
Steve Huffman,Reddit 的共同创始人,分享了将 Reddit 从一个小型 Web 应用程序发展为大型社交网站过程中学到的主要经验。
Steve Huffman 和 Alexis Ohanian 在 2005 年创建了 Reddit,当时在一台机器上运行 Web 应用程序、应用服务器和数据库。发展至今,Reddit 已经成长为每月 750 万用户、2 亿 7 千万 PV 的站点。Huffman 在一次演讲中谈到Reddit 发展过程中学到的经验,他们犯的很多错误,以及他们是如何修复这些错误的。
1、宕机是家常便饭
起初他们经常宕机,Huffman 常常睡在笔记本电脑旁边,每隔几个小时就醒一下,看看网站是否仍在运行。当时的解决方案是使用 Supervise,那是一个能重启崩溃应用程序的守护进程。这带来了一种很有趣的运行应用程序的方式:如果应用程序有内存泄露,或者消耗了太多的内存,只需终止它随后重启即可。这只是一个临时方案,而非最佳方案,最终是基于日志内容修复了应用程序。
2、服务分离
Huffman 建议将类似的进程集中在一台机器或一组机器上,这样可以避免频繁的上下文切换,减少资源消耗。他还提供了一个最佳实践——在一个数据库中处理类似的数据,以此避免频繁的索引缓存切换,将其他类型的数据移到别的机器上去。
Huffman 强烈建议避免使用线程,在 Python 中这就是“死亡之吻,缓慢之道”。如果多个任务被分配到独立的进程而非线程上,那在请求量上升、需要更多资源的时候,就可以方便地将它们移到不同的机器上。这种做法的唯一问题就是进程间通信,除此之外都比使用线程要好,因为这样的架构能更平滑地进行扩展。
3、开放 Schema
随着数据库的发展,每个要更新 Schema 的新特性都会带来更多的问题。向一个有 1 千万行数据的表中增加一个新字段需要很多时间,尤其是有备份 (backup)和复制(replication)时。他们当时虽然没有备份,但也花了好多天,因为他们构建了一个副本(replica)。
解决方案是使用开放 Schema 或实体 - 属性值,Key-Value 存储。现在每个数据类型有两张表:
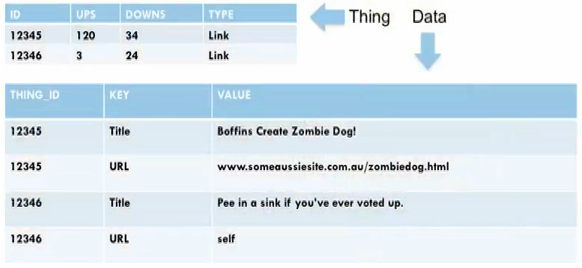
_Thing_ 可以是用户、链接、评论等,共享相同的 Schema。_Data_ 表由大量数据构成,但里面只有 3 个字段:ID、 Key 和 Value。在新的 Schema 中添加新特性并不涉及 Schema 的变更,也不需要创建新表。此外,再也没有数据库的 join 操作,这也易于数据库的拆分。
4、保持无状态
所有 Web 应用程序都有一个共同的目标,它的每台应用服务器都能处理任意请求。这个目标在只有一台机器时很容易达成(这是显而易见的),但当使用多台服务器并缓存应用状态时,情况就变得复杂了。每台服务器在访问缓存数据时的复杂性都增加了,而且还加入了更多的缓存冗余。
此处的解决方案是切换到 memcache 并在所有应用服务器上不再使用状态。一个立竿见影的效果是一台应用程序服务器宕机时不会影响其他服务器。此外,可以简单地通过增加更多服务器来进行扩展。
将缓存服务器与其他服务器隔离开是很重要的,这能避免资源争夺。
5、Memcache 所有内容
Reddit 的所有内容都使用了 memcache:数据库的数据、会话数据、渲染的页面、存储的内部函数、预先计算的页面、全局锁。它们还用 memcachedb 进行数据持久化。
6、存储冗余数据
“在你需要前,数据都保持正规化”会降低性能。当用户需要以特定格式来展现数据时,获取原始数据随即进行处理会延长响应时间,以至于用户放弃等待结果。解决方案是在内存和硬盘中保存数据的所有格式。这样做对磁盘和内存有些影响,但对用户请求的快速响应很有帮助。
对 Reddit 而言,速度的关键是“预先计算所有内容并放入 memcache。”
7、脱机工作
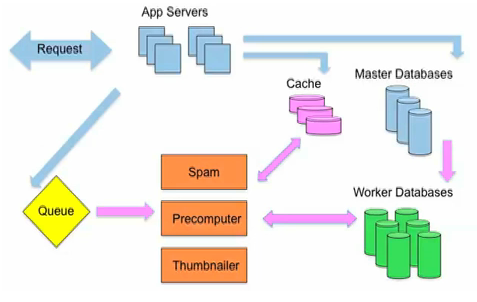
当用户发起请求时,系统要执行用于返回适当响应的必要工作,其他事情都放到队列任务中脱机执行。例如,脱机执行的工作包括:预先计算列表、获取缩略图、检测欺骗行为、删除垃圾信息、计算奖励以及更新搜索索引。当用户给某个链接投票时,他并不需要等待所有索引和列表更新完毕,这些任务可以在响应用户后再去执行。
下图中的蓝色箭头表示为响应用户请求所执行的活动,粉色箭头表示脱机执行的活动:
查看英文原文: 7 Lessons Learned at Reddit

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论