曾经风靡一时、估值一度达到 2 亿美元的 Digg ,因为两年前一次失败的改版,人气大跌,并失去公众对它的关注,创始人 Kevin Rose 也无奈离开。前不久,更是以 50 万美元的价格被 Betaworks 收购剩余资产(Digg 实际的收购价格为 1600 万美元左右,详见)。
Will Larson 曾经担任 Digg 的工程总监,他在一篇博客中,回顾了Digg 从2010 年5 月到2012 年5 月公司的研发团队架构和流程。
团队架构
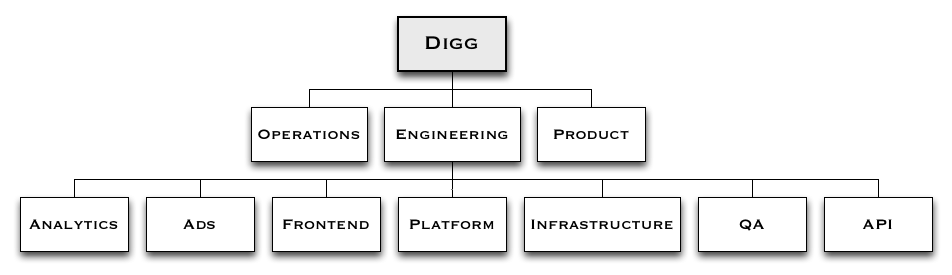
一开始,Digg 的组织架构很传统,产品、运维和工程团队各自独立。产品团队只有4 名成员,8 个工程师构成运维团队,QA 有6 个人,研发团队有大约20 人。
研发团队本身分为4 个水平团队:前端、API、平台和基础设施,两个垂直团队:广告、分析。产品团队在功能上掌控垂直团队,与多个水平研发团队协调。
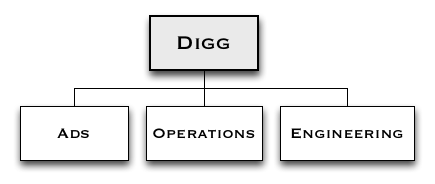
此后,由于人员流失,组织结构变得更为简单。运维团队只有3 个人,工程团队7 个人,广告工程团队4 个人。
代码评审和持续部署等实践
Digg 的核心开发实践让他们的开发人员一度达到 40 个人,后来降到 14 个人。
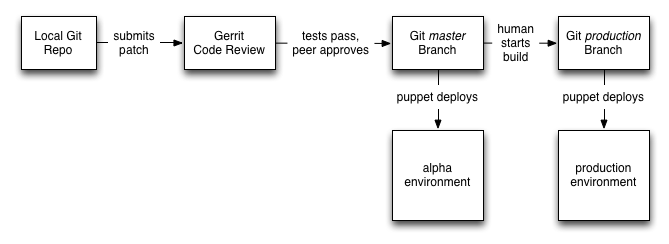
他们使用 Git 管理源代码, Gerrit 做代码评审。所有的代码都要得到同事的评审和通过,并通过所有的单元测试。
有代码补丁提交到 Gerrit 等待评审时, Jenkins 会自动运行单元测试,并将测试结果更新到 Gerrit 中,也就是说评审代码的人不会浪费时间去看失败的补丁代码,这样的代码也无法进入 Git 代码库中。
一旦 Gerrit 中补丁代码通过测试和评审,它们就会被合并如 Git 的 master 分支, Puppet 会将其自动部署到 alpha 环境中,在其中成功通过集成测试后,这些新的补丁代码会合并到 Git 的生产环境(production)分支。
向生产环境的部署是手工构建 Jenkins 方式完成的,接下来会使用 Puppet 一起部署更新代码。
开始时,他们使用了持续部署的方式向生产环境部署,但是出现一系列问题后,他们决定还是先让人工方式参与进来。
Will 这样说道:
如果我们当时坚持使用持续部署,我们最终会改善我们的测试,使得错误代码很难通过,但在当时,我们觉得投入那么多时间做这个并不值得。
Will 认为这个评审、测试和部署系统是 Digg 当时最重要、最成功的开发流程系统,足以让 40 个人的团队开发出高质量和一致性的代码,也不会让 14 个人的团队被流程拖慢效率。
在不断的实践中,Digg 慢慢涌现出一些新的实践,虽然未经详细研究,但它们确实来自日常实践。
刚开始,他们的单元测试覆盖率非常高,随着团队人员所见,他们写的单元测试就非常少了。虽然没有人明说,但是他们相信:单元测试并不能减少他们遇到的绝大部分问题:在高负载下,生产环境多个组件出现问题,最终导致系统故障;前端呈现问题。此后几年中,单元测试还一直可以提供价值,但是 Selenium 测试在没有人主动维护之后,很快就过时了,而且很快退出舞台。
