


研究背景
InfoQ 研究中心近期专注于大型语言模型产品的市场动态和性能特点,深入分析了这些模型在多个关键维度上的表现。本研究围绕语义理解、文学创作、知识问答、逻辑推理、编程、上下文理解、语境感知、多语言处理及多模态交互等十大核心领域,对包括 ChatGPT-4、文心一言专业版、通义千问 V2.1.1、Bard2.0、讯飞星火 V3.0、Kimi Chat 网页版、百川大模型 V1.0、智谱清言网页版、360 智脑 4.0 和豆包在内的十款热门模型进行了全面评估,测试题目数量超过 3000 道。
在本次研究中,我们特别增加了对逻辑推理、商业写作及多模态能力这三个关键领域的测试权重和比例,以更准确地评估各模型在这些重要方面的实际表现。InfoQ 研究中心希望通过这次评估,帮助技术领域的同仁更深入地了解国内外大型模型产品的性能、稳定性和准确性,从而为大模型的持续进步和应用实施提供参考和助力。
中国大模型及产品图谱
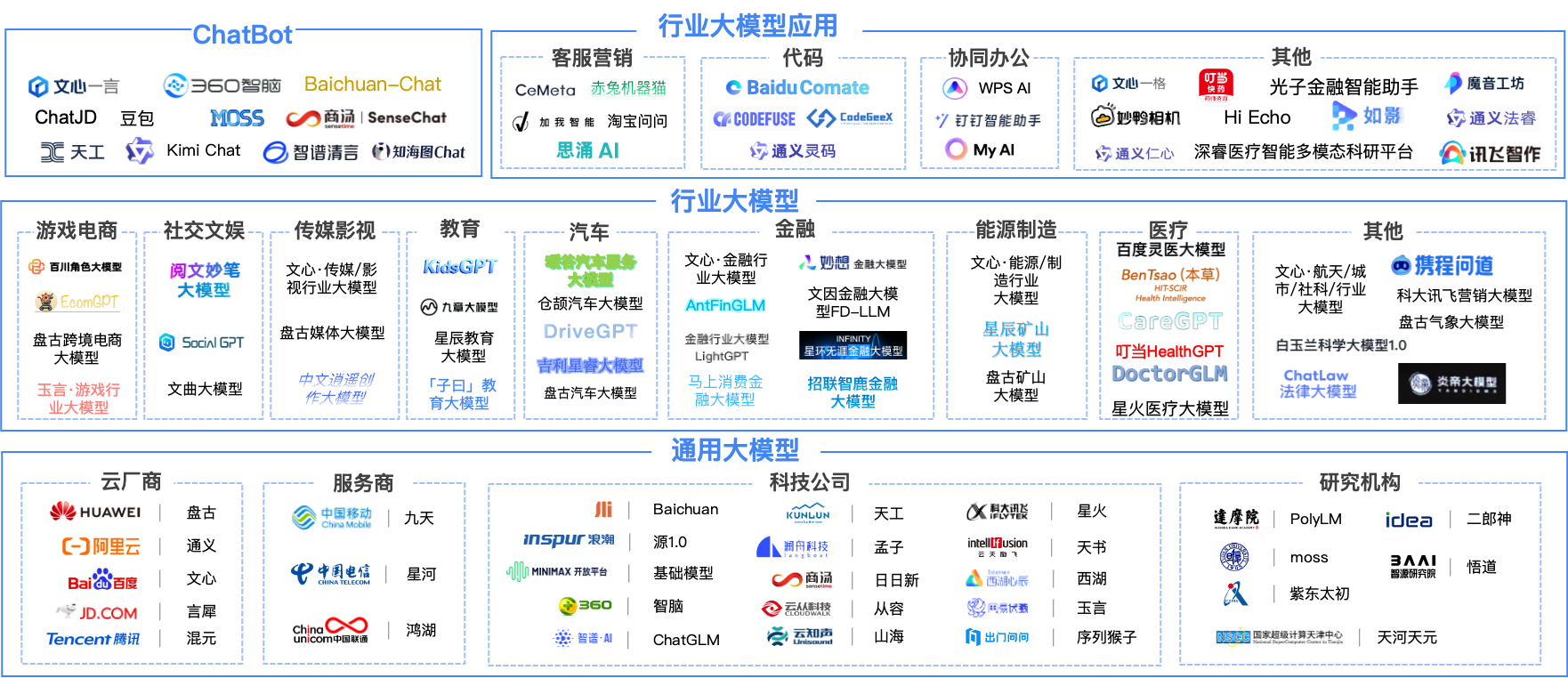
进入 2023 年下半年,国内的大型模型已经进入了一个显著的成长阶段。不仅模型的数量呈现出爆炸式的增长趋势,而且模型的质量也在持续提升。随着首批国产大型模型完成备案并向公众开放,这些模型正在越来越多地进入用户的视野和认知中。
据最新统计数据显示,在目前的市场上,GPT 系列大型模型和百度文心大型模型已经稳居第一梯队,受到了广泛的关注和应用。近半数的受访开发者表示,他们了解或使用过这两款模型,这充分证明了它们在行业内的领先地位和影响力。
而阿里通义大型模型、LLaMA 2、讯飞星火大型模型、华为盘古大型模型以及智谱 Chat GLM 3 大型模型则构成了第二梯队。这些模型也受到了不少开发者的关注和使用,超过五分之一的受访者表示了解或使用过它们。
