
Evan Weaver 是 Twitter 服务团队的总工程师,他的主要工作是优化与伸缩性。在 QCon London 2009 上,他谈到了 Twitter 的架构,特别是在过去一年当中为提升 Web 站点性能所执行的优化。
Twitter 使用的大部分工具都是开源的。其结构是用 Rails 作前端,C,Scala 和 Java 组成中间的业务层,使用 MySQL 存储数据。所有的东西都保存在 RAM 里,而数据库只是用作备份。Rails 前端处理展现,缓存组织,DB 查询以及同步插入。这一前端主要由几部分客户服务粘合而成,大部分是 C 写的:MySQL 客户端,Memcached 客户端,一个 JSON 端,以及其它。
中间件使用了 Memcached,Varnish 用于页面缓存,一个用 Scala 写成的 MQ,Kestrel 和一个 Comet 服务器也正在规划之中,该服务器也是用 Scala 写成,当客户端想要跟踪大量的 tweet 时它就能派上用场。
Twitter 是作为一个“内容管理平台而非消息管理平台”开始的,因此从一开始基于聚合读取的模型改变到现在的所有用户都需要更新最新 tweet 的消息模型,需要许许多多的优化。这一改动主要在于三个方面:缓存,MQ 以及 Memcached 客户端。
缓存
每个 tweet 平均被 126 个用户跟踪,所以这里有着明显的缓存需求。在最初的配置中,只有 API 有着一个页面缓存,当每次从一个用户那里来了一个 tweet 时就会失效,而应用的其它部分都是无缓存的:
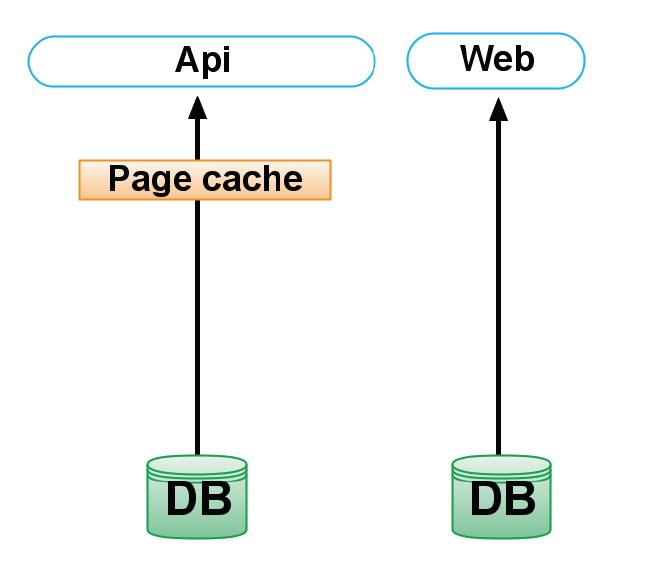
第一个架构改动是创建一个直写式向量缓存包含了一个 tweet ID 的数组,tweet ID 是序列化的 64 位整数。这一缓存的命中率是 99%。
第二个改动是加入另一个直写式行缓存,它包含了数据库记录:用户和 tweets。这一缓存有着 95% 的命中率并且使用了 Nick Kallen 的名为 Cache Money 的 Rails 插件。Nick 是 Twitter 的一名系统架构师。
第三个改动是引入了一个直读式的碎片缓存,它包含了通过 API 客户端访问到的 tweets 的序列化版本,这些 tweets 可以被打包成 JSON,XML 或者是 Atom 的格式,有着同样是 95% 的命中率。这一碎片缓存“直接消费向量,而且如果现在缓存了一个序列化的碎片,它不会加载你试图看到的该 tweet 的实际的行,因此它将在大量时间将数据库置于短路状态,”Evan 这样说到。
还有另一个改动是为页面缓存创建一个单独的缓存池。根据 Evan 的说法,该页面缓存池使用了一个分代的键模式,而不是直接的失效,因为用户可以
