
KubeSphere 开源社区的小伙伴们,大家下午好。我是微众银行大数据平台的工程师周可,接下来我会给大家分享基于 WeDataSphere 和 KubeSphere 这两个开源产品构建一个开源的云原生机器学习平台 Prophecis。
Prophecis 是什么?
首先我介绍一下什么是 Prophecis (Prophecy In WeDataSphere)?它的中文含义就是预言的意思。
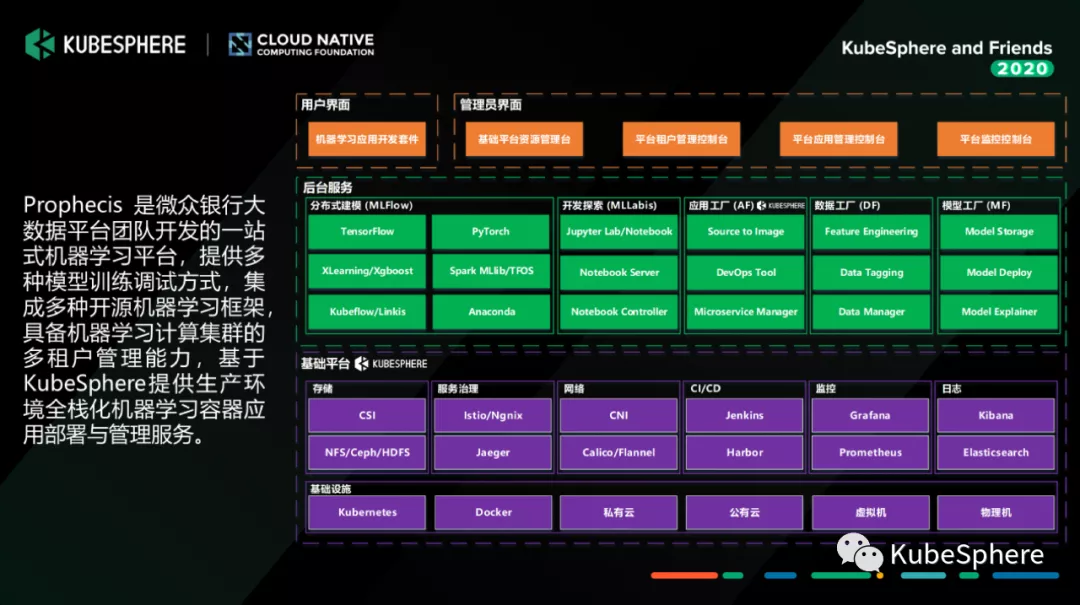
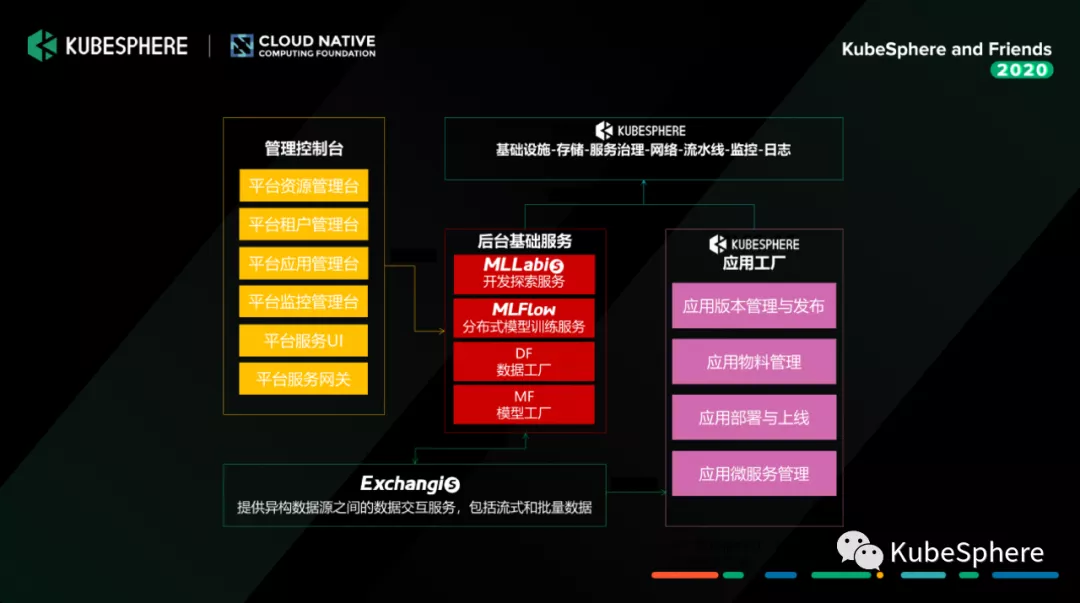
Prophecis 是微众银行大数据平台团队开发的一站式机器学习平台,我们是基于 KubeSphere 管理的这一套多租户的容器化的高性能计算平台之上,搭建了我们提供给数据科学和算法工程师,以及我们的 IT 运维去使用的机器学习平台。在交互界面层,大家可以看到最上面我们是有面向普通用户的一套机器学习应用开发界面,以及面向我们运维管理员的一套管理界面,其中管理员的界面基本上就是基于 KubeSpehre 之上做了一些定制和开发;中间的服务层是我们机器学习平台的几个关键服务,主要为:
Prophecis Machine Learning Flow:机器学习分布式建模工具,具备单机和分布式模式模型训练能力,支持 Tensorflow、Pytorch、XGBoost 等多种机器学习框架,支持从机器学习建模到部署的完整 Pipeline;
Prophecis MLLabis:机器学习开发探索工具,提供开发探索服务,是一款基于 Jupyter Lab 的在线 IDE,同时支持 GPU 及 Hadoop 集群的机器学习建模任务,支持 Python、R、Julia 多种语言,集成 Debug、TensorBoard 多种插件;
Prophecis Model Factory:机器学习模型工厂,提供机器学习模型存储、模型部署测试、模型管理等服务;
Prophecis Data Factory:机器学习数据工厂,提供特征工程工具、数据标注工具和物料管理等服务;
