
背景
在容器化的基础上,我们已经通过一些手段,比如监控分析、弹性伸缩等降低了 k8s 集群的成本,取得了一定的成效。
但是深入分析下来,集群资源使用还是有不小的优化空间。当然,成本和稳定性总是对立的,这就要求我们更精细、更深入业务进行资源的优化,以同时保证应用的稳定性不受影响。因此,进一步的资源优化,我们围绕云原生和 k8s 本身的功能特性和架构优势,从具体业务应用的特点着手,对 k8s 的弹性和调度等能力做了一系列的拓展和增强,以达成进一步降低成本,并能够不损失甚至持续提升应用稳定性的目标。
弹性伸缩
业务挑战 -1,如何有效推进业务接入 HPA?
Pod 水平弹性扩缩容是 K8s 的一个重要功能,随着应用迁移到 K8s,我们自然也上线了这一功能。但是,在实际落地中,却有一些问题导致弹性扩缩容的效果受到了很大影响,甚至很多应用因此未能开启弹性扩缩。这里简单列举几个比较普遍存在的问题:
由于 java 本身的特点和一些历史债务问题,很多核心业务的应用启动时间很长,这使得扩容出的 Pod 并不能及时分担线上流量,使得一些大流量的业务在业务高峰期可能会出现服务受损的情况。
有些应用如 kafka 消费者应用,由于每次 Pod 的扩缩容,都会触发到 kafka 的重平衡,造成对消息消费的影响,部分应用无法容忍较高频次的扩缩容动作。
… …
解决方案
基于上面提到的问题,我们需要 HPA 能够做到提前感知扩容,并尽可能的减少扩缩容的频次,减少无效的扩缩容。经过问题分析和对社区产品的调研,我们决定从多个方向来解决这个问题。其一,是引入 keda,借助丰富的 scaler 和自定义 scaler 的能力,支持通过自定义的业务指标及更灵活的扩缩策略,实现更精准的扩缩容。其二,引入了 crane 的 EHPA,实现基于流量预测的弹性扩缩。最后,对于扩缩容极端敏感的应用,还是无法容忍扩缩容带来的影响的话,使用固定的定时弹性扩缩容策略,由业务方自己指定扩缩容的时间和个数,实现扩缩容完全可控。
案例
通过 EHPA 提前扩容,减少无效缩容

如上图,EHPA 使用在数字信号处理(Digital Signal Processing)领域中常用的的离散傅里叶变换、自相关函数等手段,识别、预测周期性的时间序列。可以通过算法预测未来的流量洪峰实现提前扩容,及减少不必要的缩容,稳定工作负载的资源使用率,消除突刺误判,缓解抖动。
由于业务本身的特点,公司内部大部分核心应用,都有明显的高低峰周期,并且存在整点的流量突刺,这种流量突刺,对于常规的基于 CPU 使用率的 HPA 非常不友好,由于应用启动时间的问题,通常扩容的 Pod 启动完毕之后,已经过了突刺的时间,不仅无法帮助支撑突刺的流量,还造成了实际上的无效扩容。
基于 EHPA 的流量预测,我们优化了这类应用的弹性扩缩策略。如下图:
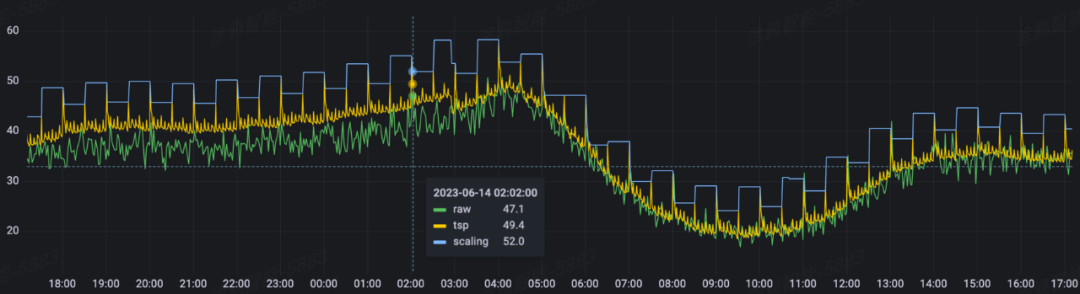
说明
绿色曲线:实际指标值
黄色曲线:基于历史数据预测的指标,能够做到较明显的感知到应用整点和半点的流量尖刺。
蓝色曲线:在黄色曲线的基础上,将黄色预测曲线 1800s(predictionWindowSeconds) 内的最大值作为预测指标的值,从而做到对应用提前扩容 Pod,应对流量尖刺。
可以看到,EHPA 有效的预测了应用流量的趋势和整点突刺,并且我们通过 predictionWindowSeconds 的配置,可以控制提前扩容的时间,由此解决了服务启动慢,和流量突刺的问题。
通过自定义业务指标,实现灵敏、精准扩容
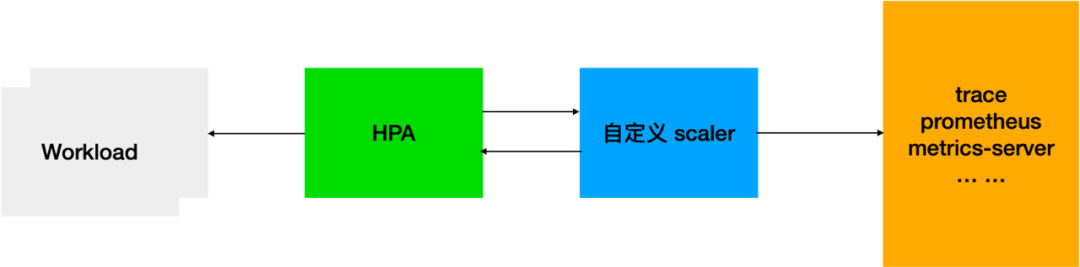
基于自定义指标的 HPA,自定义指标可以是消息队列长度、增长速率、接口耗时、qps 等,数据源可以是 trace、prometheus、metrics-server 等,然后编写自定义的 scaler 来对接这些不同的数据源。
公司基于 loki 建设了服务的日志系统,通过 loki-querier 组件进行分布式的日志查询。它的特点是无查询是基本无资源消耗,当有查询尤其是大查询时,会瞬间需要大量资源,因此很自然的希望借助 K8s 的 HPA 进行弹性扩缩容。起初是配置了常规的基于 CPU 弹性扩缩策略,由于通过 CPU 的使用率,无法感知到查询请求所需的资源大小,为了保证使用体验,只能通过配置极低的 CPU 阈值,即只要有查询就第一时间大量扩容,这种方式显然会产生大量的不必要扩容。
基于自定义指标,我们使用 loki 本身内置的查询队列指标,根据查询队列,进行精准的扩容,这避免了之前大量的无效扩容,并且根据队列情况,扩容的 Pod 数量也更加的精准。
定时扩缩容,精确控制扩缩行为
由于种种原因,还有一部分应用本身架构较重,对服务扩缩容的动作非常敏感,非预期的扩缩容都有可能对服务可用性造成影响。针对这种场景,长期的理想目标当然是能够推动业务进行治理,但是在相当一段时间内,我们只能通过其他的手段,让这种应用也能享受到 K8s 所带来的扩缩容的便利。因此我们支持了可通过 cron 表达式配置的定时水平扩缩容,由应用的负责人自动配置,在可控的时间点,进行 Pod 的扩缩容。
小结
在标准的以 CPU/ 内存为指标进行 HPA 的基础上,我们通过对流量预测、自定义业务指标、定时等多种 HPA 方式的引入和结合,让绝大部分部署到 K8s 的应用都能够使用 HPA,目前容器化的应用中,85% 以上应用都接入了 HPA,借力 K8s 自动扩缩容所带来的优势,低峰期缩容 Pod 降低成本,高峰期可以扩容更多的 Pod,保障服务的稳定性。
业务挑战 -2,如何实现在线业务节点的无损缩容?
