Oracle 发布《面向大规模可伸缩网站基础设施的MySQL 参考架构》白皮书,针对将MySQL 用作数据存储的不同类型和不同规模的网站给出了推荐的拓扑结构。
根据分别提供4 类服务——用户和会话管理、电子商务、分析类应用 (多结构数据) 和CMS(元数据)——的网站的规模和可用性要求(如下表所示),这份白皮书给出了4 个参考架构。
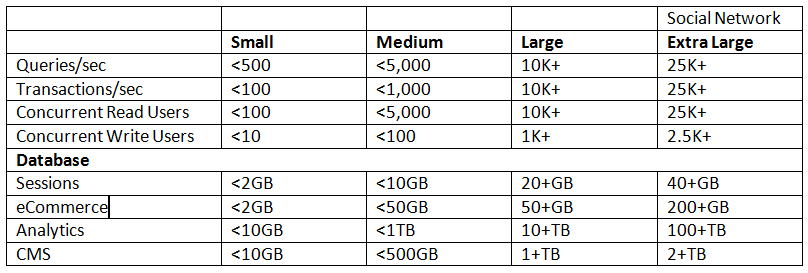
请注意,这里给出的指导方针只是基本建议,实际应用中需要根据读写模式、负载平衡和所用的缓存机制等因素进行调整。
小型(Small)网站参考架构
这一参考架构可用于上述4 类网站的所有小型实现。可以使用MySQL Replication 来制作数据的副本以支持备份和分析。
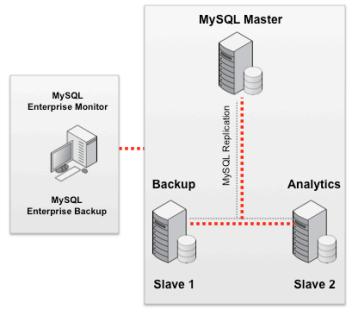
中型(Medium)网站参考架构
在这种情况下,推荐针对不同类型的活动选择独立的基础设施,考虑每个MySQL 服务器最多支持8 个应用服务器,如果因伸缩性需求应用服务器数量增加,则添加更多的MySQL 从服务器。
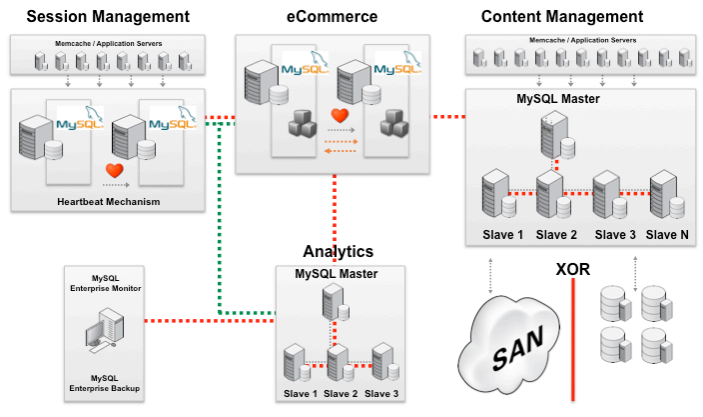
为满足会话管理网站和电子商务网站的高可用性要求,可以使用 Linux 心跳(Heartbeat)和半同步复制。CMS 网站通常对读操作的向外扩展有更高要求,假定每个 MySQL 从服务器最多可以处理 3000 个并发用户,白皮书建议为每个 MySQL 主服务器添加 20-30 个从服务器。CMS 系统可将数据保存在一个 SAN 中,或者保存在连接到该服务器的分布式设备中。
会话管理网站和 CMS 网站推荐使用 Memcached,这有助于减轻应用服务器和 MySQL 服务器的负担。
分析类网站的拓扑结构简单一些,1 个主服务器加 3 个从服务器就能解决问题。
大规模(Large)网站参考架构
针对大规模网站,白皮书推荐使用 MySQL Geographic Replication 来进行跨数据中心的数据库复制,这种方式支持跨越地理上分离的集群进行异步复制。