Prophecis Application Factory:机器学习应用工厂,由微众银行大数据平台团队和 AI 部门联合共建,基于青云(QingCloud) 开源的 KubeSphere 定制开发,提供 CI/CD 和 DevOps 工具,以及 GPU 集群的监控及告警能力。
最底层的基础平台就是 KubeSphere 管理的高性能容器化计算平台。
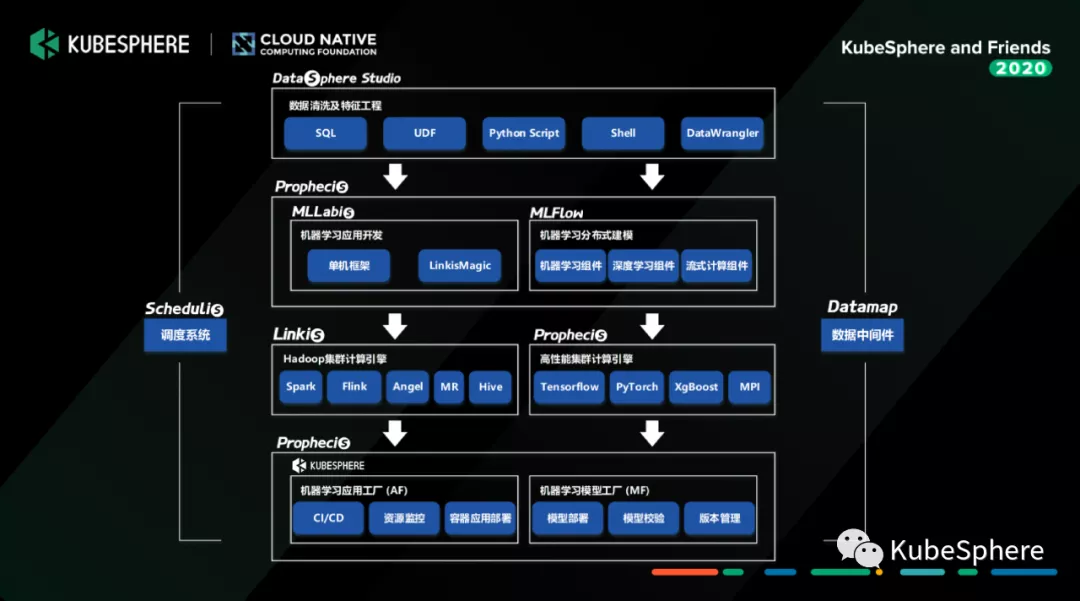
我们去构建这样一套面向我们当前金融场景或者互联网场景的机器学习平台的时候,我们有两个考虑的点:
第一个点是一站式,就是工具要全,从整个机器学习应用开发的整体的 Pipeline 去提供一个完整的生态链工具给到用户去使用;
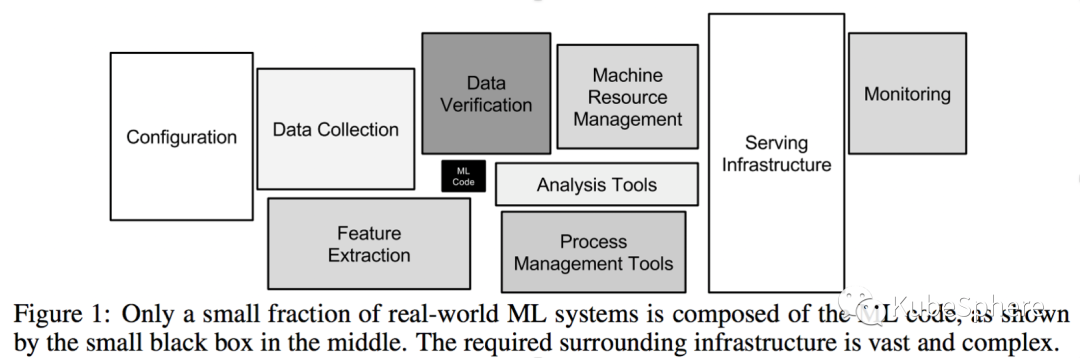
另外一个关注点是全联通,我们去做我们去做机学习应用开发的时候有一个很大的痛点,大家可能之前看到 Google 有一张图,可能 90% 的工作都是在做机器学习之外的工作,然后真正去做模型调参这些东西的时候,可能就 10% 的工作。
因为前面的数据处理其实是有很大工作量的。我们去做的一个工作就是,通过插件化接入的方式把我们的 Prophecis 的服务组件,跟我们 WeDataSphere 上面目前已经提供的调度系统 Schedulis、数据中间件 DataMap、计算中间件 Linkis、还有面向数据应用开发门户的 DataSphere Stduio 这一整套工具链进行打通,构建一个全联通的机器学习平台。
Prophecis 功能组件简介
接下来,简单介绍一下我们机器学习平台 Prophecis 的各个组件的功能。
机器学习开发环境 MLLabis
第一个是我们目前已经放到开源社区的组件叫 MLLabis,其实跟 AWS 的提供给机器学习开发人员去用的 SageMaker Studio 差不多。
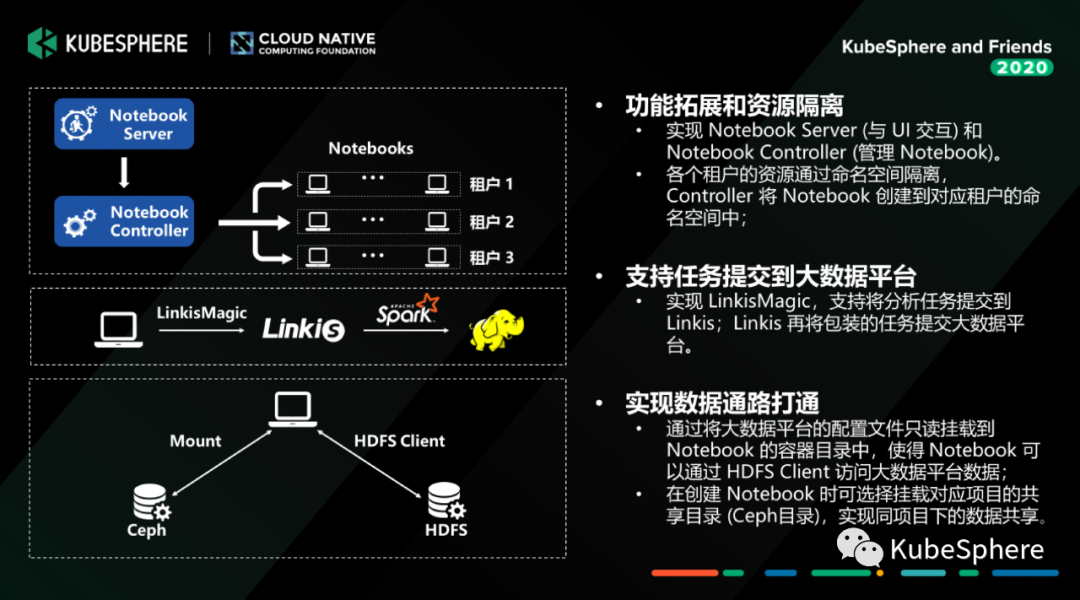
