
编者按
数据作为第五大生产要素,已逐渐成为政府和企业决策的重要手段与依据。面对数据多样化、数据需求个性化、数据应用智能化的需求,以及在 2B 和 2G 行业中数据质量参差不齐、数据应用难以发挥价值、数据资产难以沉淀等问题,如何做好数据治理工作、提升数据治理能力成为了政府和企业数字化转型的重中之重。
百分点大数据技术团队基于多年的数据治理项目经验,总结了一套做好数据治理工作及提升数据治理能力的实施方法论。
近年来,推动数据治理体系建设一直是业界探索的热点,另外,《中共中央、国务院关于构建更加完善的要素市场化配置体制机制的意见》将数据作为第五大生产要素提出意义非同一般。但与劳动力等生产要素不同的是,数据是无形的,且数据孤岛林立,要想发挥数据价值,提升数据治理能力是必要举措。
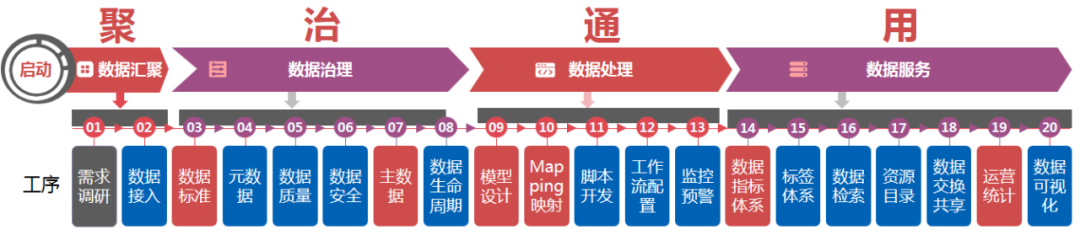
百分点结合多年政府各个部门及各类企业数据治理项目经验,提出数据治理项目开展过程中数据治理平台应具备 4 大能力:聚、治、通、用,以及项目实施总体指导思想:PDCA。
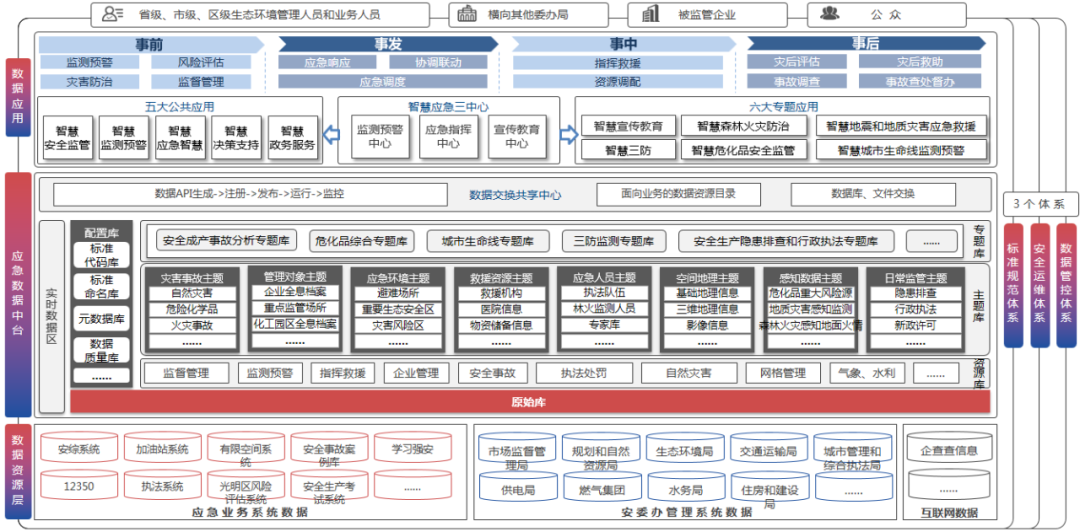
四大能力建设:
聚: 数据汇聚能力,面对数据来源各异,数据类型纷繁多样,数据时效要求不一等各类情况,数据治理首先能把各类数据接入到平台中,“进的来”是第一步。
治: 狭义数据治理能力,包括数据标准、数据质量、元数据、数据安全、数据生命周期、主数据。核心是保证数据标准的统一、借助元数据掌握数据资产分布情况及影响分析和血缘关系、数据质量地持续提升、数据资产的安全可靠、数据资产的淘汰销毁机制以及核心主数据的统一及使用。
