架图,其中的主要组件包括多种机器学习算法。
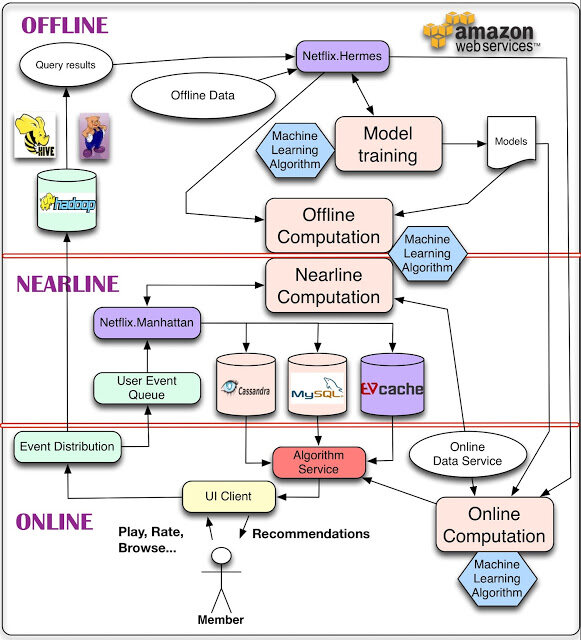
他们这样解释其中的组件和处理过程:
对于数据,最简单的方法是存下来,留作后续离线处理,这就是我们用来管理离线作业(Offline jobs)的部分架构。计算可以以离线、接近在线或是在线方式完成。在线计算(Online computation)能更快地响应最近的事件和用户交互,但必须实时完成。这会限制使用算法的复杂性和处理的数据量。离线计算(Offline computation)对于数据数量和算法复杂度限制更少,因为它以批量方式完成,没有很强的时间要求。不过,由于没有及时加入最新的数据,所以很容易过时。个性化架构的关键问题,就是如何以无缝方式结合、管理在线和离线计算过程。接近在线计算(Nearline computation)介于两种方法之间,可以执行类似于在线计算的方法,但又不必以实时方式完成。模型训练(Model training)是另一种计算,使用现有数据来产生模型,便于以后在对实际结果计算中使用。另一块架构是如何使用事件和数据分发系统(Event and Data Distribution)处理不同类型的数据和事件。与之相关的问题,是如何组合在离线、接近在线和在线之间跨越的不同的信号和模型(Signals and Models)。最后,需要找出如何组合推荐结果(Recommendation Results),让其对用户有意义。
接下来,文章分析了在线、接近在线和离线计算。
对于在线计算,相关组件需要满足 SLA 对可用性和响应时间的要求,而且纯粹的在线计算在某型情形下可能无法满足 SLA,因此,快速的备用方案就很重要,比如返回预先计算好的结果等。在线计算还需要不同的数据源确保在线可用,这需要额外的基础设施。
离线计算在算法上可相对灵活,工程方面的需求也简单。客户端的 SLA 响应时间要求也不高。在部署新算法到生产环境时,对于性能调优的需求也不高。Netflix 利用这种灵活性来完成快速实验:如果某个新的实验算法执行较慢,他们会部署更多 Amazon EC2 实例来达成吞吐处理目标,而不是花费宝贵的工程师时间去优化性能,因为业务价值可能不是很高。
接近在线计算与在线计算执行方式相同,但计算结果不是马上提供,而是暂时存储起来,使其具备异步性。接近在线计算的完成是为了响应用户事件,这样系统在请求之间响应速度更快。这样一来,针对每个事件就有可能完成更复杂的处理。增量学习算法很适合应用在接近在线计算中。
不管什么情况,选择在线、接近在线、还是离线处理,这都不是非此即彼的决策。所有的方式都可以、而且应该结合使用。 …… 即使是建模部分也可以用在线和离线的混合方式完成。这可能不适合传统的监督分类法(supervised classification)应用,因为分类器必须从有标记的数据中批量培训,而且只能以在线方式使用,对新输入分类。不过,诸如矩阵因子分解这样的方法更适合混合离线和在线建模方法:有些因子可以预先以离线方式计算,有些因子可以实时更新,创建更新的结果。其他诸如集群处理这样的非监督方法,也可以对集群中心进行离线计算,对集群节点进行在线作业。这些例子说明:模型训练可以分解为大规模和复杂的全局模型训练,以及轻量级的用户指定模型训练或更新阶段,以在线方式完成。
