
上一篇文章我们介绍了和Unicode 有关的匹配问题,这篇文章我们主要讲述一下Unicode 编码本身的特性,以便更好地运用正则表达式解决与Unicode 相关的问题。
Unicode Code Point
Unicode 字符多种多样,除去 ascii 中的字母、数字、标点和中文字符,还包括其它多种语言和多种符号,有些符号甚至很难打出来(比如表示商标注册的?),这时候该如何表示呢?再说远一点,如果我们想用一个字符组匹配所有中文字符,能不能像『[a-z]』那样呢?
所幸,每一个 Unicode 字符都对应自己的 Unicode 编码,也就是 Unicode 编码表中的一个代码点(Code Point),所以在正则表达式中的 Unicode 字符往往采用 Unicode 代码点来指定。
一般来说,指定代码点的形式有 3 种:『\uxxxx』、『\u{xxxx}』、『\x{xxxx}』(其中的 xxxx 为编码的值,\u 之后必须有 4 位 16 进制数字)。.NET、Java、JavaScript 和 Python 使用第一种方式,而 PHP 和 Ruby 使用第二种方式(Ruby 1.9 以上版本才支持这种表示法),PHP 使用第三种方式。
比如“发表”的“发”字对应的 Unicode 编码是 53 d1,它在不同语言中的表示法如下:所以我们可以在.NET、Java、JavaScript 的正则表达式中这样表示“发”字:“\u53d1”,Python 稍有不同,必须使用 u”\u53d1”(之前的 u 表示这是一个 Unicode 字符串); Ruby 中,“发”则必须写作”\u{53d1}”。
现在以“发”字为例,介绍不同语言中的 Unicode 表示法:
编码
语言
表示法
备注
53 d1
.NET
\u53d1
Java
\u53d1
JavaScript
\u53d1
Python
\u53d1
必须使用 Unicode 字符串,Python 2.x 中,要在字符串之前加 u
Ruby
\u{53d1}
限 Ruby 1.9 以上版本,且必须显式指定 Unicode 模式
PHP
\x{53d1}
必须指定 Unicode 模式
既然可以这样指定 Unicode 字符,自然也可以在字符组中用范围表示法指定一个 Unicode 编码范围了。比如,我们查询 Unicode 编码表可知,中文的编码一般在 4e00 到 9fff 之间,所以可以用这样的字符组匹配中文字符(Unicode 编码 4e00-9fff 归类为“CJK 统一表意符号”CJK Unified Ideographs [1] ,涵盖了绝大多数中文字符):
语言
字符组
备注
.NET
[\u4e00-\u9fff]
Java
[\u4e00-\u9fff]
JavaScript
[\u4e00-\u9fff]
Python
[\u4e00-\u9fff]
必须使用 Unicode 字符串,Python 2.x 中,要在字符串之前加 u
Ruby
[\x{4e00}-\x{9fff}]
限 Ruby 1.9 以上版本,且必须显式指定 Unicode 模式
PHP
[\u{4e00}-\u{9fff}]
必须指定 Unicode 模式
根据 Unicode 规范,每一个 Unicode 字符除了有唯一代码点对应,还具有其它属性,现在详细介绍三种属性,它们是:Unicode Property、Unicode Block、Unicode Script,下面的图粗略说明了这三者的关系。
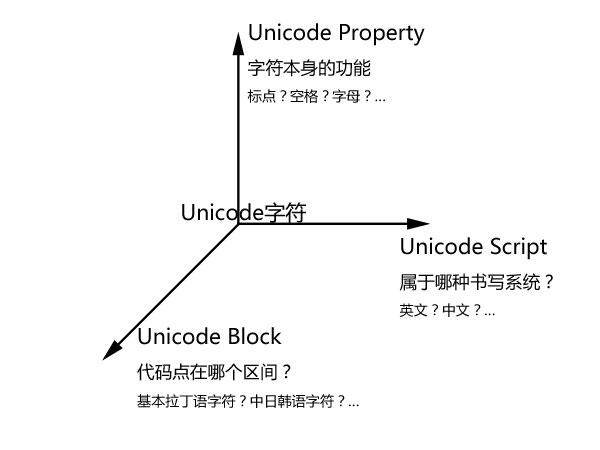
Unicode Property
Unicode Property 的记法类似『\p{L}』、『\p{Lo}』,它按照字符的功能分类 Unicode 字符,而不关心字符属于哪种语言,每个 Unicode 字符只能属于唯一 Unicode Property。
举例来说,『\p{Z}』表示任意的空白字符或不可见的分隔符;『\p{P}』表示任何标点字符,等等。遇到中英文混排、全角半角同时出现的情况,我们就可以用『\p{Z}』匹配所有的空白字符(而不用关心空格到底是全角空格还是半角空格),用『\p{P}』匹配所有的标点字符(而不用关心逗号到底是中文逗号还是英文逗号),而不用费心细节。
如果我们把 Unicode Property 理解为一个“字符组”,那么它一定能对应某个排除型字符组,此排除型字符组的通行记法是将『\p{xx}』中的小写 p 改为大写 P,写作『\P{xx}』。这样,『\P{Z}』对应『\p{Z}』无法匹配的字符,『\p{P}』对应『\p{P}』无法匹配的字符。Unicode Block 和 Unicode Script 对应的排除型字符组也是这样标记,下面不再赘述。
支持 Unicode Property 的语言有.NET、Java、PHP 和 Ruby(限 1.9 以上版本),在 PHP 和 Ruby 中使用 Unicode Property 时,必须要开启 Unicode 模式,下面以『\p{P}』的匹配为例:
.NET
Regex.IsMatch(‘,’, “\\p{P}”); //true