通: 数据拉通整合能力,原始业务数据分散在各业务系统中,数据组织是以满足业务流转为前提。后续数据需求是根据实际业务对象开展而非各业务系统,所以需要根据业务实体重新组织数据。比如政府单位针对人的综合分析通常会涉及:财产、教育程度、五险一金、缴税、家庭成员等,需要以身份证号拉通房管局、交通局、教育局、人社局、税务局、卫健委等多个委办局数据。数据拉通整合能力是后续满足多样化需求分析的基础,是数据资产积累沉淀的根基,也是平台建设的另一个重点。
用: 数据服务能力,数据资产只有真正赋能于前端业务才能发挥实际效用,所以如何让业务部门快速找到并便利的使用所需数据资产是数据治理平台的另一项核心能力。
P:plan,标准、规划、流程制定;D:do,产品工具辅助落地;C:check,业务技术双重检查保证;A:action,持续优化提升数据质量及服务。
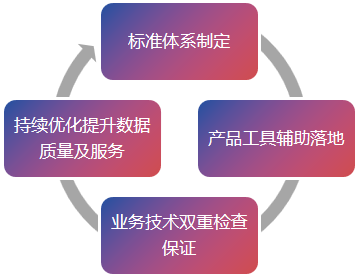
结合数据治理项目实际落地实施过程以四大能力构建、PDCA 实施指导思想提出了“PAI”实施方法论,即流程化(process-oriented)、自动化(automation)、智能化(intelligence)三化论,以逐步递进方式不断提升数据治理能力,为政府和企业后续的数据赋能业务及数据催生业务创新打下坚实基础。
流程化将数据治理项目执行过程进行流程化梳理,同时规范流程节点中的标准输入输出,并将标准输入输出模板化。另外对各流程节点的重点注意事项进行提示。
自动化针对流程化之后的相关节点及标准输入输出进行自动化开发,减轻人力负担,让大家将精力放在业务层面及新技术拓展上,避免重复人力工作。如自动化数据接入及自动化脚本开发等。
智能化针对新项目或是新领域结合历史项目经验及沉淀给出推荐内容,比如模型创建、数据质量稽核规则等。
一、数据治理流程化
因数据治理类项目通常采用瀑布式开发模式,核心流程包含:需求、设计、开发、测试、上线等阶段,流程化是将交付流程步骤进行详细分解并对项目组及客户工作内容进行提炼及规范,明确每个流程的标准输入、输出内容。流程节点、节点产出物及数据治理平台四大能力对应关系如下所示:
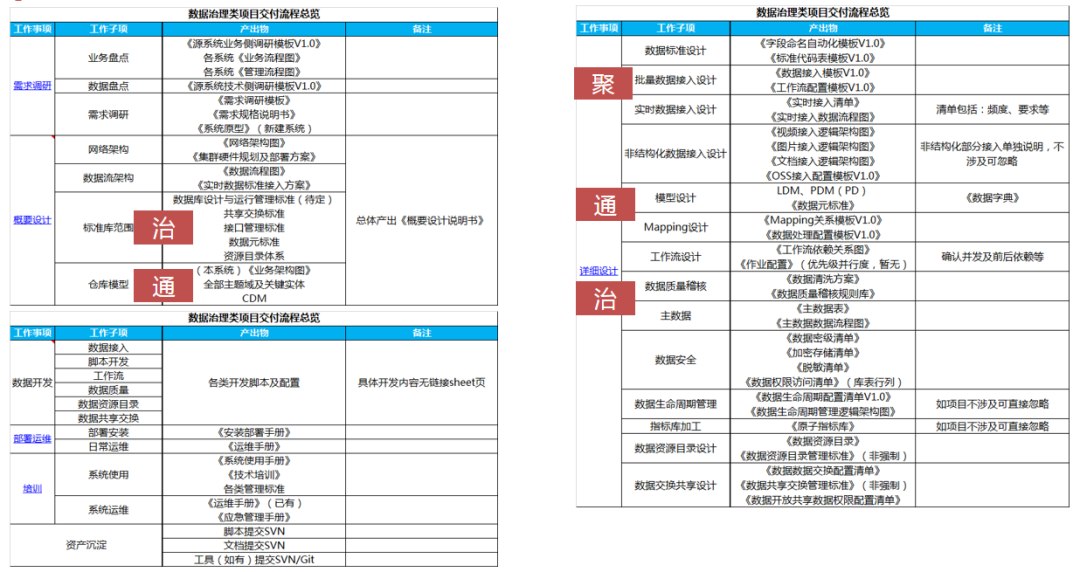
其中因需求、概要设计和详细设计为执行过程中的核心流程节点,将针对此三部分进行详细讲解。
1. 需求调研
1.1 需求调研流程
数据类项目总体调研流程如下:
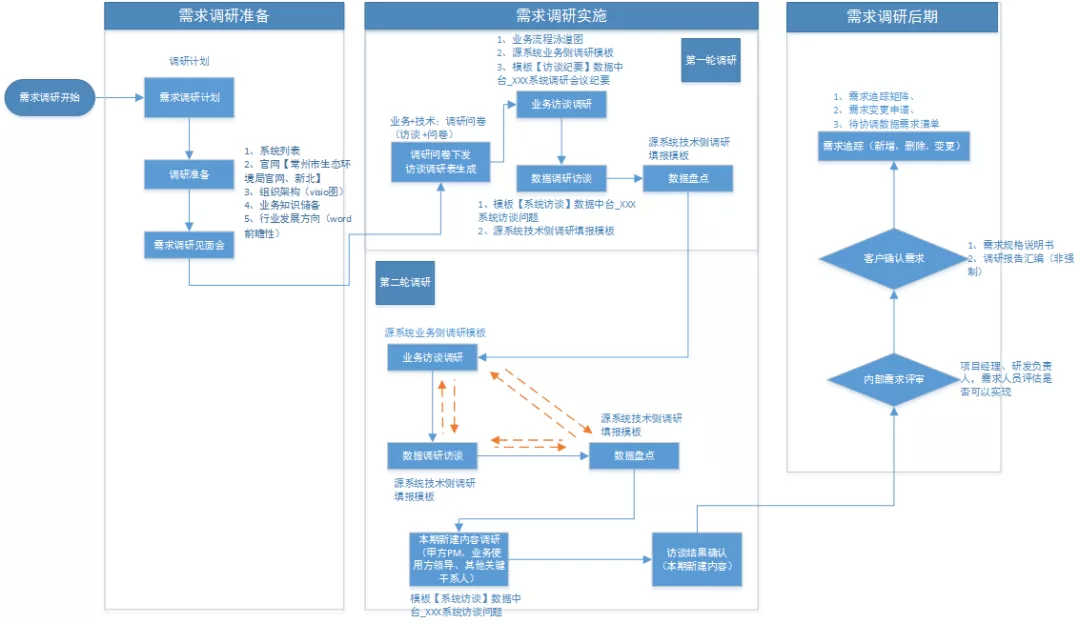
数据调研是整个项目的基础,既要详细掌握现有业务现状及数据情况又要准确获取客户需求,明确项目建设目标。如上图所示总体分成三个大的时间节点:包括需求调研准备、需求调研实施及需求调研后期的梳理确认。
需求调研准备包括:调研计划确定、调研前准备,具备条件的尽量开一次调研需求见面会(项目启动会介绍过的可以不需要再组织)。其中调研前准备需针对客户的组织架构及业务情况进行充分的了解,以便在后续的调研实施阶段有的放矢,调研内容更为详实,客户需求把控更为准确。
调研实施阶段一般组织两轮调研,第一论主要是了解业务运转现状、对接业务数据以及客户需求。第二轮针对具体的业务和数据的细节问题进行确认,及分析后的客户需求与客户确认。对于部分系统的细节问题以线下方式对接,不再做第三轮整体调研。
需求调研后期主要是针对客户需求及客户业务及数据现状进行内外部评审并确认签字,以《需求规格说明书》形式明确本期项目建设目录。
1.2 需求调研工作事项
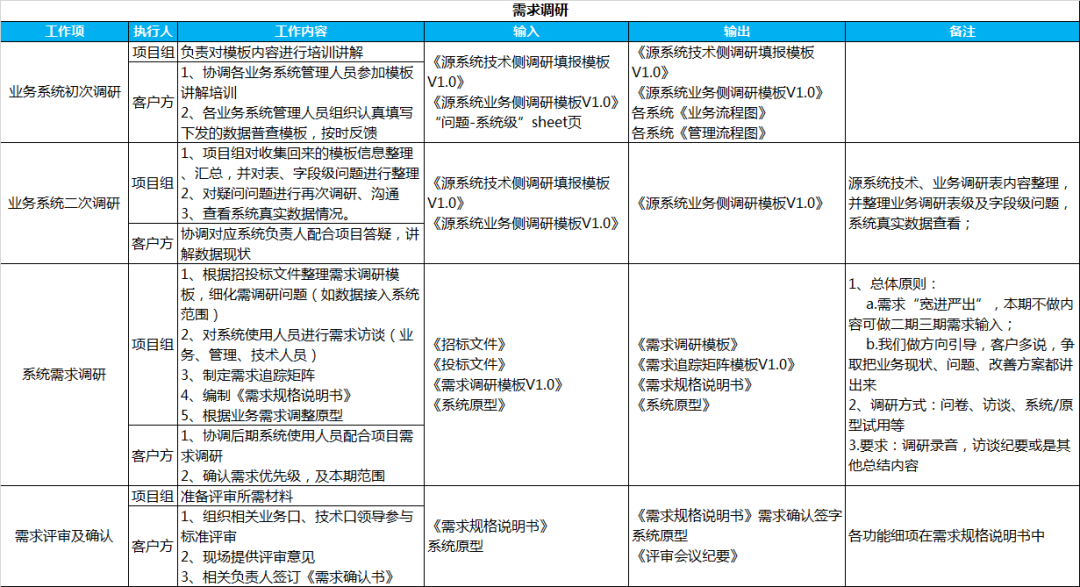
上表描述了需求调研过程关键节点的客户方及项目组工作内容内容及输入输出,并说明了需求调研阶段的总体原则、调研方式及相关要求。
1.3 需求调研注意事项
(1)需求收集
关键干系人需求
真正用户是谁及其需求
需求获取前置问题:客户管什么,重点关注什么,目前如何管理,欠缺什么,重复劳动有哪些?
(2)需求验证
3W 验证,谁来用,什么场景下用,解决哪些问题?