此外,还有一批新兴的大型模型正在崭露头角,它们包括百川大型模型、Stable Video、Diffusion、昆仑万维天工大模型、360 智脑大型模型、MOSS 大型模型、智源悟道大型模型以及商汤科技的商量 Sense Chat 等,这些模型共同构成了第三梯队。
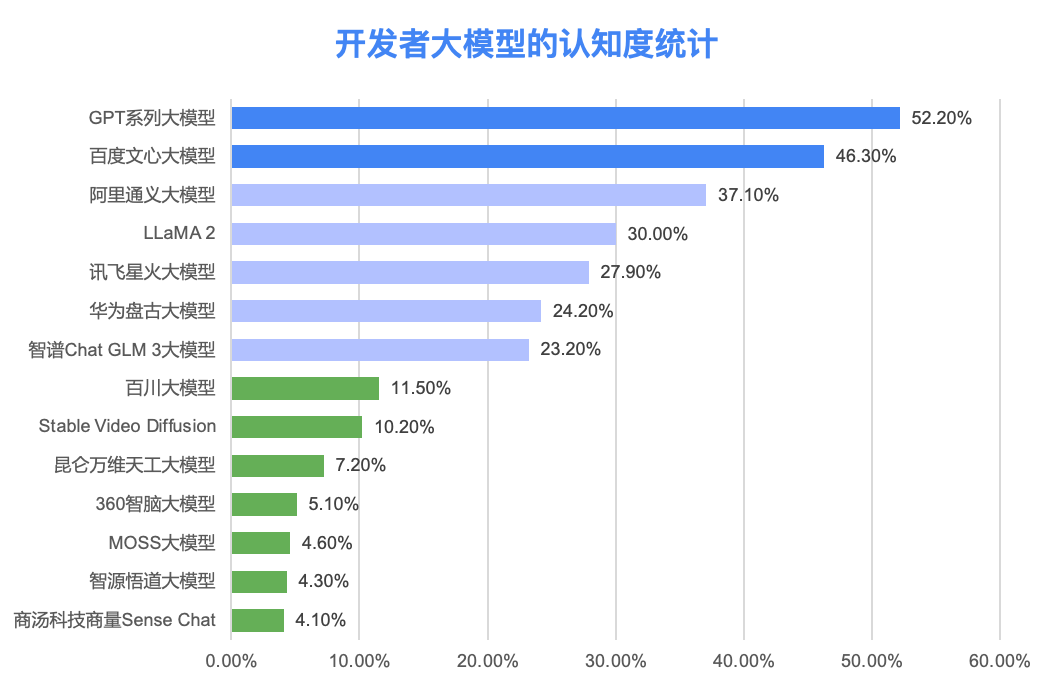
上图数据来源:2023 年 12 月 InfoQ 发起的用户调研,N=1217
测评结果
相较于 2023 年 5 月的测试结果,本次测试的整体得分率平均提升了 23.39%,各项性能均取得了明显的进步。反映大模型基础能力的认知和学习能力稳步提升,历史、地理、商业、医学、科学等领域,大模型依旧保持高水平。值得一提的是,反映大模型进阶能力的题目得分率平均提升了 35.77%;文生图、文生语音的多模态题目得分率相较于以往提高了近 20 倍,文心一言专业版、讯飞星火、ChatGPT-4 等多项产品开始展现出强大的多模态能力,为大模型的发展开辟了更广阔的前景。
测评领域整体得分情况
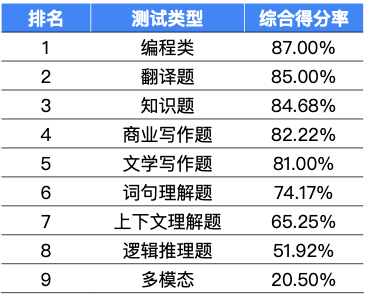
与 2023 年 5 月的测评结果对比
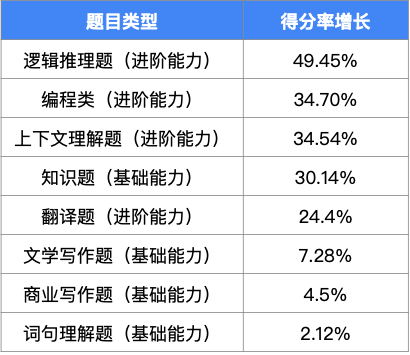
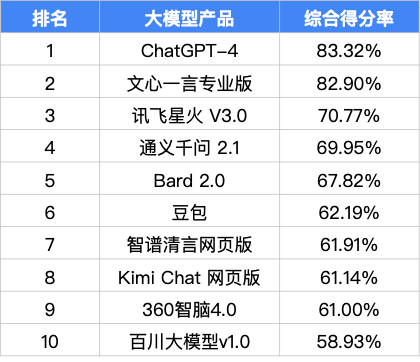
各大语言模型测评结果
根据测试结果显示,ChatGPT-4 的综合能力位居第一,文心一言专业版以 82.90%的综合得分位列榜单第二名。令人惊喜的是,文心一言的得分与 ChatGPT 得分非常接近,仅仅落后 0.42%。








评论 (1 条评论)