我们在 Jupyter Notebook 做了一些定制开发,总体的架构其实就是左上角的这张图,其实主要的核心有两个组件,一个是 Notebook Server (Restful Server),提供 Notebook 生命周期管理的各种 API 接口;另外一个是 Notebook Controller (Jupyter Notebook CRD),管理 Notebook 的状态。
用户创建 Notebook 的时候,他只需要选择有权限的命名空间 (Kubernetes Namespace),然后去设置 Notebook 运行时需要的一些参数,比如说 CPU、内存、 GPU 或者是它要挂载的存储,如果一切正常,这个 Notebook 容器组就会在对应的 Namespace 启动并提供服务。
我们在这里做了一个比较加强的功能,就是提供一个叫 LinkisMagic 的组件。我们 WeDataSphere 开源产品中有个组件叫 Linkis,它提供大数据平台计算治理能力,打通各个底层的计算、存储组件,然后给到上层去构建数据应用。
LinkisMagic 通过调用 Linkis 的接口,就可以将 Jupyter Notebook 中写好的数据处理的代码提交到大数据平台上去执行;我们可以把处理好的特征数据通过 Linkis 的数据下载接口拉到 Notebook 的挂载存储中去,这样我们就可以在我们的容器平台里面用 GPU 去做一些加速的训练。存储方面,目前 MLLabis 提供两种数据存储,一种是 Ceph;一种是我们的大数据平台 HDFS,关于 HDFS 这里提一句,我们其实就是把 HDFS Client 和 HDFS 的配置文件通过 Mount 到容器中,并且控制好权限,就可以在容器内跟 HDFS 交互了。
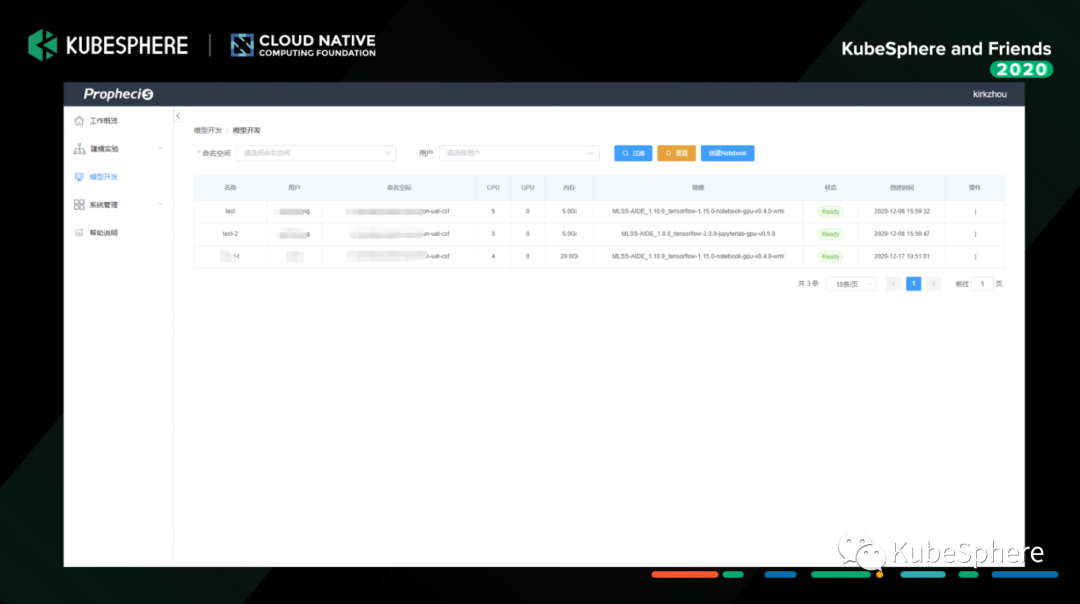
以上是我们 MLLabis 的 Notebook 列表页面;
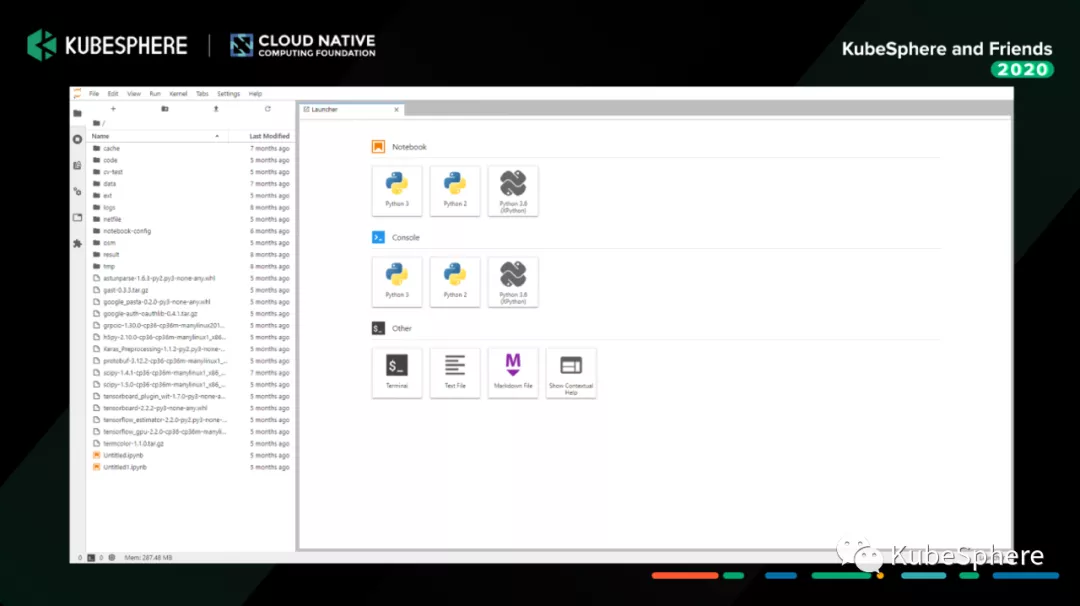