上述的内容,解决了应用 Pod 的弹性伸缩问题,但是随着大量的应用每天都有着大幅度的 Pod 扩缩容,集群本身的资源水位也产生了比较大的落差。之前虽然已经使用了社区的 cluster-autoscaler 进行集群节点扩缩容,但是更多是作为资源不足时的扩容机制,缩容本身比较保守,甚至大流量区域的集群并没有开启缩容。
我们面临的场景是集群中绝大多数的服务都是在线业务,因而无法通过离线任务的调度来削峰填谷。而节点的缩容,首先会对节点上的 Pod 进行驱逐,如果出现比较频繁的节点扩缩容或 Pod 被频繁驱逐,会比较严重的影响服务的可用性。因此,如何能在对业务应用影响最小、甚至无感知的情况下缩容节点,是我们面临的另一个挑战。
解决方案
社区的 cluster-autoscaler 组件,基于节点组的概念,实现了 Pod Pending 事件触发的节点扩容操作,和由节点上的资源 requests 分配比例触发的节点缩容操作。由于 K8s 本身的技术迭代很快,且社区非常活跃,我们还是首选基于社区的方案,做一些自定义的修改或旁路的增强,以便于后续仍能够持续借力社区的发展。于是基于社区的 cluster-autoscaler 设计了我们的节点扩缩容方案。
方案一:调整集群默认调度策略,直接使用针对现有节点组 cluster-autoscaler
K8s 的 Pod 调度器,默认是启用 LeastRequestedPriority 的资源分配策略,即 Pod 优先调度到资源较为空闲的节点上,是一种资源打散的策略,目的是尽可能是 node 节点的资源分配比例平均,避免某一节点负载过高。但同时,它还支持 MostRequestedPriority 的策略,顾名思义,这是和前者相反的一种资源堆叠的调度策略,目的是将相对空闲的节点逐渐空出,以便能够进行回收。
于是最容易想到的一种方案就呼之欲出,将集群的默认的 LeastRequestedPriority 调度策略改为 MostRequestedPriority,这样在 Pod 扩容的过程中,自然就会优先堆叠调度到部分节点,而 Pod 缩容后,再通过 cluster-autoscaler 的节点缩容,将部分负载相对较低的节点上的 Pod 驱逐,由于 MostRequestedPriority 的策略,被驱逐的 Pod 会更可能的堆叠调度到其他的资源水位较高节点上去,这能够减少被二次驱逐的概率,由此实现集群节点的自动扩缩容。