Java
“,”.matches(“\\p{P}”); //true
PHP
preg_match(‘/\p{P}/u’, ‘,’); //1
Ruby 1.9
‘/\p{P}/u’ =~ ‘,’ # 0
Unicode Property 的完整信息,可参考 http://www.regular-expressions.info/unicode.html 。
Unicode Block
Unicode Block 则不同于 Unicode Property,它按照编码区间划分 Unicode 字符,每个 Unicode Block 中的字符编码都是落在同一个连续区间的。因为 Unicode 编码表中,某种语言的字符通常是落在同一区间的,所以它也可以粗略表示某类语言的字符,比如\p{InHebrew}表示希伯莱语字符,『\p{InCJK_Compatibility}』表示兼容 CJK(汉语、韩语、日本语)的字符。如果你细心观察,会发现 Unicod Block 的名字虽然类似某种语言的名字,但都有“In”(Java 风格)或者“Is”(.NET 风格)前缀,这表明它其实对应的还是“落在某个区间的 Unicode 字符”。
本书介绍的语言中,只有 Java 和.NET 支持 Unicode Block,它们的写法不相同:
Java:『\p{ InCJK_Compatibility_Ideographs }』
.NET:『\p{ IsCJK_Compatibility_Ideographs }』
我们可以在 Java 中用\p{InCJK_Compatibility}或者在.NET 中用\p{IsCJK_Compatibility}粗略匹配中文字符,虽然它们可能匹配日文或者韩文字符,尚不够精确,但许多情况下确实够用了。
Java
“我”.matches(“\\p{InCJK_Compatibility_Ideographs}”); //true
.NET
Regex.IsMatch(‘我’, “\\p{IsCJK_Compatibility_Ideographs}”); //true
Unicode Block 的完整信息,可参考 http://www.regular-expressions.info/unicode.html 。
Unicode Script
Unicode Script 按照字符所属的书写系统来划分 Unicode 字符,比如\p{Greek}表示希腊语字符,\p{Han}表示汉语(中文字符)。它的写法类似 Unicode Block,只是名字的开头没有“Is”或者“In”。
在本书介绍的语言中,只有 PHP 和 Ruby(限 1.9 以上版本)支持 Unicode Script,PHP 在使用 Unicode Script 时,必须开启 Unicode 模式(详见 xx 页)。在这两种语言中,我们可以很方便地用\p{Han}来匹配中文字符。
PHP
preg_match(‘/\p{Han}/u’, ‘我’); //1
Ruby 1.9
/\p{Han}/u =~ '我' #0
Unicode Script 的完整信息,请参考 http://www.regular-expressions.info/unicode.html 。
小结
用正则表达式处理包含多字节字符(比如中文)的字符串时,最好使用 Unicode 编码,否则多字节字符很可能被割裂为多个字节,导致匹配错误,最好的办法是使用 Unicode 编码。
如果实在不能使用 Unicode 编码,使用字符组时要尤其小心,普通字符组可以用多选分支取代,绕过隐患,但这种办法对排除型字符组行不通。
如果设定了 Unicode 模式,可以指定 Unicode Code Point 来表示某个字符,但不同语言中的记法不同,可能是\uxxxx、\u{xxxx}、\x{xxxx}。
Unicode Property 描述 Unicode 字符的属性,.NET、Java、PHP 和 Ruby(限 1.9 以上版本)中可以使用 Unicode Property。
Unicode Block 描述 Unicode 字符所在的区间,其特征是名称以 In 或 Is 为前缀,.NET 和 Java 中可以使用 Unicode Block。
Unicode Script 描述 Unicode 字符所在的书写系统,名字类似 Unicode Block,但没有 In 或 Is 前缀,PHP 和 Ruby(限 1.9 以上版本)中可以使用 Unicode Script。
无论 Unicode Property、Unicode Block、Unicode Script,其对应的排除型字符组都是将开头的\p 改为\P,其它不变。
无论 Unicode Property、Unicode Block、Unicode Script,都可以视为普通字符组,在字符组 […] 中进行拼接组合,比如在 PHP 和 Ruby 中,[\p{Han}\p{Po}] 既可以匹配汉字字符,又可以匹配任何标点字符。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论