发送 HTTP 的 if-modified-since 并且将任何他们想要的时间戳放入请求路径,我们需要将这一数组切片并只呈现给他们他们想要看到的 tweets,但我们不想跟踪客户端所使用的所有可能的键值。这一分代的键模式有一个大问题,在于它不会删除所有失效的键值。每一个被加入的对应到人们所接收的 tweets 数目的页面都会向缓存推送有效的数据,最后变得我们的缓存仅仅只有五个小时的有效生命周期,因为所有的页面缓存都将流过。
当该页面缓存转移到其自己的池之后,缓存未命中降低了将近 50%。
这是 Twitter 现在所使用的缓存模式:
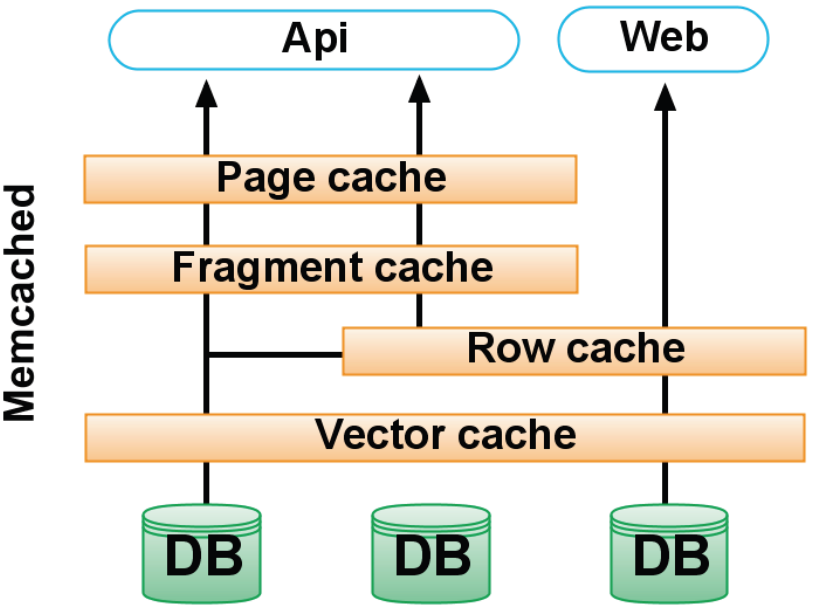
因为 80% 的 Twitter 流量都来自 API,因此还有额外的二层缓存,每一个最多将处理 95% 来自前一层的请求。整体的缓存改动总共有百分之二三十的优化,它带来了
10 倍的容量提升,它本可以更多,但现在我们遇到了另一瓶颈…我们的策略是首先加入直读式缓存,确保它正确失效,然后再转移到直写式缓存并且在线修复,而不是当一个新的 tweet ID 进来时每次都要销毁。
消息队列
因为,平均来说一个用户有 126 个追随者,这就意味着每个 tweet 将有 126 个消息在队列里。同时,流量会有出现高峰的时候,就像在奥巴马就职的时候达到了每秒几百个 tweet 或者说是成千上万的消息在队列里,是正常流量的 3 倍。MQ 应当去化解这一高峰并随着时间将其分散,这样就不用增加许多额外的硬件。Twitter 的 MQ 很简单:基于 Memcached 的协议,job 之间是无序的,服务器之间没有共享的状态,所有的东西都保存在 RAM 里,并且是事务性的。
第一版的 MQ 实现是用的 Starling ,以 Ruby 写成,伸缩性不佳,特别是Ruby 的GC 不是分代的。这将导致MQ 在某一点上崩溃,因为GC 完成工作时将会把整个队列处理中止。因此作出了将MQ 移植到Scala 上的决定,它有着更为成熟的JVM GC 机制。现有的MQ 仅仅只有1200 行代码并且运行在3 台服务器上。
Memcached 客户端
Memcached 客户端的优化目的是试图优化集群负载。现在的客户端用的是 libmemcached ,Twitter 是其最重要的用户和其代码库最重要的贡献者。基于此,持续一年的碎片缓存优化带来了 50 倍的每秒页面请求服务增加。
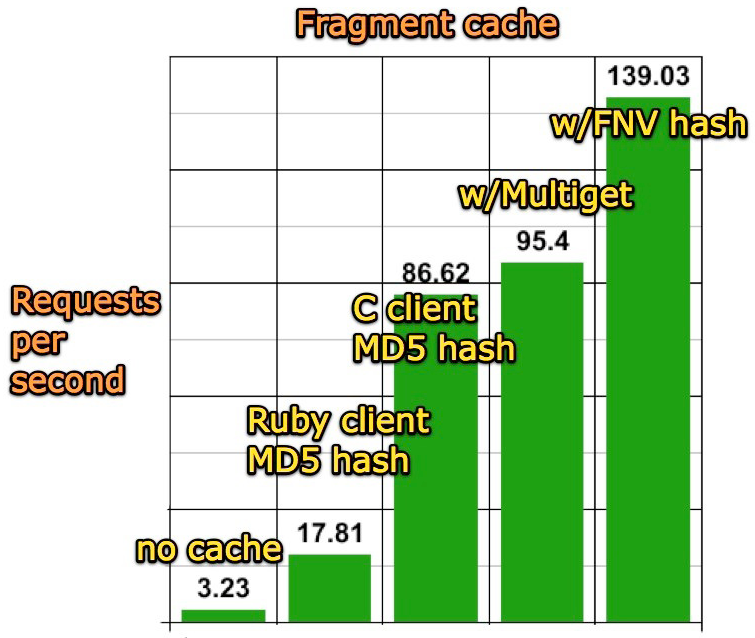
因为请求来自的位置难以确定,处理请求最快的办法就是将预先计算好的数据存储在网络 RAM 上,而不是当需要的时候在每个服务器上都重新计算一次。这一方式被主流的 Web 2.0 站点所使用,它们几乎都是完全直接运行于内存之上。根据 Evan 的说法,下一步就是“既可伸缩的读持续了一年之后,(解决) 可伸缩的写,然后就是多协同定位的问题”。
这一 QCon 的演示文件发布在Evan 的站点上。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论