上述的方案,解决了在资源打散的调度策略下,可能的无节点可缩(水位平均,没有节点能够达到缩容的阈值)的问题,也一定程度上能够减小 Pod 可能被多次驱逐的风险。但是实际上仍有一些问题存在,无法满足我们对节点扩缩容的需求。
首先,K8s 缩容时是无法控制缩容的 Pod 选择的,所以缩容时无法做到尽可能的缩容同一批节点上的 Pod,只能通过缩容节点时的 Pod 驱逐重新调度,达到将 Pod 堆叠调度在一部分的节点上,空出待缩容节点的目的。这就使得节点缩容的资源水位阈值,还会是一个比较高的数值,导致缩容节点时,影响到比较多的 Pod,很难做到服务的弱感知甚至无感知。
其次,完全的堆叠调度,也并不是我们期望的结果。为了提升资源使用率,我们本身就存在不小比例的资源超卖,并且我们集群中的服务,基本全部都是在线服务,对稳定性要求高,堆叠调度带来的比较大节点负载差异,极端情况下,很有可能影响节点的稳定性,甚至带来集群雪崩的风险。因此,在未触及到节点扩缩的条件时,我们还是希望在当前的集群中,Pod 能够尽可能的打散调度,分散风险。
经过谨慎的分析,本着保障服务稳定性作为第一优先级的思想,我们还是放弃了这一方案。
方案二:基于弹性节点组的扩缩容方案
基于上面的分析,再次明确下我们对于集群节点扩缩容的要求:
低峰期缩容,意味着线上节点每天都会有很多的扩缩容操作,扩缩容过程中,要尽量减少对服务的影响。
目前集群单台宿主机节点上,可能会有 20 个左右的业务 Pod,在缩容时,要尽可能的缩小影响范围。
高峰期到来时,要能够尽可能快速的扩容节点,不影响业务 Pod 的扩容。
于是,我们设计了如下方案:
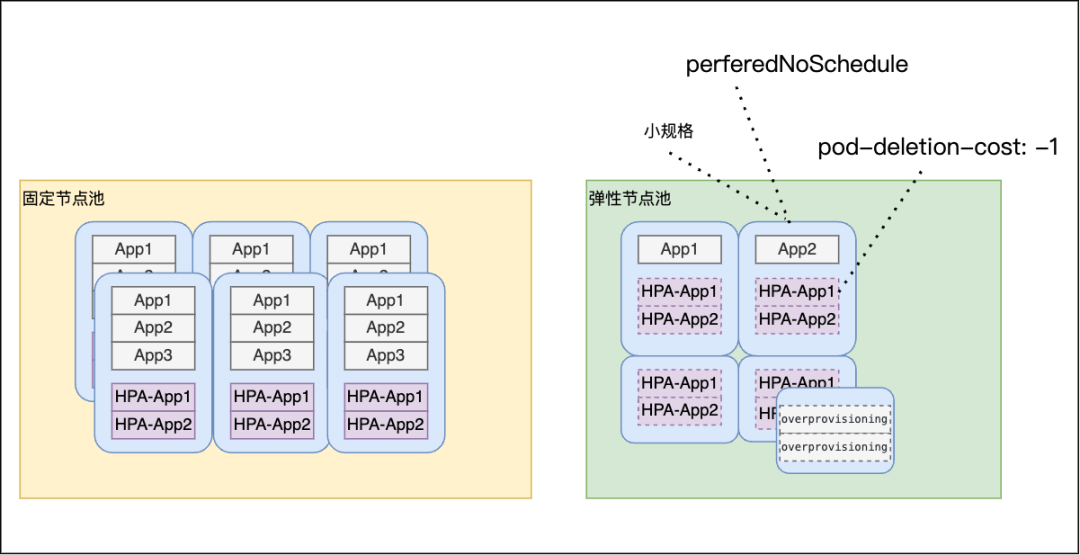
如上图,具体实现上,我们做了以下几个事情:
从原有拆分出部分节点作为弹性节点组,单节点规格减小,缩容时缩小影响范围。
扩容弹性节点组节点时默认添加 perferedNoSchedule 污点(软约束),pod 尽可能先调度满固定节点组。
通过自定义 controller 控制调度到弹性节点组的 Pod 默认添加 pod-deletion-cost 的 annotation,缩容时优先缩容弹性节点组上的 pod。