他们使用 Thrift 定义前端和平台团队之间的接口,因此团队之间的沟通和协调非常直接。
他们很少变更已有 Thrift 接口的行为,如果需要新功能,他们会推出新的接口,更新客户端来使用这些功能,然后移除旧的接口。虽然这个流程貌似奇怪,但是由于他们的前端和后端代码各自独立部署(部署所有的前端或后端服务器只要几分钟),这种做法理智、安全。
新的前端变更只会推送给一部分用户,如果有问题就会禁用。虽然他们一开始想用这种方法来完成新功能的 A/B 测试,但是其最大的价值在于管理版本发布,并从一小部分可信用户那里获得反馈。
在发布可能会影响性能或负载的后端功能时,他们都使用不宕机的方式。
康威定律下的“架构”
在 Will 看来,对比下他们的 v4 版本架构和他们设计这个版本时的组织架构,这基本上就是康威定律(Conway’s Law【注】)的直接表现。
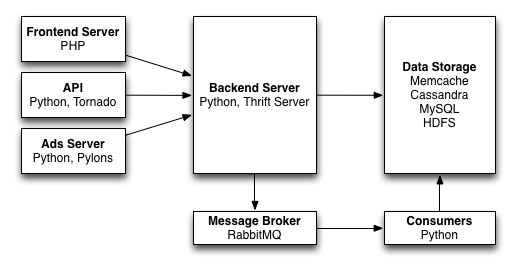
他们当时的构成是:一个 API 团队和一台 API 服务器、一个前端团队和一台前端服务器、一个平台团队和一台后端服务器、一个广告团队和一台广告服务器、由基础设施团队管理的一大堆数据存储,以及一个分析团队使用的 Hadoop 集群。前端团队使用无状态的 PHP、HTML 和 JavaScript 开发,状态和存储由后端服务器管理,消息队列用来处理长时间运行和非事务处理。
他们最不一般的做法,是用基于 gevent 的 Thrift 服务器作为后端服务器,因此在 gevent 和开发 gevent 安全的客户端池上耗费了很多时间。
我可能再也不会用 Thrift 作为 Python 服务器了,因为再也不想维护一个类似的服务器。
他们同时使用 Tonardo 、Apache+ mod_wsgi + Pylons 、gevent 服务器作为后端服务,虽然让 Will 有点不爽,但是在实际工作中,整个团队并没有多大困扰,主要原因是使用了 Jenkins 和 Puppet 来部署系统。
在总结中,Will 认为:
我们的流程和结构还是比较合理的,而且也很有效。如果今天重头来过,我们当然会有不一样的方式,或者要是我们的团队没有那么快减员,或者要是我们没有同时应对那么多技术债务,包括遗留系统、API 和代码契约等等。
Will 还想再谈谈 Digg 的数据库和技术方面的不断扩展,他们用过的技术包括:Cassandra、MySQL、Redis、Memcache、HDFS、Hive、Hadoop、Tornado、Thrift 服务器、PHP、Python、Pylons、Gevent 等等。请关注 InfoQ 中文站的后续报道。
注:
康威定律:Conway’s Law,由计算机科学家 Melvin Conway 在 1968 年提出,其内容是:设计系统的组织,最终产生的设计等同于组织之内、之间的沟通结构。