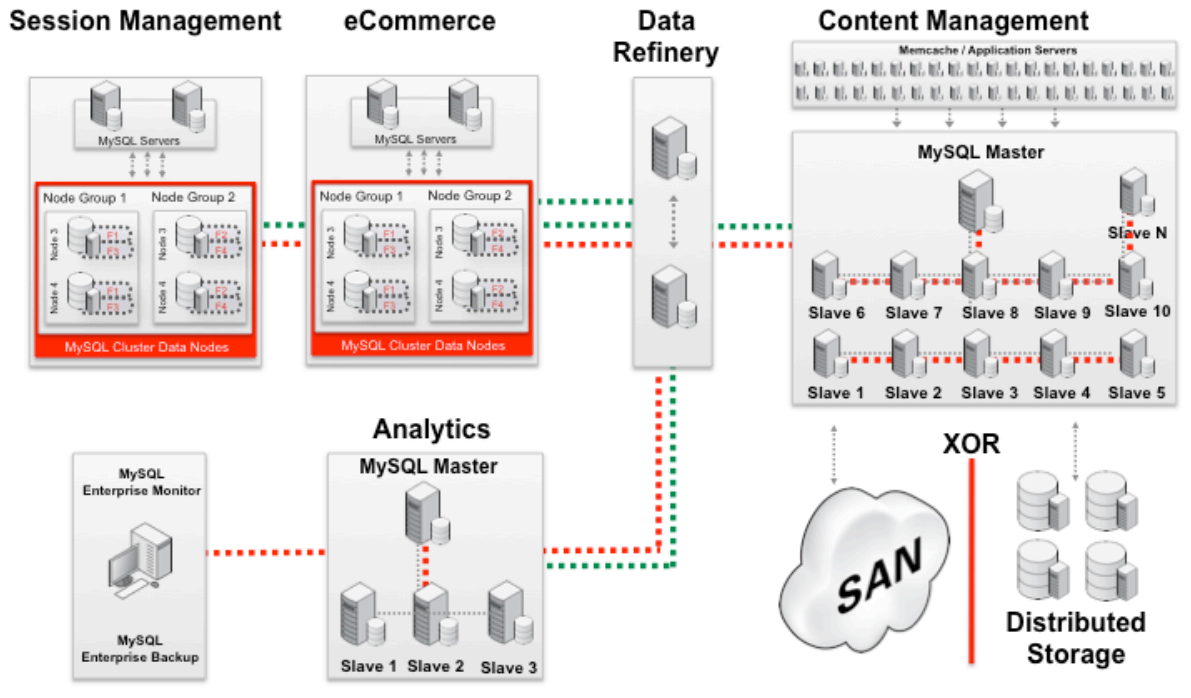
会话管理网站和电子商务网站应该使用集群,白皮书声称“4 个数据节点,1 秒可以支持 6000 个会话(页面点击),其中每次页面点击生成 8–12 个数据库操作”。大规模 CMS 网站使用的配置与中型网站类似,只是必要时需要多添加一些从服务器。针对分析类应用,这里引入了一个数据提炼(Data Refinery)单元,用于数据的清理和组织。
超大规模(Extra Large)网站参考架构
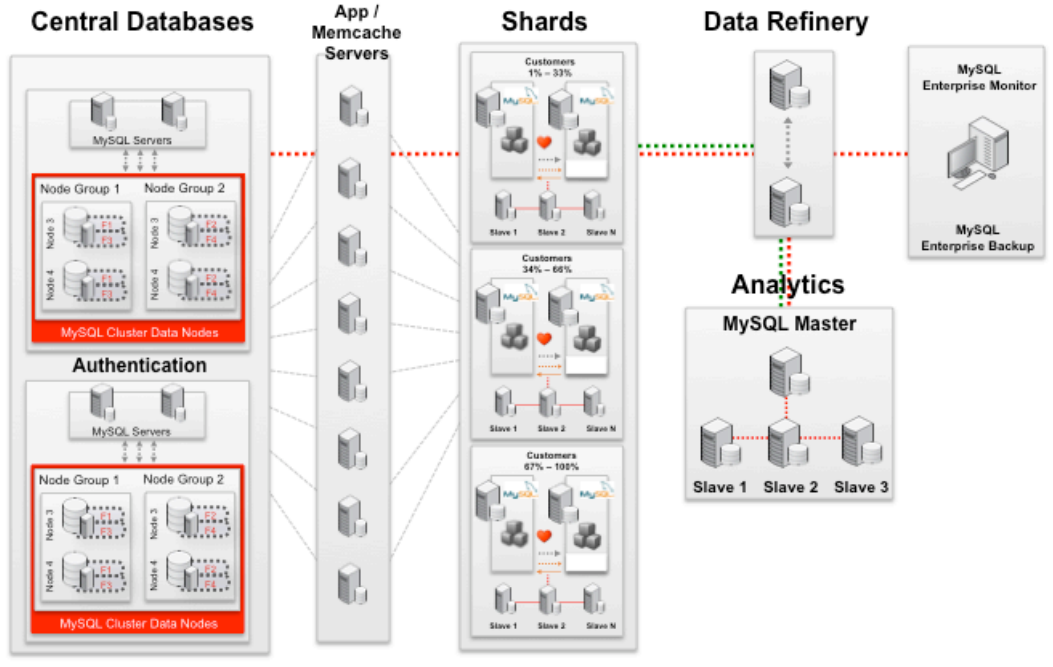
针对社交网站,白皮书也给出了相应建议。它声称“网络上流量最大的 10 个网站有 9 个部署了 MySQL,其中包括 Google、Facebook 和 YouTube”,但是没有说明这些网站用 MySQL 干什么,不过众所周知的是,LinkedIn 成功应用了 MySQL。
社交网站的拓扑结构利用了中型和大规模网站中实现的概念,包括专用应用服务器、Memcached 和数据提炼单元, 但为支持写操作的向外扩展引入了分片(Shard)。MySQL 集群被用于用户的认证和查找,当“用于查找的键(key)不止 1 个”时,直接读写相应的分片。
MySQL 主服务器和从服务器的推荐规格如下:
- 8–16 个 x86-64 位 CPU 核心(MySQL 5.5 及以上)。
- 4–8 个 x86 -64 位 CPU 核心(MySQL 5.1 及更早版本)。
- 比活动数据多 3–10 倍的内存。
- Linux、Solaris 或 Windows 操作系统。
- 最少 4 块磁盘,8–16 块磁盘能增加 I/O 密集型应用的性能。
- 支持电池供电高速缓存的硬件 RAID。
- 推荐使用 RAID 10。如果负载为读密集型,RAID 5 也是合适的。
- 2 个网卡和 2 个供电单元用作冗余。
另外,白皮书还有一些针对 MySQL 集群和数据存储设备的建议,再就是用于监控、备份和集群管理的解决方案。
查看英文原文: MySQL Reference Architectures for Small to Extra Large Websites