弹性节点组创建预留 Pod,Pod 优先级为负,在扩容的弹性节点尚未就绪之前,优先抢占,提升节点扩容速度。
下图为高低峰节点扩缩容示意图:
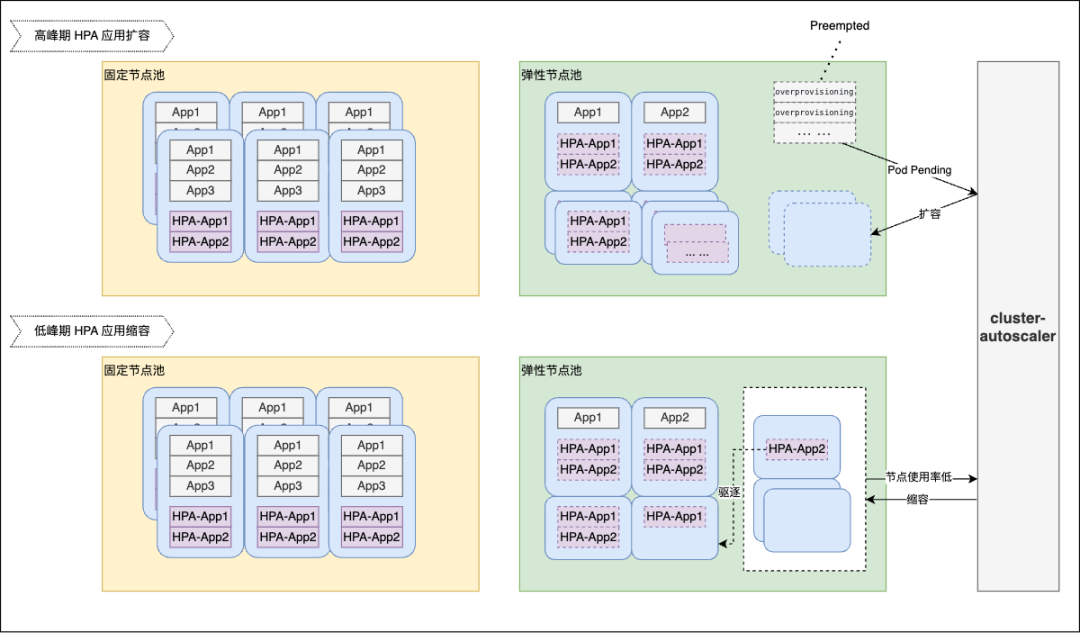
如图所示,高峰期应用 pod 扩容,固定节点组的资源不够,HPA 扩出的 pod 调度到弹性节点组。弹性节点组本身会预留 overprovisioning 的 pod,当节点组资源不足时,HPA 扩容出的业务 pod 会抢占 overprovisioning pod 的资源,优先部署在已有节点,无需等待节点扩容,另外 overprovisioning pod 被抢占后产生 Pending 事件,会触发 cluster-autoscaler 扩容新的节点,预留部分资源。
低峰期应用 pod 缩容时,弹性节点组上的 pod 会通过自定义控制器自动加上 pod-deletion-cost: -1 的注解,相比固定节点组的 pod,会更优先被缩容,因此弹性节点组上的节点会出现资源空余,当节点资源水位低于预设的阈值,会触发 cluster-autoscaler 缩容,将空闲的节点回收。
由于弹性节点组的节点打上了 perferedNoSchedule 的污点,调度器会尽可能不调度 pod 到该节点,因此正常时间段业务 pod 具有较小的概率调度到弹性节点,仅当高峰期大量 pod 自动扩容导致固定节点组资源不足时,pod 才会调度到弹性节点上,同时弹性节点组的节点规格设计上相对固定节点组更小,单节点上运行的 pod 数量更少,且由于 pod-deletion-cost 的作用,使得在低峰期缩容时,弹性节点会直接出现大量空闲设置空置的情况,这极大的减小了节点缩容对服务影响。
小结
通过节点组的拆分和自定义控制器来控制 HPA 缩容时的 Pod 选择,我们成功的在核心在线业务的场景下,实现了每天低峰期大量的闲置节点资源回收,并且同时有效保障应用稳定性,上线以来未因缩容原因收到应用方的反馈。以我们美国区集群的一个核心业务节点组为例,每天低峰期的节点数量基本可以缩到 5 台以内,高峰期最大节点数可以扩到 30 台,每天节点组 CPU 总核数的上下波动在 10% 以上,由此节约下的资源成本非常可观。
调度
业务挑战 -3,如何平衡节点间的负载差异?