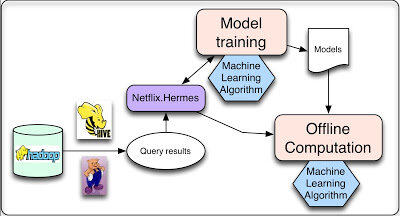
对于离线作业(Offline jobs),主要用来运行个性化机器学习算法。这些作业会定期执行,而且不必与结果的请求和展示同步。主要有两种任务这样处理:模型训练和中间与最终结果批量计算(batch computation of intermediate or final results)。不过,他们也有一些学习算法是以在线增量方式完成的。
这两种任务都需要改善数据,通常是由数据库查询完成。由于这些查询要操作大量数据,以分布式方式完成更方便,因此通过 Hadoop 或是 Hive、Pig 作业就是自然而然的事情。一旦查询完成,就需要某种机制发布产生的数据。对于这样的机制,Netflix 有如下需求:
- 可以通知订阅者查询完成。
- 支持不同存储方式(不只是 HDFS,还有 S3 或是 Cassandra 等等)
- 应该透明处理错误,允许监控和报警。
Netflix 使用内部的工具 Hermes 完成这些功能,它将数据以接近实时的方式交付给订阅者,在某些方面接近 Apache Kafka ,但它不是消息 / 事件队列系统。
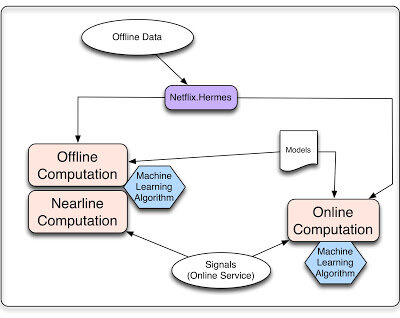
无论是离线还是在线计算,都需要处理三种输入:模型、数据和信号。模型是以离线方式训练完成的参数文件,数据是已完成处理的信息,存在某种数据库中。在 Netflix,信号是指输入到算法中的新鲜信息。这些数据来自实时服务,可用其产生用户相关数据。
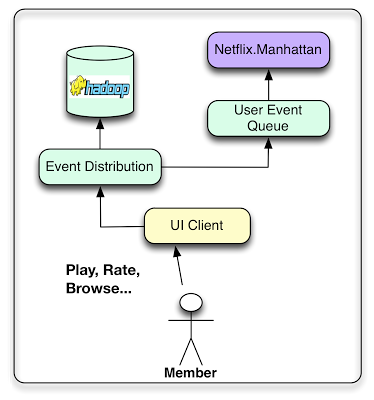
对于事件和数据分发,Netflix 会从多种设备和应用中收集尽可能多的用户事件,并将其集中起来为算法提供基础数据。他们区分了数据和事件。事件是对时间敏感的信息,需要尽快处理。事件会路由、触发后续行动或流程。而数据需要处理和存储,便于以后使用,延迟不是重要,重要的是信息质量和数量。有些用户事件也会被作为数据处理。
Netflix 使用内部框架Manhattan处理接近实时的事件流。该分布式计算系统是推荐算法架构的中心。它类似 Twitter 的 Storm ,但是用处不同,而且响应不同的内部需求。数据流主要通过 Chukwa ,输入到 Hadoop,进行处理的初步阶段。此后使用 Hermes 作为发布 - 订阅机制。
Netflix 使用 Cassandra、EVCache 和 MySQL 存储离线和中间结果。它们各有利弊。MySQL 存储结构化关系数据,但会面临分布式环境中的扩展性问题。当需要大量写操作时,他们使用 EVCache 更合适。关键问题在于,如何满足查询复杂度、读写延迟、事务一致性等彼此冲突的需求,要对于各种情况到达某个最优点。
在总结中,他们指出:
我们需要具备使用复杂机器学习算法的能力,这些算法要可以适应高度复杂性,可以处理大量数据。我们还要能够提供灵活、敏捷创新的架构,新的方法可以很容易在其基础上开发和插入。而且,我们需要我们的推荐结果足够新,能快速响应新的数据和用户行为。找到这些要求之间恰当的平衡并不容易,需要深思熟虑的需求分析,细心的技术选择,战略性的推荐算法分解,最终才能为客户达成最佳的结果。




