
在实证领域,科学的严谨性是从假设开始塑造的。
业界对机器学习研究的科学严谨性的质疑声越来越多了。
在 2017 年 NIPS 会议上的一场演讲中,当时就职于谷歌 AI 的 Ali Rahimi 和 Ben Recht 认为 ML 已经成为了一种炼金术,也就是说从业者使用的方法在实践中表现很好,但在理论层面上对这些方法的理解却相当欠缺。类似地,Keras 深度学习库的作者 Francois Chollet 认为当今的 ML 从业者都有“货物崇拜”的思想,人们依赖的都是“民间传说和魔法咒语”。
炼金术、货物崇拜、魔法咒语。对于一个发展如此迅速、在现实世界应用越来越广泛的领域来说,这些都是值得关注的批判意见。而且正是这种广泛应用的局面让 Rahimi 和 Recht 感到忧心忡忡:
如果你构建的是照片共享服务,那么就算用的是炼金术也无所谓。但我们现在正在构建的系统会管理医疗保健和政见发表等事务。我希望我们世界的系统应该建立在严格、可靠、可验证的知识基础上,而不是用什么炼金术来充数。
机器学习是一个实证领域:我们根本没有什么理论可以解释为什么某些方法行之有效,而其他方法却行不通,我们甚至不清楚这样的理论是否会存在。但缺乏理论这一事实本身实际上并不是主要问题。即使在实证研究领域,我们也可以用科学严谨的方式取得进展。
我认为科学和炼金术之间的关键区别始于从业者分配给科学假设的角色。
先做假设
ML 从业者需要面对庞大的复杂性,从数据集采样和清理到特征工程,再到模型选择和超参数调整,都涉及非常复杂的过程。对这些部分一点点做调整,然后(通常在测试集上)看看哪种参数组合的效果最好,已成为行业中的常用手段。
但仅靠微调是不足以形成一门科学理论的。与炼金术相比,科学研究的本质区别在于科学假设的作用:科学家首先提出一个假设,然后设计一个实验来检验该假设。然后假设要么被拒绝,要么被接受。无论是哪种结果,我们都能获得新的知识。科学方法是不会预知实验结果的。
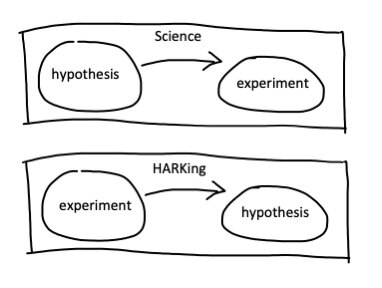
相比之下,微调过程不是由假设驱动,而更多是由“直觉”驱动的。如果这样做的目标只是探索一种现象,那也无所谓。但如果这种微调被 HARKing 伪装成科学就很危险了。所谓 HARKing,就是在已知结果后再去提出适合这一结果的假设。
HARKing 很容易误导人,因为它不仅会愚弄研究人员,而且会愚弄整个社区。在最坏的情况下,研究人员可能会对一种算法的不同变体进行大量实验,选出达到预期结果的版本。在实践中,这意味着它击败了最新的最先进基准,然后研究人员使用 HARKing 来证明这个选择是合理的。人们一般称之为 SOTA-hacking。
当然,运行的随机实验越多,它就越有可能仅凭偶然发挥就击败任何给定的基准:这也被称为查看别处效应。更糟糕的是,SOTA-hacking 占用了很多本可用于实际创新的资源。Facebook 工程师 Mark Saroufim 在《机器学习:大停滞》中写道:
在追求一流结果的过程中,我们奖励并鼓励了作为创新者的渐进式研究人员,增加了他们的预算,让他们可以领导更多下属员工或研究生,并行进行更多渐进式研究。

SOTA-hacking
在运行实验之前就提出科学假设,是预防 HARKing 和 SOTA-hacking 的最佳保护机制。在论文“深度学习的HARK一侧”中,作者数据科学家 Oguzhan Gencoglu 及其同事甚至提倡对 ML 研究论文采用“隐藏结果(result-blind)”的提交流程:让科学家先提交他们的科学假设以及实验设计,当假设和设计被接受后他们可以继续进行实验,条件是他们必须公布结果,无论结果是证实还是排除了假设。这是一个极端、不切实际且可能不现实的解决方案,但它肯定会消除 SOTA-hacking 的风险。
ML 可以从物理学中学到什么
随着 ML 研究的发展,我相信它可以从物理学中借鉴很多有益思想。物理学的基本思想之一是先考虑一个更容易解决的小玩具问题,其结果可以在更大、更复杂的问题背景下提供有价值的见解。
这并不是说这些物理风格的实验是不该做的,但做的实验并不会很多。在 NLP 的背景下,值得注意的例子是揭示著名的 BERT 语言模型对转喻、多义词或简单的输入序列顺序的敏感性的几项研究。例如,后一项研究发现,当 BERT 在 GLUE 基准任务上训练时,它对词序相对稳健。这表明大部分信号不是来自上下文,而是来自其他线索,例如关键字。
除了玩具问题,另一种强大的实证方法是消融研究。具体来说就是有意在每一次实验中忽略解决方案的一个组成部分,以将关键组成部分与没有实际影响的“花里胡哨”部分区分开来。在 NLP 的背景下,一个很好的例子是 2017 年的著名论文“你需要的只有注意力而已”,它表明语言模型中的递归在存在注意力机制的情况下是多余的。
另一个很好的例子是 2017 年的论文“神经网络架构中文本预处理的作用研究”,该论文表明,除了小写外,常见的文本预处理技术(文本清理、词干提取、词形还原)在下游 ML 中没有提供任何可衡量的模型性能改进。
从炼金术到科学
今天的很多 ML 实践给人的感觉就像炼金术一样。但是,正如我在上述例子中所提到的,即使在不存在理论的情况下,也可以通过某些实验来更深入地了解 ML 的内部运作机制,为这一领域提供更严谨的科学立足点。下面是我对 ML 从业者提出的 3 条建议:
在做任何实验之前先明确你的假设。抵制 HARKing 和 SOTA-hacking 的诱惑。
要有创造性:先考虑特定的玩具问题,这些问题可以用来确认或排除社区(隐含或明确)做出的假设。
使用消融研究来确定 ML 解决方案的关键部分,并消除方案中“花里胡哨”的部分。
最后,我希望随着 ML 研究的发展,业界的关注点将从目前追求突破性能基准的风潮转向更基础的原理探索领域。毕竟,科学是对知识,而非胜利的追求。我同意 Rahimi 和 Recht 的观点,他们写道:
想想你在过去一年中就为了搞定一个数据集进行了多少次实验,或者做那么多实验只是为了看看一项技术是否会给你带来提升。现在你应该好好思考一下你的实验,设法对实验观察到的令人费解的现象给出合理的解释。我们以前的重心都放在了突破纪录上,以后应该多关注理论和机制了。
原文链接:
https://towardsdatascience.com/machine-learning-science-or-alchemy-655bea25b227