以上是我们从列表页面进到 Notebook 的界面。
机器学习分布式建模服务 MLFLOW
接下来,介绍我们另外一个组件 MLFlow。
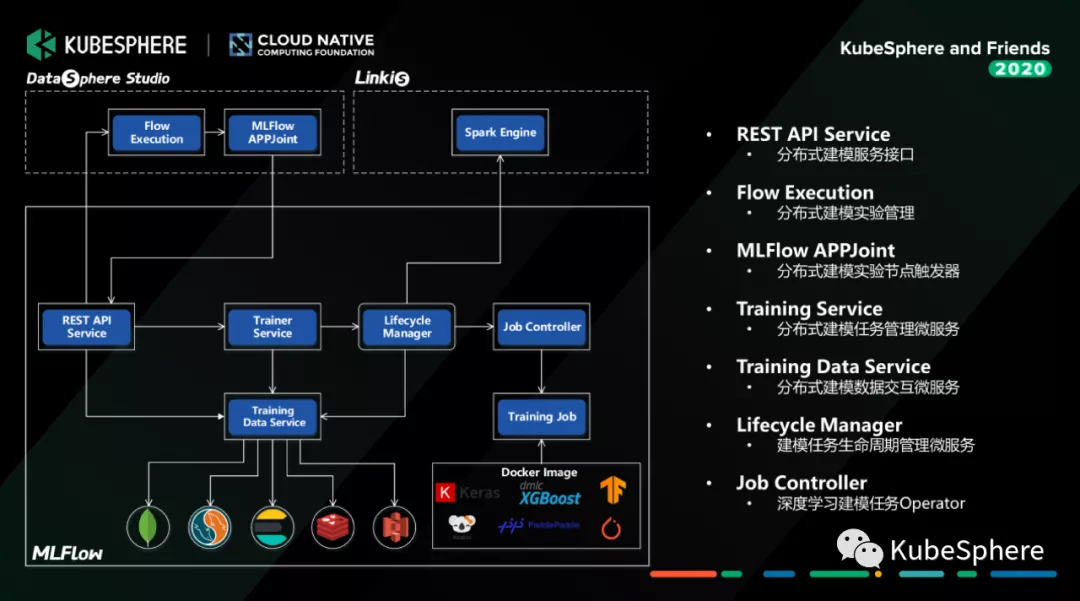
我们构建了一个分布式的机器学习实验管理服务。它既可以管理单个建模任务,也可以通过跟我们 WeDataSphere 一站式数据开发门户 DataSphere Studio 打通,构建一个完整的机器学习实验。这里的实验任务通过 Job Controller (tf-operator、pytorch-operator、xgboost-operator 等)管理运行在容器平台上,也可以通过 Linkis 提及到数据平台运行。
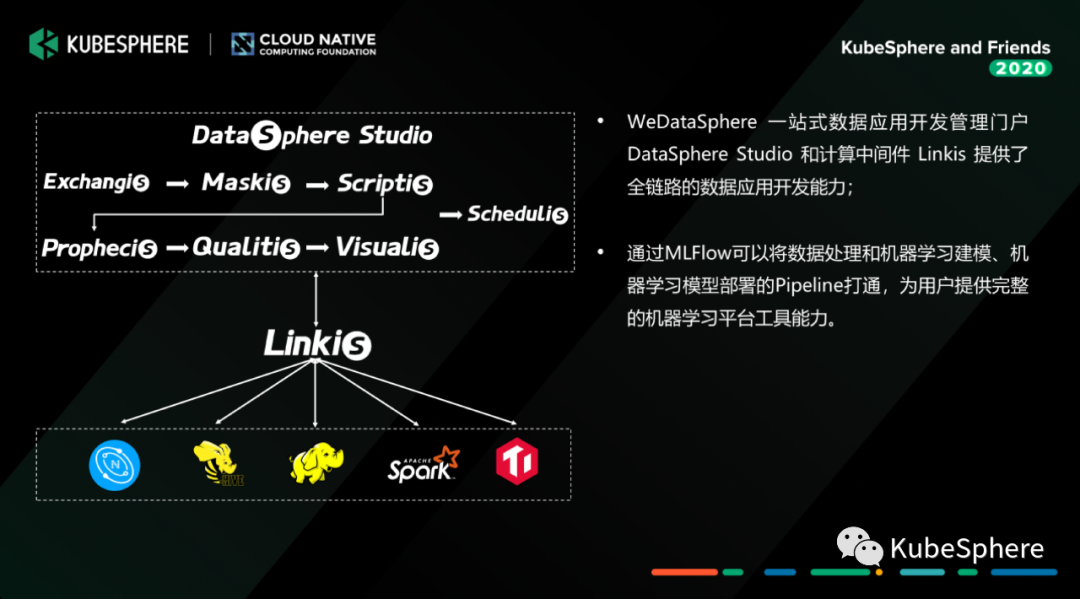
这里再说明一下,MLFlow 与 DataSphere Studio 之间通过 AppJoint 的方式交互,这样既可以复用 DSS 已经提供的工作流管理能力,又可以将 MLFlow 实验作为子工作流接入到 DSS 这个大的数据工作流中去,这样构建一个从数据预处理到机器学习应用开发的 Pipeline。
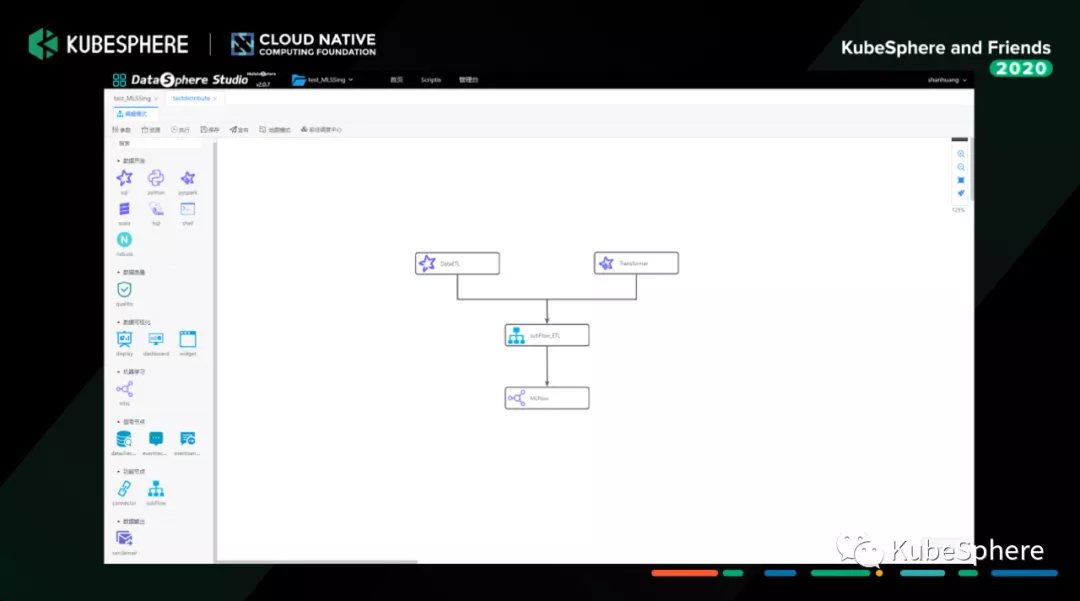
这个是我们数据处理和机器学习实验组成的完成数据科学工作流。
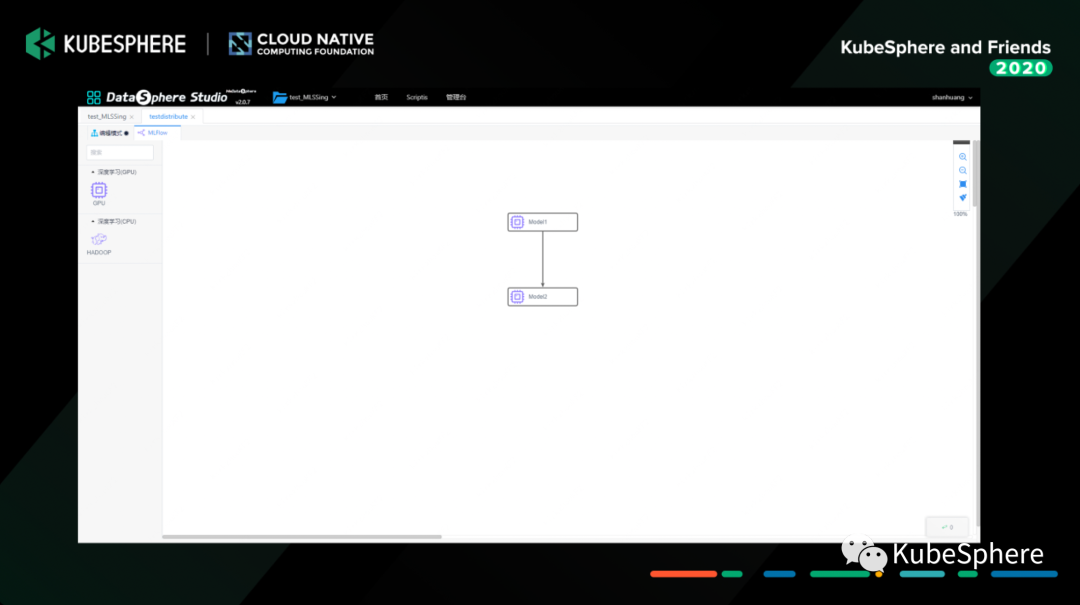
这个是 MLFlow 的机器学习实验 DAG 界面,目前提供 GPU 和 CPU 两种任务类型,支持 TensorFlow、PyTorch、xgboost 等机器学习框架任务的单机和分布式执行。
机器学习模型工厂 Model Factory
接下来给大家介绍我们的机器学习模型工厂:Model Factory。我们模型建好之后,我们怎么去管理这些模型,它的模型的版本怎么管理,它的部署怎么管理,模型的校验怎么做,我们用的就是 Model Factory。
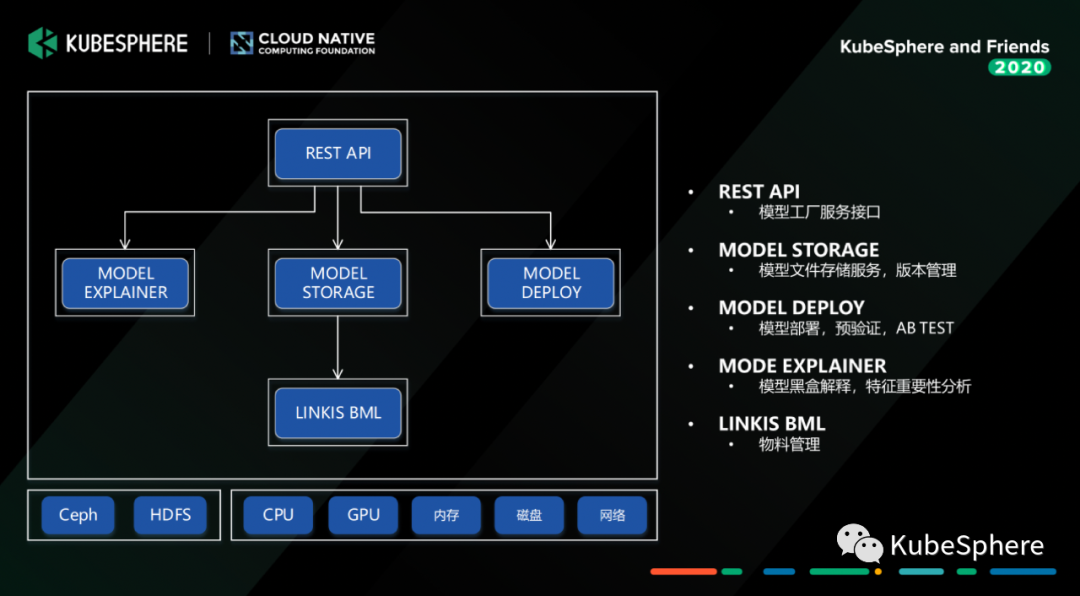