原型草图
(3)需求管理
核心需求(需求需融入业务流程并发挥实际效用)
识别是否行业共性(有余力则做没有则算,项目管理角度不需要,行业角度需要)
(4)需求确认
形成文字版需求规格说明书
务必签字确认(后续可以更改,大变更需记录)
2. 概要设计
数据治理项目概要设计主要涵盖网络架构、数据流架构、标准库建设、数据仓库建设四部分内容。总体目标是明确数据如何进出数据治理平台(明确网络情况)、数据在平台内部如何组织及流动(数据流架构及数据仓库模型)以及数据在平台内部应遵循哪些标准及规范(标准库)。针对每部分具体工作事项及输入、输出如下所示:
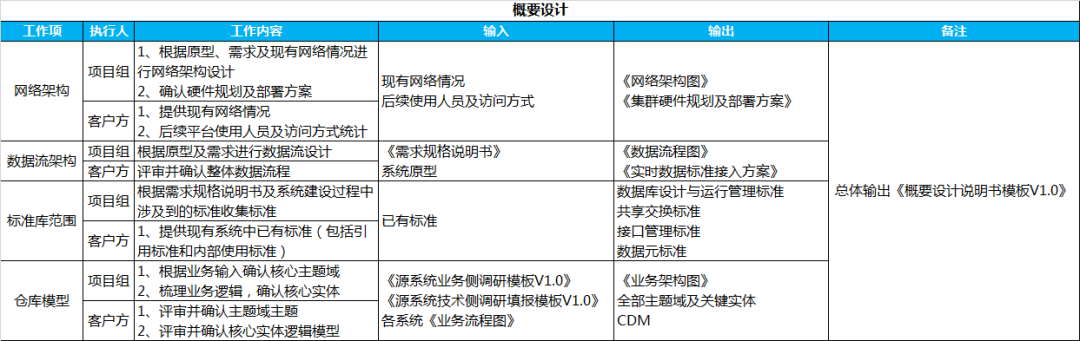
2.1 网络架构示意图
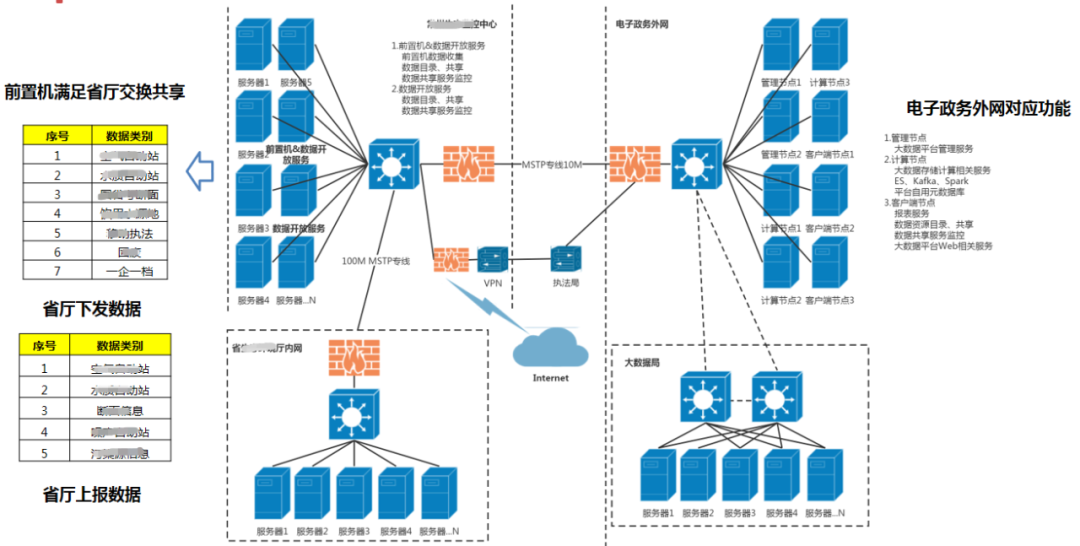
网络架构要明确硬件部署方案、待接入系统网络情况及后续使用人群及访问系统方式,以便满足数据接入及数据服务需求。
2.2 数据流示意图
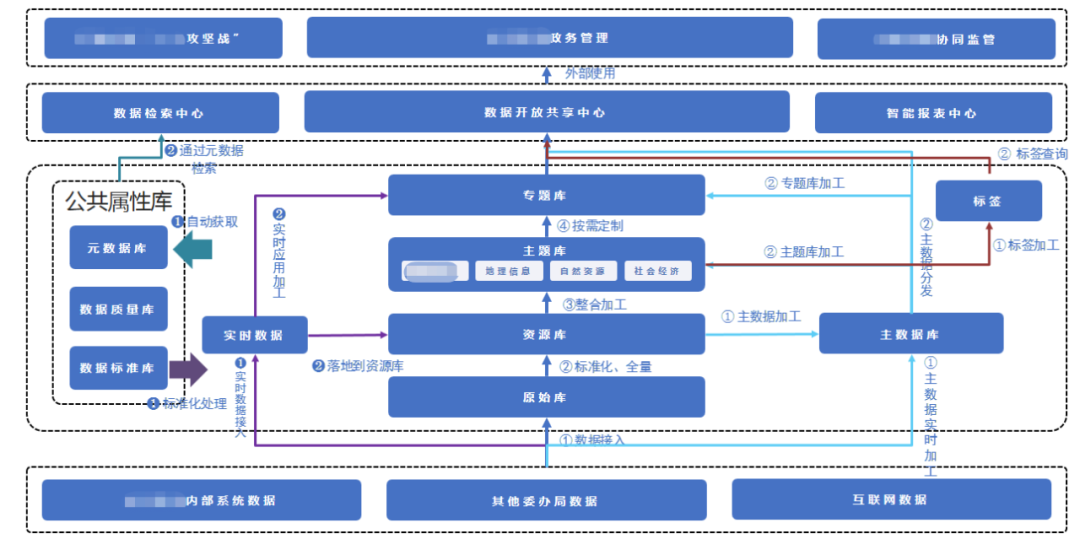
数据流架构要明确各类数据的处理方式及流向,以便确认后续数据加工及存储方式。
2.3 数据标准内容示意图
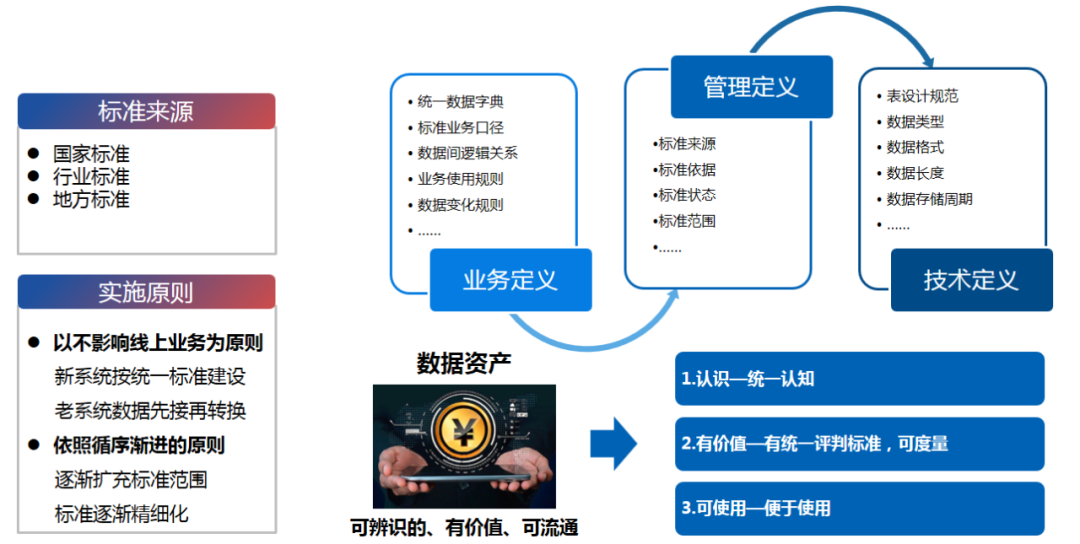
标准库建设要明确平台所遵循的各类标准及规范,以保证平台建设过程的统一规范,为后续业务赋能打下坚实基础。
2.4 数据仓库主题域及核心实体示意图
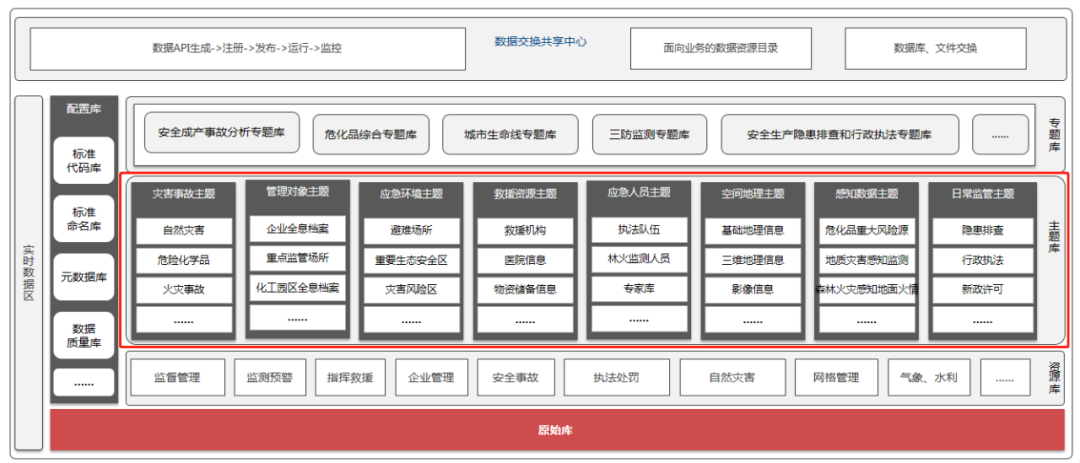
数据仓库建设要明确主题域及关键实体,明确后续数据拉通整合的实体对象,以更好地支撑繁杂多变的数据需求。
3. 详细设计
详细设计针对项目实际落地的工作模块分别进行设计,明确每部分实现的设计,具体模块、工作内容、输入、输出如下所示:
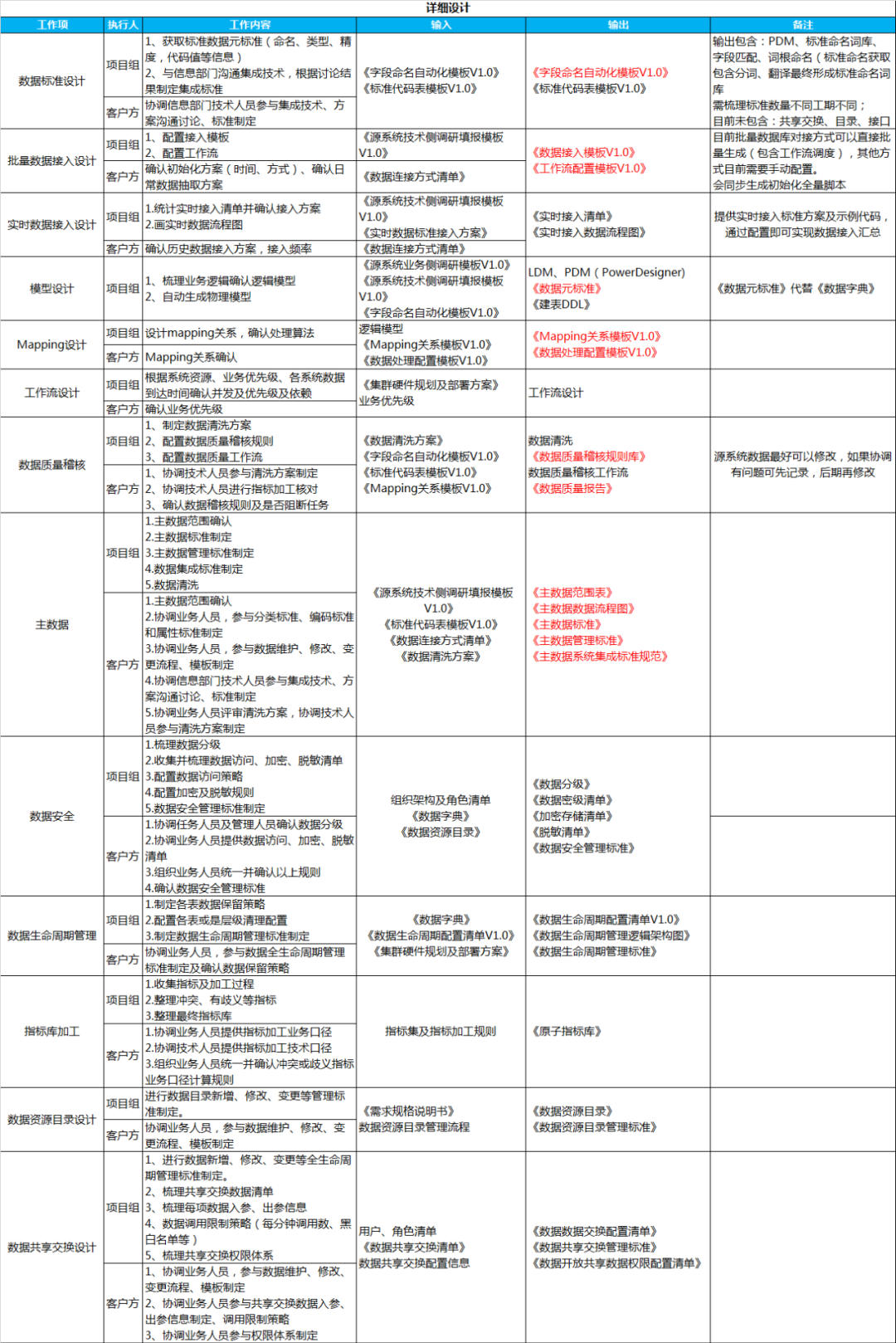
二、数据治理自动化
在将数据治理项目流程化以后整个工作内容及具体工作产出已经比较明确了,但是会发现流程中会涉及到大量的开发工作,同时发现很多工作具有较高的重复性或相似性,开发使用的流程及技术都是一样的只是配置不同,因此针对流程化以后各节点的自动化开发应运而生。通过配置任务的个性化部分,然后统一生成对应的开发任务或脚本即可完成开发。
自动化处理一般有两种实现路径,其一是采购成熟数据治理软件,其二是自研开发相应工具。其中数据治理过程中可实现自动化处理的流程节点如“工序”标蓝色部分:
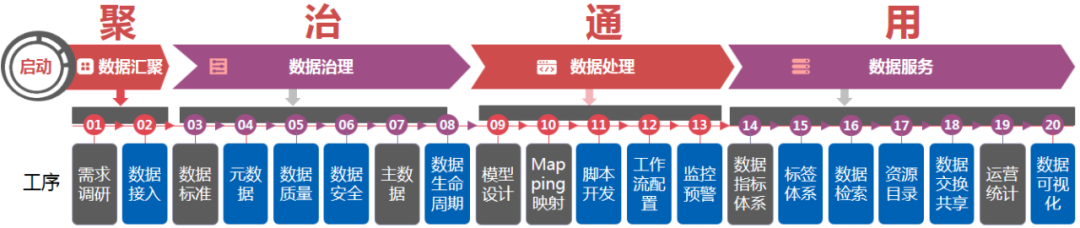
注:对于需求调研、模型设计等流程节点因为涉及到线下的访谈、业务的理解更多的是与人的沟通交流,进而获取相应的业务知识及需求,并非单纯的计算机语言同时“因人而异”的情况也比较常见,所以此部分相关工作暂时还以人工为主。
因数据接入、脚本开发及数据质量稽核在日常工作中占用时间较长,下面将详细讲解此三部分内容。
1. 批量数据接入
数据接入是所有数据治理平台的第一步,批量数据接入占数据接入工作量的 70-90%之间。自动化处理即将任务个性化部分进行抽象化形成配置项,通过配置任务的抽象化配置项,进而生成对应的任务。批量数据接入抽象以后的配置项如下:
源系统:源系统数据库类型
源库名:源系统数据库库名称(数据库的链接方式在其他地方统一管理)
源表名:源系统数据库库表名称
目标系统:目标数据库类型
目标库:目标数据库库名称
目标表:目标数据库库表名
增/全量:1 表示全量接,0 表示增量接
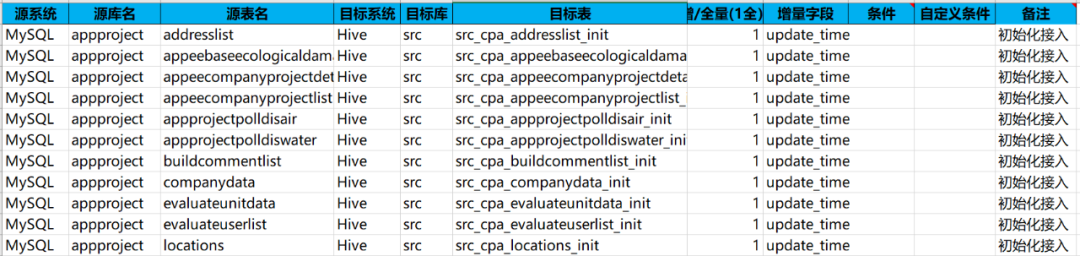