k8s 调度器本身感知到的是节点的 requests 分配比例,而不是实际的资源负载,因此,如果 reqeusts 本身不能准确反映出 Pod 实际的资源使用情况的话,在集群资源水位比较高的情况下,就可能出现节点之间的实际资源负载差距较大的现象,甚至导致单节点的负载压力过高,影响到节点上的 Pod 服务。
解决方案
调度策略
一个最直观的方法,就是让调度器在调度时,能够感知到节点的实际资源使用率并以此为参考进行 Pod 的调度。
社区的 scheduler-plugins 项目,基于 kubernetes 的 scheduling framework,构造了一个可以替换 kubernetes 默认的调度器,并内置了一些可以解决不同部署场景的调度插件,其中,刚好有一个支持实际负载感知的调度插件 Trimaran。
基于 Trimaran,可以做到根据节点的实时负载情况,对 Pod 调度的节点进行打分,做到尽可能的平衡节点间的实际负载。根据我们实际的业务场景,即 CPU 波动的情况大大高于内存,我们对 Trimaran 的调度插件做了些优化,调整了 CPU 和内存的负载情况对节点打分结果的所占权重并可通过配置调整。并且给 Trimaran 插件以较高的打分策略权重,这样一来,Pod 调度时就会充分考虑到节点当前的实际负载。
同时,我们还通过拉取应用 Pod 的历史资源使用情况,对不同应用的资源使用特征进行分析,将一些特征比较明显的应用进行打标,比如 CPU 型、内存型等,并通过 kubernetes 的 admission-webhook,动态的将标签应用到 Pod 和 Pod 的反亲和调度配置上,这样,具有同样标签的应用 Pod 能够实现打散调度,避免相同类型的 Pod 过度的聚集在某一节点上,这也起到了平衡节点间的资源负载的作用。
重调度策略
另一方面,在调度后,随着 Pod 的高低峰和业务变化,可能原本负载不高的节点,随着部分 Pod 本身的流量上涨,负载会逐渐升高,仍会存在节点的负载过高的风险,由于这并非是由 Pod 调度引起的,调度器在这时也无法发挥作用了。于是我们又引入了 deschduler 对 Pod 进行重调度,即发现有风险的节点或 Pod,并通过驱逐其上的 Pod 进行重新调度,减少各类可能出现的风险。
descheduler 可以以 cronjob 的方式在集群中运行,支持了很多种驱逐策略,比如基于节点 reuqests 分配比例的策略、基于 Pod 拓扑约束分布的策略和基于 Pod 的亲和性的策略等等,只要 Pod 目前的调度情况符合需要驱逐的规则,descheduler 就会在不违反 PDB 的前提下,驱逐 Pod 重新调度,从而使 Pod 的分布或运行状况,能够符合我们的预期。
基于 descheduler,我们自定义了符合我们需求的驱逐策略,根据节点的实际负载情况,当节点负载高于阈值时,选取节点上的 Pod 进行驱逐。同时针对部分实际负载持续较低,且 requests 资源分配已经高于 90% 的情况,同样选择驱逐部分 Pod,以空余出部分可调度空间,让较活跃的 Pod 调度上来,平衡节点间负载。