这个服务我们主要是基于 Seldon Core 进行二次开发,提供模型解释、模型存储、模型部署三块的能力。要强调的一点是这一块的服务接口我们也可以接入到 MLFlow 中去,作为一个 Node 接入到机器学习实验中,这样训练好的模型,可以通过界面配置快速部署,然后进行模型验证。另外一个要说明的是,如果我们只是单模型的验证,我们主要是使用 MF 提供的基于 Helm 的部署能力。如果是构建一个复杂的生产可用的推理引擎,我们还是会用 KubeSphere 提供的 CI/CD、微服务治理能力去构建和管理模型推理服务。
机器学习数据工厂 Data Factory
接着要介绍的组件是我们数据工厂 Data Factory。
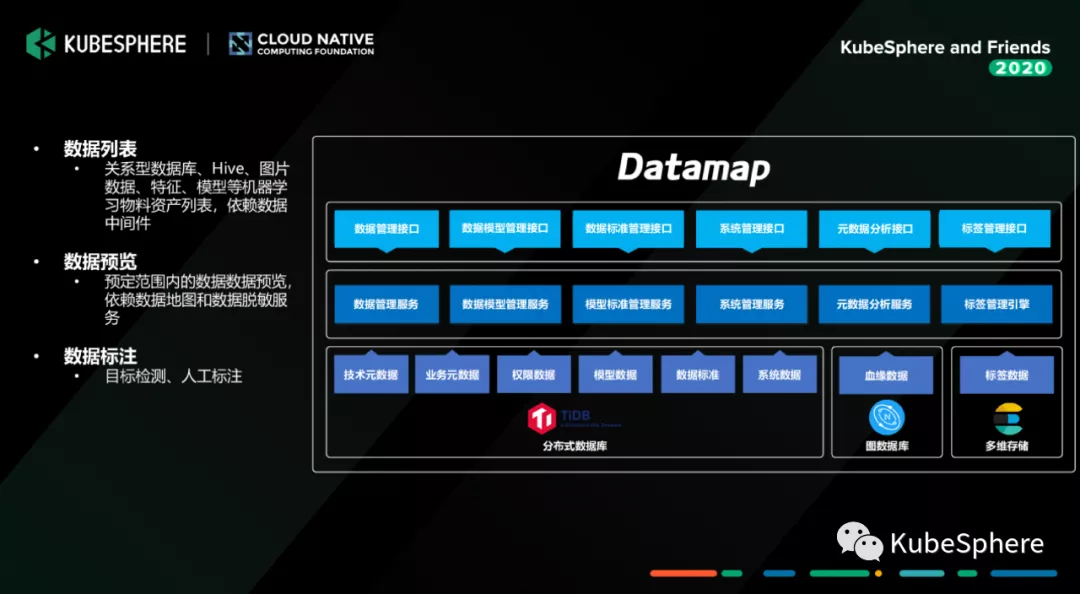
关于数据工厂我们是通过数据发现服务从 Hive、MySQL、HBase、Kafka 等数据组件中获取基础的元数据,并提供数据预览和数据血缘分析能力,告诉我们数据科学和建模人员,他要使用的数据是长什么样子的,可以怎么用。未来也会提供一些数据标注的工具,或者是数据众包的工具,让我们的数据开发同学来完成数据标注的这块的工作。
机器学习应用工厂 Application Factory
最后一个要介绍的组件,就是机器学习应用工厂 Application Factory。
正如刚才所说,我们如果对一些复杂的模型去构建一些复杂的 Inference Sevice 的时候,其实我们用一个简单的单容器服务其实是不够的,我们要去构成一整套的类似于 DAG 的一个推理的过程,这个时候其实我们就需要更复杂的容器应用的管理的能力。
Application Factory 这一块我们就是基于 KubeSphere 去做的,我们在前面做好这些模型的准备之后,我们会使用 KubeSphere 提供的 CI/CD 工作流去完成整体的模型应用发布流程,模型服务上线之后,使用 KubeSphere 提供的各种 OPS 工具去运维和管理各个业务方的服务。
KubeSphere 应用实践
接下来进入到 KubeSphere 在我们微众银行应用实践部分。
使用 KubeSphere 前我们面对的问题
我们在引入 KubeSphere 之前,其实我们面对的问题,主要还是一些运维的问题。当时,我们内部也有用我们自己写的一些脚本或者是 Ansible Playbook 去管理我们这一套或者几套 K8s 集群,包括我们在公有云上面的开发测试集群,以及行内私有云的几套生产 K8s 集群。

但是这一块由于我们的运维人力有限,去管理这块东西的时候其实是非常复杂的;我们的建好的模型是面向银行业务使用,有的是跟风控相关的,对于整体服务的可用性的要求还是很高的,我们如何做好各个业务方的租户管理、资源使用管控、以及怎么去构成一个完整的监控体系,也是我们去需要重点关注的;还有就是本身 Kubernetes Dashboard 基本上没什么可以管理的能力,所以我们还是希望有一套好用的管理界面给了我们的运维人员,让他们的运维效率更高一些。
以 KubeSphere 为底座开发机器学习容器平台
因此,我们选择了构建一个以 KubeSphere 为基础运维管理基座的机器学习容器平台。
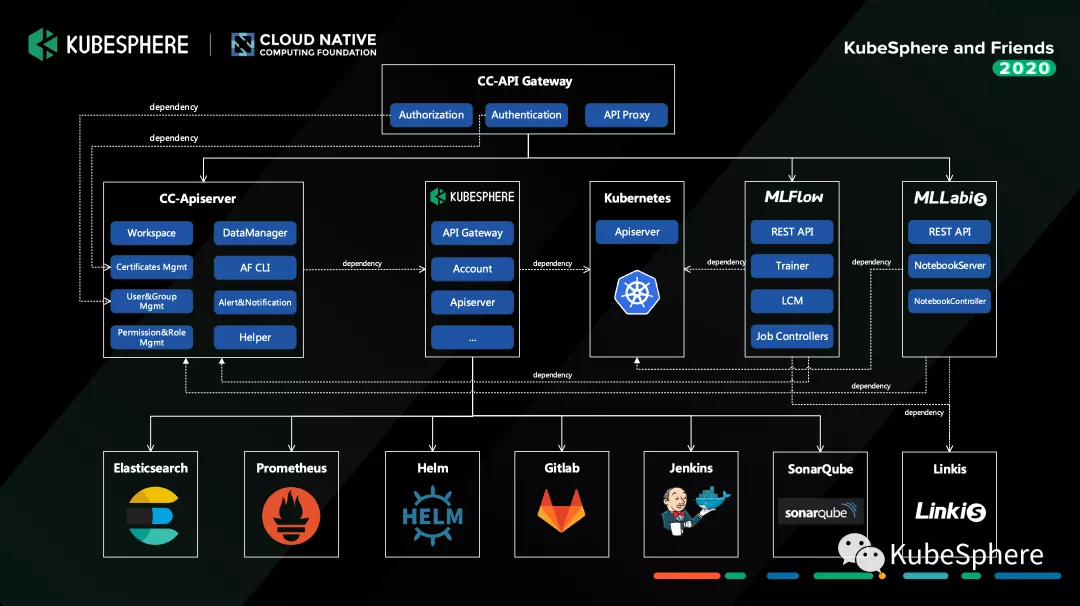
整体的服务架构基本是跟 KubeSphere 当前的 API 架构差不多,用户的请求进来之后,它通过 API Gateway 定位要访问服务,这些服务就是刚才介绍那些组件,Gateway 将请求分发到对应的微服务当中去。各个服务依赖的那些容器平台的管理,就是 KubeSphere 全栈平台去给我们提供的能力:CI/CD、监控、日志管理,还有代码扫描工具等,然后我们在这一套解决方案之上做了一些改造点,但总体来说改造的东西也不是特别多,因为当前开源的 KubeSphere 提供的这些能力基本上能满足我们的需求。
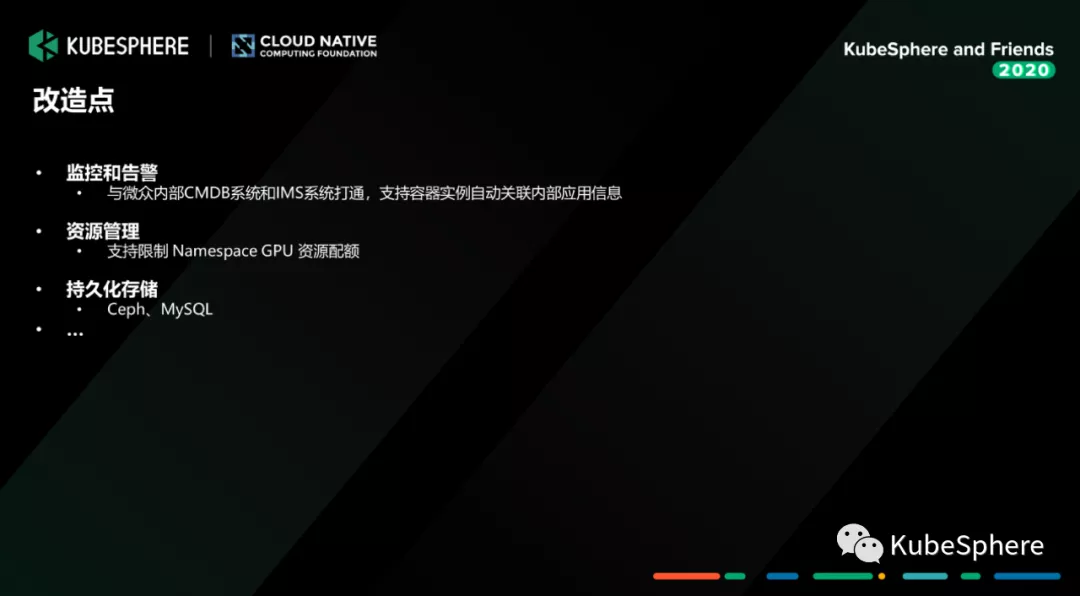
我们内部使用的版本是 KubeSphere 的 v2.1.1,我们改造主要如下:
监控和告警:我们把 KubeSphere Notification 和我们行内的监控告警系统进行了打通,同时将容器实例的配置信息和我们的 CMDB 系统中管理的业务信息进行关联,这样某个容器出现异常就可以通过我们告警信息发出告警消息,并告诉我们影响的是哪个业务系统;
资源管理:我们在 KubeSphere Namespace 资源配额管理上做了一点小小的拓展,支持 Namespace 的 GPU 资源配额管理,可以限制各个租户可以用使用的基础 GPU 资源和最大 GPU 资源;
持久化存储:我们将容器的内的关键服务存储都挂载到我们行内的高可用的分布式存储 (Ceph) 和数据库 (MySQL) 上,保障数据存储的安全性和稳定性。
这是我们测试环境的一个管理界面。
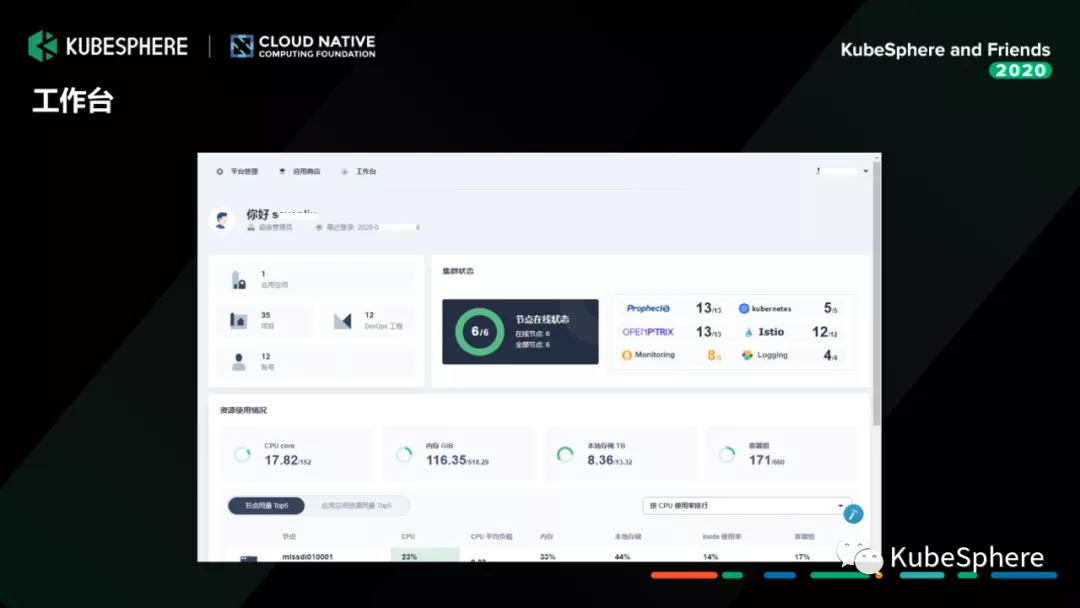
其实这里我们主要做了两个事情,第一我们把整个监控的对象跟我们行内的这一套 CMDB 系统进行结合。
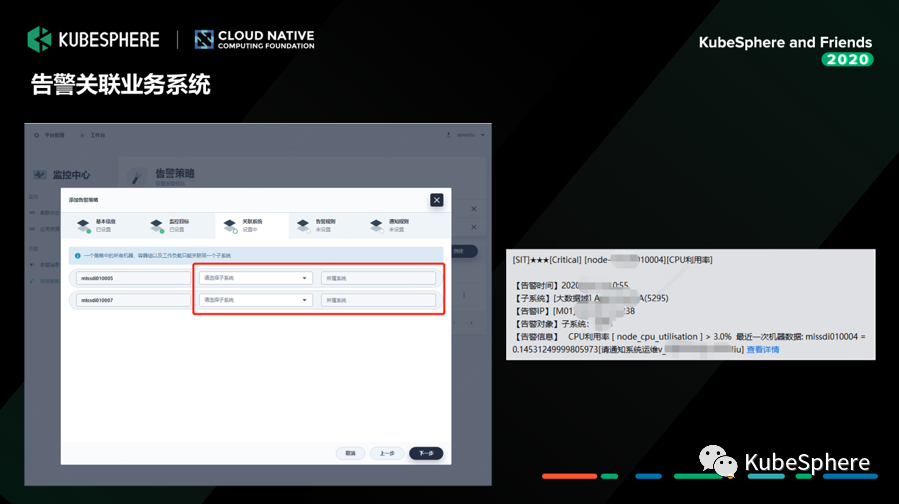
系统发生告警的时候,我们通过跟这套 CMDB 系统去做配置关联的,我们可以知道这一个告警实例它影响了的业务系统是哪些,然后一旦出现异常的时候,我们就会通过调用我们的告警系统,这里是一个企业微信的一个告警信息,当然它也可以发微信,也可以打电话,也可以发邮件。
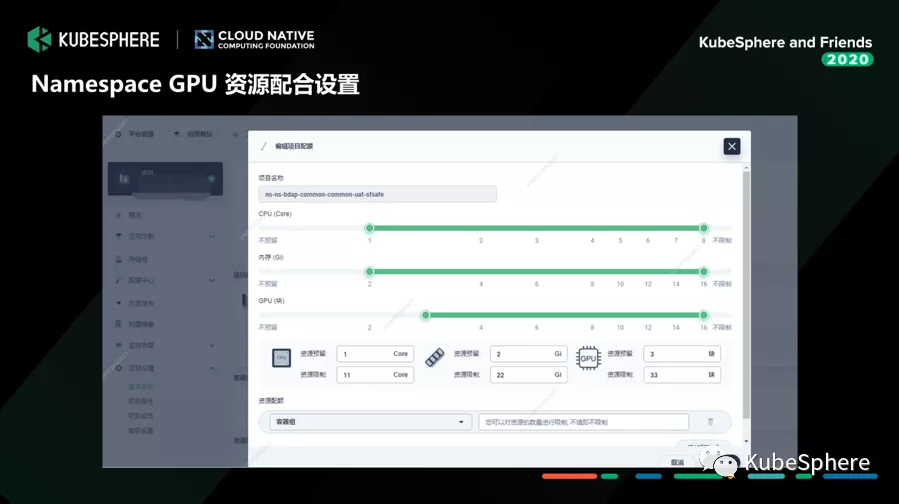
以上这一块是我们做的 GPU 资源配额定制。
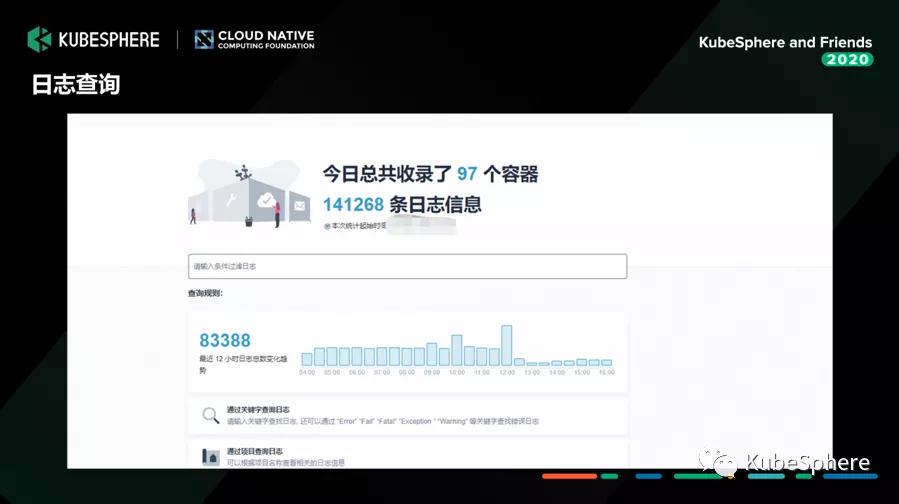
这一块是我们基于 KubeSphere 的日志查询界面。
未来展望
接下来说下未来的展望。由于我们当前因为我们人力非常有限,然后各个组件开发的压力也比较大,目前,我们还是基于之前的 KubeSphere v2.1.1 的版本去做的,我们接下来考虑把 KubeSphere 3.0 这块的东西去跟我们现有开发的一些能力做结合和适配。

第二,目前 KubeSphere 还没有 GPU 监控和统计指标管理的一些能力,我们也会考虑去把我们之前做的一些跟 GPU 监控与配额管理等功能迁移到 KubeSphere Console 里面去。
最后一个是我们整个 WeDataSphere 各个的组件基于 KubeSphere 的容器化适配和改造,我们最终是希望各个组件都完成容器化,进一步降低运维管理成本和提升资源利用率。
关于 WeDataSphere
说到这里,我就简单再介绍一下我们微众银行大数据平台 WeDataSphere。

WeDataSphere 是我们大数据平台实现的一整套金融级的一站式机器学习大数据平台套件。它提供从数据应用开发、到中间件、在到底层的各个组件功能能力,还有包括我们的整个平台的运维管理门户、到我们的一些安全管控、还有运维支持的这块一整套的运营管控能力。

目前,这些组件当中没有置灰的这部分已经开源了,如果大家感兴趣可以在 GitHub 关注一下。
社区合作
再展望一下,我们 WeDataSpehre 跟 KubeSphere 的未来,目前我们两个社区已经官宣开源合作。
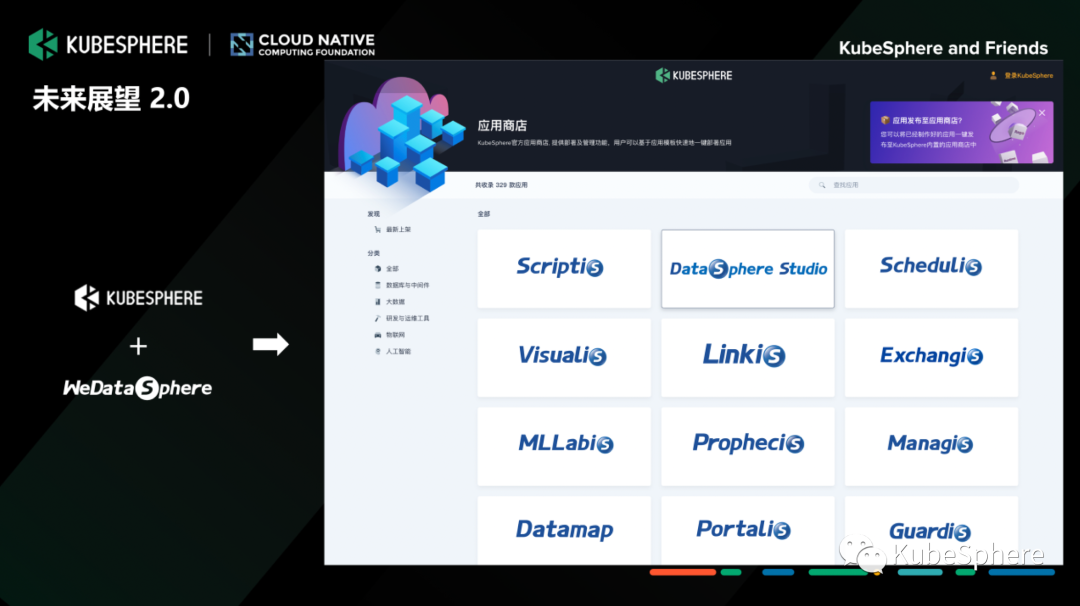
我们计划把我们 WeDataSphere 大数据平台这些组件全部能容器化,然后贡献到 KubeSpehre 应用商店中,帮助我们用户去快速和高效的完成我们这些组件与应用的生命周期管理、发布。

欢迎大家关注我们 Prophecis 这个开源项目以及我们 WeDataSphere 开源社区助手,如果大家对这套开源的云原生机器学习平台有任何问题,可以跟我们进一步交流,谢谢大家。
头图:Unsplash
作者:周可
原文:https://mp.weixin.qq.com/s/0n2qnFw7QcGn9F3G9qSm5A
原文:基于 WDS Prophecis 与 KubeSphere 构建云原生机器学习平台
来源:KubeSphere - 微信公众号 [ID:gh_4660e44db839]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