示例配置如上,不管使用 sqoop、datax 等方式都可以批量生成对应命令或配置文件,实现批量生成接入作业,实现自动化数据接入工作,数据接入效率提升 75%以上,后续只需验证数据接入正确性即可。
2. 脚本开发
资源库、主题库的加工脚本占整体开发工作工作的 50%-80%,同时经过对此部分数据加工方式进行特定分析后,数据常用的处理方式如下一般有以下几种类型:
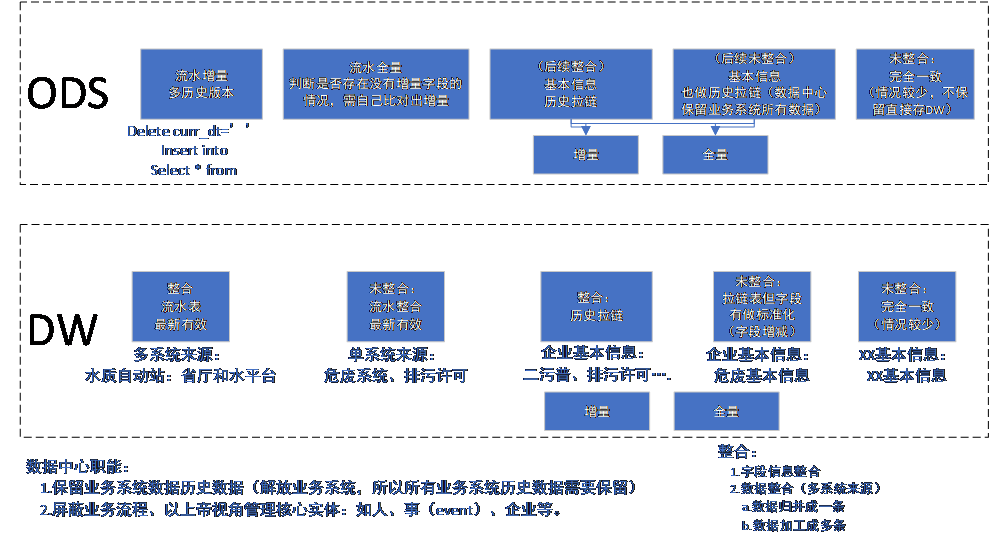
将以上加工方式进行总结后可沉淀出以下几种数据处理方式:
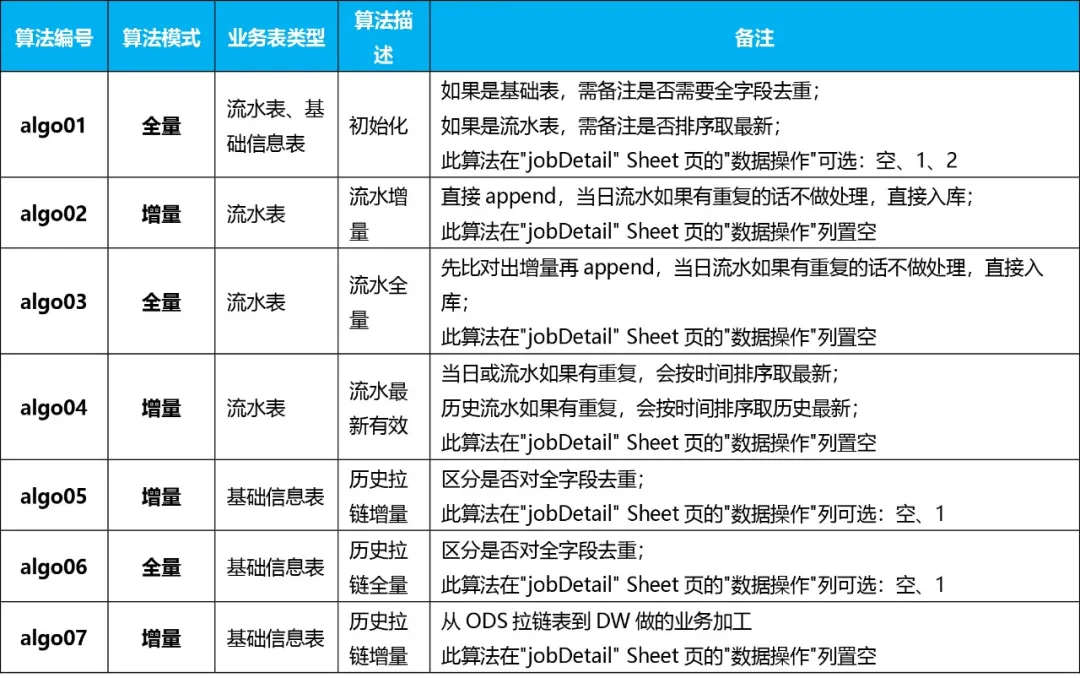
结合 Mapping 文档选定以上数据处理方式的一种即可自动生成资源库或主题库对应脚本,开发效率得到大幅度提升,整体效率提升 60%以上(模型及 Mapping 设计尚需人工处理)。
3. DQC
数据质量是 PDCA 实施总体指导思想的关键一步,是发现数据问题以及检查数据标准规范落地的必须环节。针对具体的规则都可以通过产品和自助开发来实现,只需进行相应配置即可实现自动化检查,具体检查事项如下:
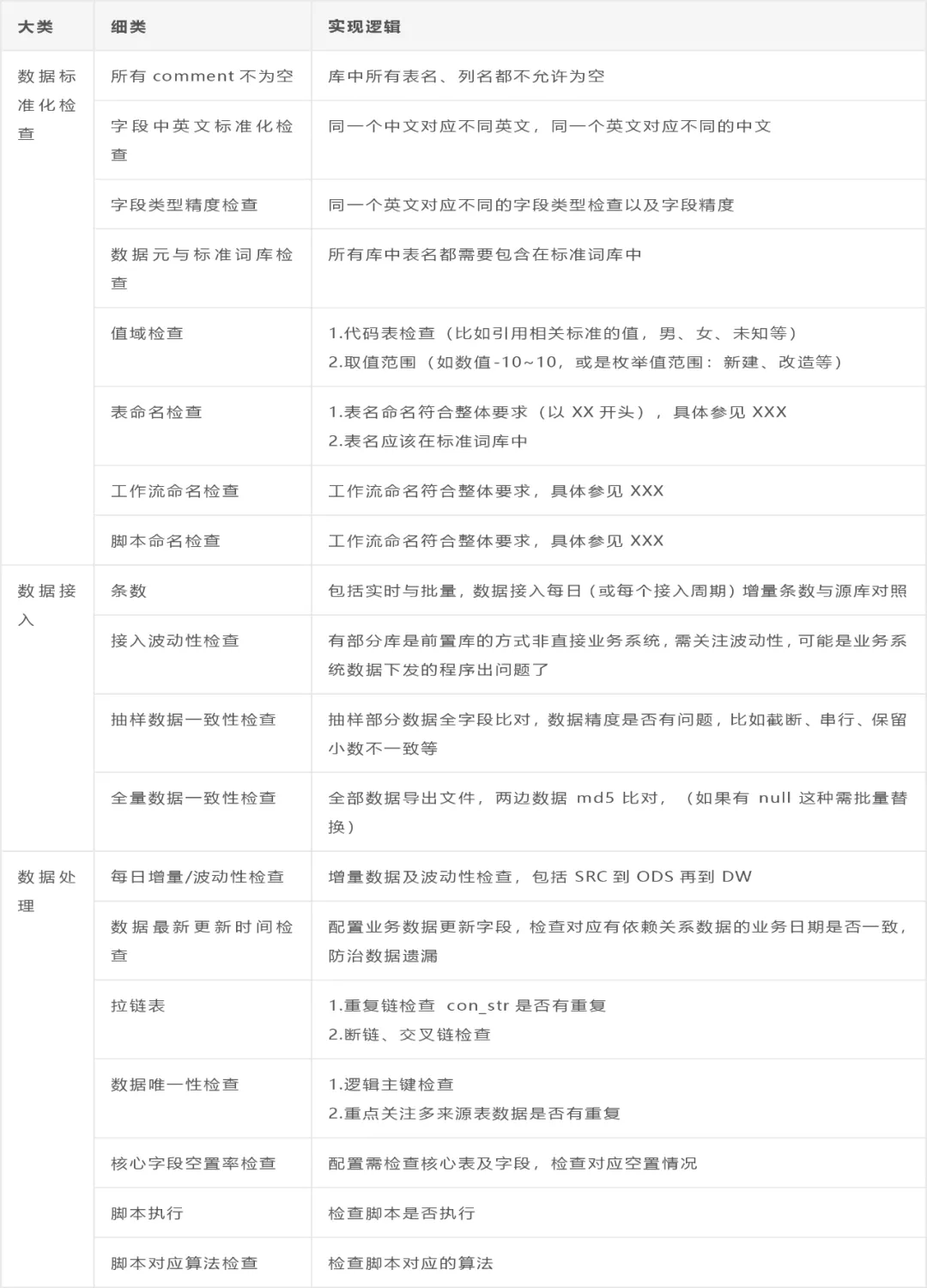
三、数据治理智能化
经过自动化阶段以后数据治理流程中数据仓库模型设计、Mapping 映射等阶段依旧有非常多人工处理工作,这些工作大部分跟业务领域知识及实际数据情况强相关,依赖专业的业务知识和行业经验才可进行合理地规划和设计。如何快速精通行业知识和提升行业经验是数据治理过程中新的“拦路虎”。如何更好地沉淀和积累行业知识,自动地提供设计和处理的建议是数据治理“深水区”面临的一个新的挑战。数据治理智能化将为我们的数据治理工作开辟一个 “新天地”。
在整个数据治理流程中智能化可以发挥作用的的节点如“工序”标红色部分:
实现智能化的第一步是如何积累业务知识及行业经验,形成知识库。数据治理知识库应包括:标准文件、模型(数据元)、DQC 规则及数据清洗方案、脚本数据处理算法、指标库、业务知识问答库等,具体涵盖内容及总体流程如下图所示:
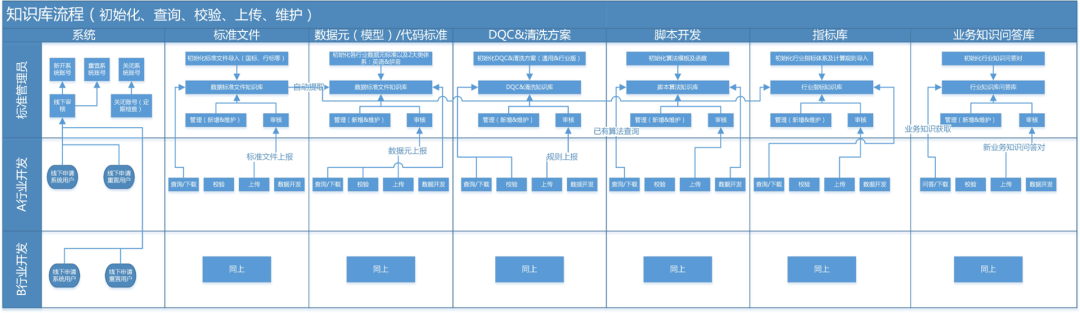
1. 标准文件
在 2B 和 2G 行业尤其是 2G 行业,国家、行业、地方都发布了大量的标准文件,在业务和技术层面都进行了相关约束,并且指导新建业务系统的开发。标准文件知识库涵盖几个方面:a.国标、行标、地标等标准的在线查看 b.相关标准的在线全文检索 c.标准具体内容的结构化解析。
2. 数据元(模型)
对于不同行业来说技术标准中的命名以及模型是目前大家都比较关注的,也是在做数据中台类项目以及数据治理项目比较耗时的地方,在金融领域已经比较稳定的主题模型在其他行业尚未形成统一,所以对于做 2B 和 2G 市场的企业如何能沉淀出特定行业的数据元标准甚至是主题模型,对于行业理解及后续同类项目交付就至关重要。具体包括:实体分类、实体名称名称、中文名称、英文名称、数据类型、引用标准等。
3. DQC(数据质量稽核)&数据清洗方案
数据治理的关键点是提升数据治理,所以不同行业及各个行业通用的数据质量清洗方案及数据质量稽核的沉淀就尤为重要,比如通用规则校验身份证号 18 位校验(15 转 18)、手机号为 11 位(如有国际电话需加国家代码)、日期格式、邮箱格式等。
4. 脚本开发
在数据类项目中,数据 mapping 确认以后就是具体的开发了,由于数据处理方式的共性,可以高度提炼成特定类型的数据处理,比如交易流水一般采用追加的方式,每日新增数据 append 进来即可。状态类的历史拉链表形式等。此过程中的步骤都可以通过自动化程序来实现,同时借助于上面沉淀的具体标准内容,进一步规范化脚本开发。
5. 指标库
对于一个行业的理解一定程度上体现在行业指标体系的建立,行业常用指标是否覆盖全,指标加工规则是否有歧义是非常重要的两个考核项,行业指标库的建立对于业务知识的积累至关重要。