整体方案流程如下图所示:
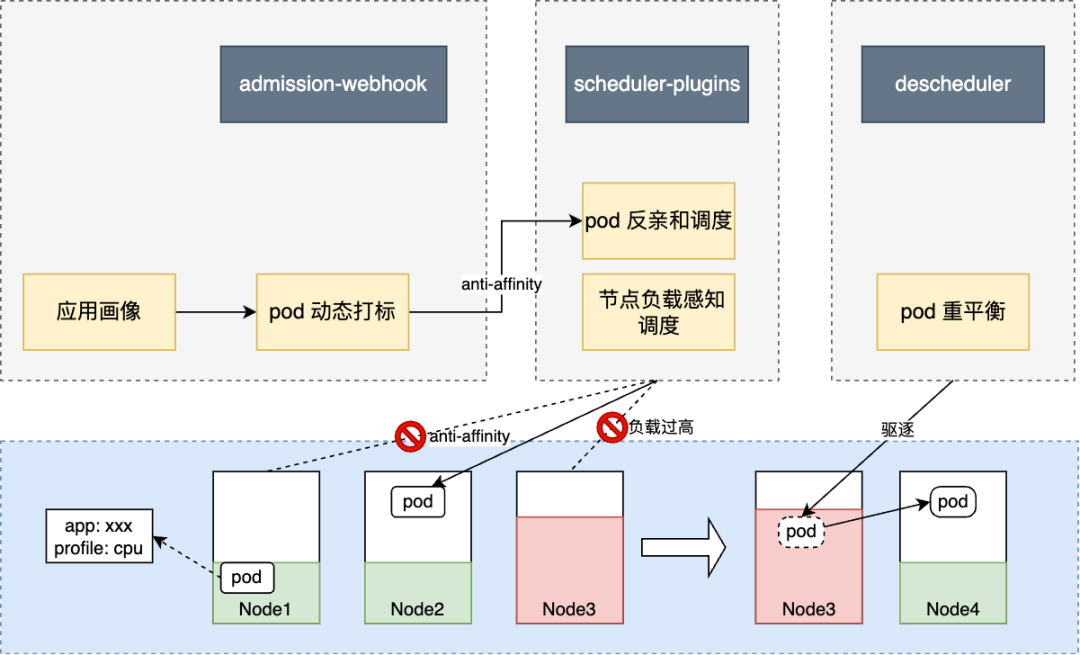
小结
节点负载感知调度加上动态重调度策略,使得集群中的节点不均衡的情况得到了很到的改善。从之前动辄 50% 以上的 CPU 使用率差距,降低到基本维持在 30% 以内,大流量区域的核心应用节点组,能够维持在 20% 左右,集群的稳定性得到了较大的提升。
业务挑战 -4,应用多 AZ 部署场景下的弹性伸缩调度
为了服务高可用,目前公司内的服务基本在云上都是跨多可用区部署,然而很多云厂商都有跨可用区的内网流量费,因此内部微服务调度都做了同可用区流量调用的改造,这能够有效的节省下流量成本,但对服务 Pod 的调度,又构成了一些挑战。
因为每个应用的 Pod,在集群都是通过一个 Deployment 进行管理,由于同可用区调用的存在,使得 Deployment 原本完全无状态的 Pod 带上了一些属性,对 Pod 的调度有了一定要求。
要保证所有服务的 Pod 可用区分布均衡。否则上下游服务的 Pod,可能出现可用区间数量不对等的情况,非常影响服务稳定性。
可用区间的流量并不是绝对均衡的,因此,在考虑到 HPA 的场景下,Pod 扩容时,需要能够进行可用区的选择,扩容到最需要的可用区的节点上。否则,非但不能分担高负载可用区的流量,并且因为扩容的 Pod 拉低的 HPA 的指标,服务不会继续触发扩容,很有可能造成部分可用区服务的受损。
在缩容后仍需要能够保持 Pod 的可用区分布均衡。同样是在 HPA 场景下,在缩容 Pod 时,K8s 不会考虑 Pod 的可用区分布情况,因此,在当前扩缩容比较频繁的情况下,会有几率出现因缩容导致的可用区分布不均的情况。
解决方案
可用区拓扑分布约束
Pod 可用区的均衡分布,可通过 Pod 的 topologySpreadConstraints 即拓扑分布约束来实现,我们将 topologySpreadConstraints[].topologyKey 配置成节点可用区的标签(如:topology.kubernetes.io/zone)并配置 topologySpreadConstraints[].whenUnsatisfiable 为 DoNotSchedule,这样在 Pod 调度时,就会强制的保证同一应用的 Pod,在不同可用区的节点均衡分布,当某一区域无法调度时,会触发 cluster-autoscaler 扩容该可用区节点组。通过 K8s 内置的拓扑分布约束,解决了上述的第一个问题。
调度策略
仍然是基于 scheduler-plugins,我们新增了一个自定义的调度插件,这个插件作用在调度过程中的 PreScore 和 Score 两个阶段,通过 prometheus 的数据,获取到待调度 Pod 的所属应用的不同可用区的负载情况,若负载差异较大,则在调度该 Pod 时,给负载最高的可用区的节点以最高的打分结果。为了不影响调度器本身的调度效率,我们在调度与 prometheus 间加了一层定时更新的缓存,调度中只会从缓存中获取数据。如果数据有异常,那么该策略会自动降级,所有节点返回相同分数。我们给这个调度插件的打分权重,高于其他所有的打分插件,保证了这个策略在调度过程中,能起到主导的作用。这解决了上述第二个问题。
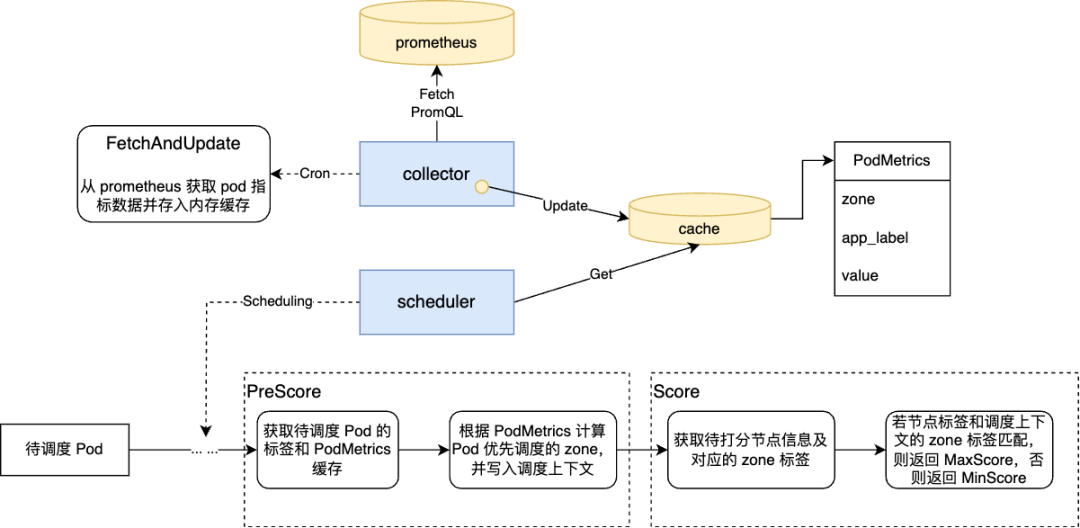
重调度策略
因为我们本身已经使用了 descheduler,因此我们又基于 descheudler 的 RemovePodsViolatingTopologySpreadConstraint 的驱逐策略,通过事后补偿的方式,解决上述的第三个问题。
小结
在应用跨多 AZ 部署,且应用同可用区调用的场景下,我们通过自定义调度器和重调度对 Pod 调度时和调度后的多个阶段的干预,实现了在自动扩缩容的动态场景下,仍能保证 Pod 可用区分布的均衡,及扩容时对应用 Pod 可用区负载的感知,降低了应用弹性扩缩容的风险,进一步提升了应用的稳定性。
成果
上述的解决方案实施后,目前集群的整体状况,以美国区的一个核心在线业务节点组为例,得益于大部分应用都已经接入了水平弹性扩缩容,并且落地了我们的在线业务节点缩容方案,节点组资源水位(装箱率)基本维持在 95% 左右,实际 CPU 使用率日均在 60% 以上,每天弹性伸缩的 CPU 核数占节点组总核数的 15%。从集群维度,美国区集群总体节点弹性伸缩的 CPU 核数占集群总核数的 25% 以上。以上的数据,都是建立在集群中部署的服务,几乎全是对稳定性要求非常高的在线业务的基础之上。
总结和展望
以上的能力,都是基于我们的 kubegrus 云原生平台构建的。后续,我们会基于 kubegrus 平台,持续优化已有的功能,降低使用门槛。另一方面,我们将围绕以下几个方向,持续进行技术优化和升级,提供更完善的云原生解决方案。
持续优化集群的故障恢复和故障迁移方案,不断提升系统稳定性和容灾能力。
更加灵活和细粒度的精细化调度能力。
云原生架构的不断升级,让更多业务场景能够迁移到 K8s 和云原生的架构。
作者简介
毛琦,任职于涂鸦智能,云原生开发工程师,关注云原生领域相关技术。
相关项目地址:
1. keda:https://github.com/kedacore/keda
2. crane:https://github.com/gocrane/crane
3. cluster-autoscaler:https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler
4. scheduler-plugins:https://github.com/kubernetes-sigs/scheduler-plugins
5. deschduler:https://github.com/kubernetes-sigs/descheduler




