


卷首语:亚马逊首席科学家李沐构建深度学习开源生态的努力和思考
作者:李沐
过去 10 年我们可以认为从 2012 年至 2015 年是深度学习的开始算法上的突破让深度学习得到应用 2016 年至 2017 年随着资本、媒体的介入深度学习和 AI 被大家所熟知 2018 年到 2020 年可以认为是用户趋向理性的阶段。我们知道了机器学习的一些局限性我们也看到了深度学习在过去几年不断地被简化并且成功应用到工业界。
深度学习发展的三个阶段
针对上述三个阶段我们做过的思考也是不一样的。深度学习的黄金时代是 2012 年到 2015 年。2012 年 AlexNet 赢下了 ImageNet 这被认为是深度学习热潮的开端。AlexNet 与传统模型不一样的地方在于其有数十层神经网络以及需要用多个 GPU 才能够有效训练这两点使得开发过程非常困难这也导致了大量开发者需要专有的深度学习框架才能进行深度学习开发。当时我们的第一个尝试是做一个 TheanoTheano 是一个很早期的神经网络框架非常灵活但是比较慢。所以我们思考能不能做一个 C++ 版的 Theano 使得它能更快一点做出来后发现特别像 Caffe。第二个同时期的项目是 Minerva 我们想把 NumPy 拓展到 GPU 和自动求导上使得深度学习能够用 NumPy 来开发。
这两个项目我们当时做得都不是那么完善 C++版本的 Th e ano 虽然高效但是不那么灵活 Minerva 灵活但是并不那么高效。
2015 年的时候我们在思考要不要把这两个项目的所长结合在一起这个项目的名字叫做 MXNet 之后进入了 Apache 基金会。当然同年还有很多神经网络框架出现包括在日本开发的对 Python 很友好的 Chainer、Keras Theano 易用前端以及 TensorFlowTheano 增强版。
2016 年到 2017 年有两个比较大的趋势第一个是自然语言处理等应用的兴起。自然语言的兴起使得需要更灵活的前端原因是自然语言处理直接处理的是文本有不一样的长度结构可能也比较复杂对模型的要求也更高第二个趋势是大量新用户涌入需要门槛更低的框架最典型的一个框架是 PyTorch 它继承了来自于 Torch 大量的特性并借鉴了 Chainer。看到 PyTorch 的兴起我们也借鉴了 PyTorch 的特性推出了 Gluon 前端。
至于 MXNet 其有三大可以关注的特性第一我们有类似于 Numpy 的张量计算 NDArray 第二用户可以通过 Gluon 在 Python 比较友好的情况下进行神经网络的构建和训练第三通过 hybridize 切换到计算图后端来优化和脱离 Python 部署。
2018 年到 2019 年我们看到深度学习的热度在下降这时候 Theano 停止了开发 Karas 进入到了默认前端 Torch 和 Caffe 停止了开发继任者 Caffe2 也并入了 PyTorch。目前市面上比较流行的框架 TensorFlow 其具备强大的后端和生态链使得它广泛地被公司开发者使用而 PyTorch 灵活的前端使其广受研究者的欢迎。
我们尝试让 MXNet 像 TensorFlow 一样好有强大的后端甚至能像 PyTorch 一样有比较灵活的前端使它能够平衡研究者和工业级用户。当然这个远远不是结局随着硬件需求的不断变化系统也需要不断地迭代。
在 2019 年到 2020 年我们做了两大比较重要的事情第一我们将 Tensor API 完全兼容 NumPy 因为我们发现大部分 Python 用户在学习机器学习或者深度学习之前已经接触过 NumPy 但是 NumPy 还是不够被深度学习用户所使用我们需要对 NumPy 进行 GUP 加速以及提供求导。在过去 5 年的技术积累上我们也在编译器上做了大量工作终于使得我们可以完全进入 NumPy 而且保证性能使用起来也很方便。
同时我们提到深度学习框架基于 Gluon 但是我们还是需要用户来 hybridize 到后端计算图使得用户需要考虑一些事情。现在用户不需要再考虑计算图和符号因为我们的优化已经做得足够好。用户只需要关心怎样在 Python 上使用 NumPy 接口来实现它的代码然后系统可以将所有的代码转化成计算图并且脱离 Python 来执行。
2017 年当大量用户进来的时候我们观察到一个现象当下的用户不再为深度学习框架感到兴奋而是当它们本应该存在。那么这时候快速落地最为关键。如何有效、高效地处理数据能够快速地训练模型然后能够流畅地部署这是用户关心的问题。因此我们于 2017 年的时候在框架的基础上开始开发算法工具包方便特定领域模型的训练和部署包括面向计算机视觉的 GluonCV。
在算法工具包开发的过程中我们经历了两个阶段第一个阶段我们更关注细节我们保证每个模型都能提供很好的精度。我们发现论文中很多细节都被一笔带过于是我们在实现 GluonCV 的时候调用了大量的论文和代码然后尝试把所有细节都用在一起。
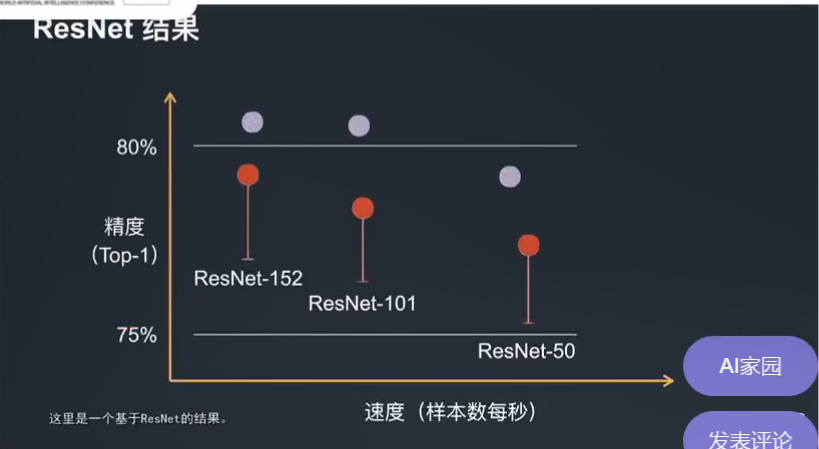
下图是一个基于 ResNet 的结果显示了三个 ResNet 模型 X 轴表示速度 Y 轴表示精度可以看到每个红色点的最上方横线是此模型在论文中的精度 ResNet-50 是最快的精度也是最低的 ResNet-152 和 ResNet-101 虽然比 ResNet-50 要慢但是它们的精度也要更高。如果我们能将一些训练的技巧运用过来可以看到它可以对整个模型进行显著的提升。如果允许模型进行细微的调动在不影响太多速度的情况下我们能更加进一步地提升它的精度。
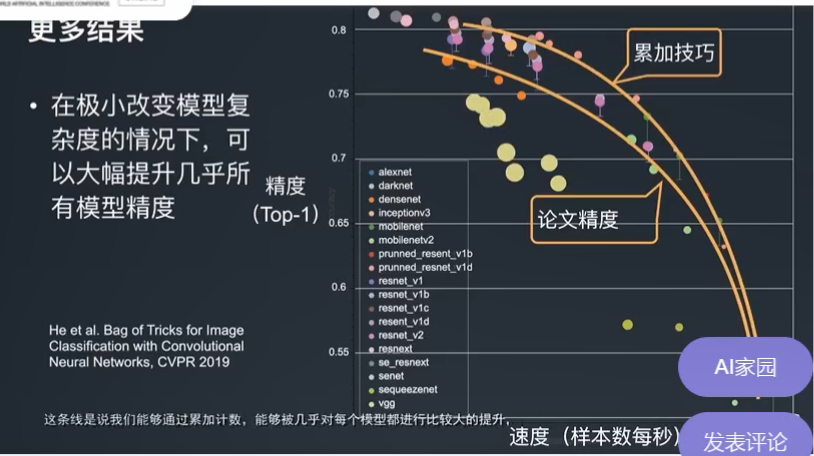
更多地我们发现这些结果不仅仅对一个模型适用几乎可以改变所有模型的精度。如下图所示可能两条黄线的区别看起来不大但实际上可能代表的是计算机视觉近几年的一些进展的总和。
工具包开发的第二个阶段是我们能够做一些解决用户问题的研究。举个例子迁移学习是深度学习在计算机视觉领域兴起的一大原因我们可以通过训练好的深度卷积神经网络来抽取图片的语义特征然后用在其他诸如物体识别、图片分割等任务上。但是深度卷积神经网络的研究主要关注在能够得到更好的 ImageNet 分上实际使用中大家仍然主要使用结构简单的 RestNet。
我们的想法是在不改变 ResNet 结构的前提下加入分裂注意力层使将其能更好抽取语义特征。我们还在 GluonCV 之外开发了面向自然语言处理的工具包 GluonNLP。NLP 和计算机视觉不一样的地方在于它的应用比较多样化。
此外我们比较关注的方向是加速 BERT 在工业界的应用。我们第一个工作是在公有云的硬件上将 BERT 训练时间减少到一个小时之内之前在一个小时之内的结果都是基于特制的集群。第二个工作是我们在 AWS G4 实例上一百万次的 BERT 推理开销降到 1.5 元钱以内。这样就使得 BERT 能够大量地、很便宜地应用在工业界的应用上。
如何入门深度学习
2018 年随着 AI 和深度学习的广泛普及我们不断收到用户和工程师的反馈他们都在询问想要学习深度学习但是不知道如何开始。学习深度学习需要知道数学、模型、调参、实现、性能一样都不能少。对我个人而言我发现最好学习的方法是将文字和公式转换成代码并在实际数据上跑上几次才能大概知道怎么回事儿。
在过去几年我们针对不一样的用户提供了不一样的工具针对骨灰级用户我们提供深度学习框架对资深用户我们提供 Python 更加友好的前端针对入门用户我们提供算法工具包。
那么在接下来一年里我们也在针对不一样的用户群做不一样的突破面向所有学生和工程师基于 AutoML 技术使得用户不再需要费时调参技术继续下沉在编辑器层面拓展硬件支持、加速深度学习训练和推理任务。
目录
生态评论
AI 芯片从未成功过?
重磅访谈
Linux AI 基金会董事会主席星爵:国产开源需要更多利他主义丨开源创新 30 人
落地实践
进击的 Flink:网易云音乐实时数仓建设实践
企业机器学习平台
谷歌大脑开源项目 AutoML-Zero:仅用数学运算就能探索出机器学习算法
推荐阅读
Go 语言之父:四十年来软件开发之巨变与 Go 的过去和未来
精选论文导读
百度凤巢提出新一代广告召回系统 MOBIUS | 技术深度解读














评论