6. 业务知识问答库

行业知识积累的最直观体现是业务知识问答库的建立,各类业务知识都可以逐步沉淀到问答库中,并以问答等多种交互方式更便利的服务于各类使用人员。比如生态环境领域 AQI 的计算规则,空气常见污染因子、各类污染指标的排放限值等,都可以以问答对形式进行沉淀。

基于以上知识的不断沉淀积累,在数据治理开展过程中即可进行智能化推荐。如上图所示,在做实体及属性认定时结合 NLP 技术和知识库规则即可进行相似度认定推荐。
并且随着行业知识的不断积累和完善后期可以直接推荐行业主题模型及主数据模型,以及针对实体及属性的数据标准、数据质量检查规则的推荐。
总结
流程化是数据治理工作开展第一步,是自动化和智能化的基础,将数据治理各节点开展过程中用到的内容进行梳理并规范,包括:业务流程图、网络架构图、业务系统台账等,行业知识梳理完善以后形成行业版知识(抽离通用版),如标准文件梳理:1.代码表整理,2.数据元标准整理(数据仓库行业模型对应标准梳理)。
自动化是将流程化标准后的工作进行自动化开发,涉及仓库模型设计、标准化、脚本开发、DQC、指标体系自动化构建,包括:自动化程序生成和自动化检查。自动程序生成一是解放生产力,提高效率而是提升开发的规范化。自动化检查包括:1.发现数据问题,出具质量报告(唯一性、空值等通用问题),2.行业知识检查(行业版内置,不同行业关注的重要数据问题,并且会不断完善知识库)。
智能化是在流程化、自动化基础之上针对数据拉通整合、主题模型、数据加工检查给出智能化建议,减少人工分析的工作。
总体思路先解决项目上标准化执行问题,然后提升建设效率及处理规范化问题(自动化处理),最后基于业务知识的沉淀最终实现全流程智能化构建。
本文转载自公众号百分点(ID:baifendian_com)。
原文链接:




