
本文最初发表于 Uber 官方博客,经授权由 InfoQ 中文站翻译并发布。
前言
在过去几年,Uber 各种组织和用例中的机器学习应用明显增多。我们的机器学习模型实时为用户提供了更好的体验,帮助预防安全事故并确保市场效率。
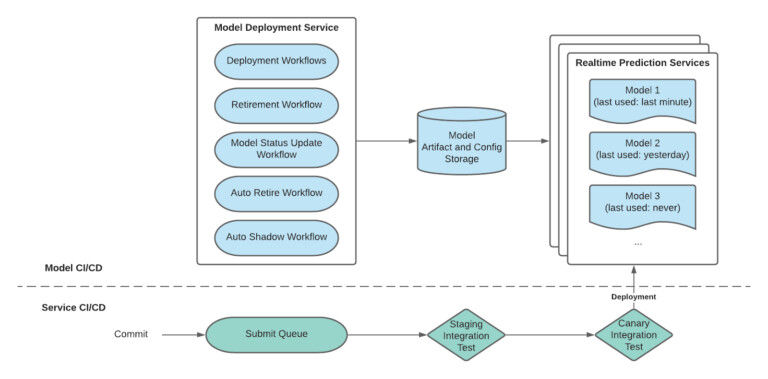
需要注意的一点是,我们对模型和服务进行了持续集成(CI)和持续部署(CD),如上图所示。因为训练和部署的模型增长迅速,我们在经过多次迭代后,终于找到了解决 MLOps 挑战的解决方案。
具体来说,主要有四大挑战。第一个挑战是每天要支持大量模型部署,同时保持实时预测服务的高度可用。在模型部署一节,我们将讨论这项挑战的解决方案。
第二个挑战是,在部署新的重新训练的模型时,与实时预测服务实例相关的内存占用增加了。许多模型还增加了实例(重新) 启动时下载和加载模型所需的时间。在实施新模型时,我们发现,很大一部分旧模型没有收到流量。在模型自动退役一节中,我们将讨论这项挑战的解决方案。
第三个挑战涉及到模型推出策略。机器学习工程师可以通过不同的阶段推出模型,如遮蔽、测试或实验。我们注意到了一些模型推出策略的常见模式,并决定把它纳入实时预测服务中。对于这项挑战,我们将在自动遮蔽一节中对其进行讨论。
我们管理的是一个实时预测服务的集群,因此不可以选择人工服务软件部署。最后一项挑战是为实时预测服务软件制定一个 CI/CD 故事。在模型部署期间,模型部署服务通过对样本数据的预测调用对候选模型进行验证。但是,它不会检查部署到实时预测服务的现有模型。即便模型通过了验证,也不能保证在部署到生产实时预测服务实例时,该模型可以被使用或表现出相同的行为(用于特征转换和模型评估)。
出现这种情况的原因是,两个实时预测服务版本之间可能会有依赖关系的改变,或者服务构建脚本改变。在持续集成和部署一节中,我们将讨论这项挑战的解决方案。
模型部署
要管理在实时预测服务中运行的模型,机器学习工程师可以通过模型部署 API 来部署新的模型和退役未使用的模型。他们可以通过 API 跟踪模型的部署进度和运行状态。在图 2 中,你可以看到系统的内部架构:
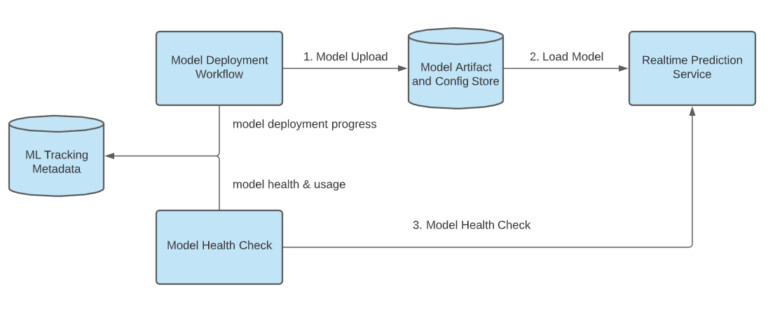
动态模型加载
过去,我们将模型构件封入实时预测服务的 Docker 镜像,并与服务一起部署模型。由于模型的快速部署,这一繁重的过程成为模型迭代的瓶颈,并导致模型和服务开发者之间的中断。
针对这一问题,我们实现了动态模型的加载。模型构件和配置存储保存了生产环境中应该为哪些模型提供服务的目标状态。一个实时预测服务会定期检查这个存储,比较它与本地状态,从而触发对新模型加载和删除退役模型。动态模型加载将模型与服务器的开发周期解耦,从而加快生产模型的迭代速度。
部署模型工作流
并非简单地将训练好的模型推送到模型构件和配置存储中,它通过多个步骤创建独立的、已验证的模型包:
构件验证:确保所训练的模型包含服务和监控所必需的所有构件。
编译:将所有模型构件和元数据打包到一个自包含的可加载包中,并将其打包到实时预测服务中。
服务验证:在本地加载编译好的模型 jar,并用训练数据集中的样本数据进行模型预测——这一步确保了模型能够运行,并且与实时预测服务兼容。
之所以这样做,主要是为了保证实时预测服务的稳定性。因为在同一个容器中加载了多个模型,一个错误的模型可能会导致预测请求失败,并且有可能中断同一个容器上的模型。
模型部署跟踪
要帮助机器学习工程师管理他们的生产模型,我们可以对部署模型进行跟踪,如上图 2 所示。该方案由两部分组成:
部署进度跟踪:部署工作流将发布部署进度更新到一个集中式元数据存储中以便跟踪。
运行状况检查:模型在完成其部署工作流之后,将成为模型运行状况检查的候选对象。这个检查定期进行,以跟踪模型的健康状况和使用信息,并将更新信息发送到元数据存储。
模型自动退役
有一个 API 可以让未使用的模型退役。但是,在很多情况下,人们忘记了这样做,或者没有将模型清理纳入他们的机器学习工作流中,这样会造成不必要的存储成本和增加内存占用。大量的内存占用会导致 Java 垃圾收集暂停和内存不足,这两种情况都会影响服务质量。
为解决这一问题,我们建立了一个模型自动退役流程,所有者可以为模型设定一个到期时间。若模型在到期后未使用,则上图 1 中的自动退役工作流会为相关用户触发警告,并使模型退役。当启用该特性之后,我们看到了资源占用率的显著下降。
自动遮蔽
随着机器学习工程师选择采用不同的策略推出模型,他们经常需要设计一种在一组模型中分配实时预测流量的方法。我们看到了它们的流量分配策略中的一些常见模式,比如渐进式推出和遮蔽。
通过渐进式推出,用户复制流量,并逐步在一组模型中改变流量分布。对于遮蔽过程,客户端复制初始(主) 模型的流量,并将其应用于另一个(遮蔽)模型。图 3 显示了一组模型之间典型的流量分布,其中模型 A、 B、 C 参与渐进式推出,而模型 D 则对模型 B 进行遮蔽。
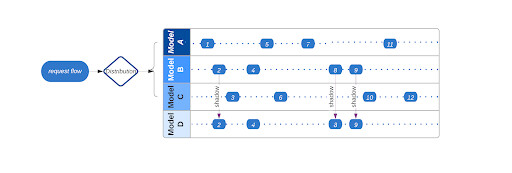
为减少对常见模式开发重复实现的工程时间,实时预测服务提供了用于流量分布的内置机制。接下来我们关注的是自动遮蔽模型的情况。
虽然不同团队采用不同的模型遮蔽策略,但具有共性:
来自生产数据的模型预测结果并不用于生产,而是为了分析收集。
遮蔽模型与其主模型共享大部分特征,这在定期重新训练和更新模型的用户工作流中尤其如此。
在遮蔽停下来之前,通常要持续数天或数周的时间窗。
一个主模型可以被多个遮蔽模型所影射;一个遮蔽模型可以影射多个主模型。
遮蔽流量可以是 100% 的,也可以根据主要模型流量的一些标准来挑选。
为了比较结果,对主模型和遮蔽模型都收集了相同的预测。
一个主模型可能要为数百万次的预测提供服务,预测日志可能会被采样。
在模型部署配置中,自动隐藏配置只是其中的一项工作。实时预测服务可以检查自动遮蔽的配置,并相应地分配流量。用户仅需通过 API 端点设定遮蔽关系和遮蔽标准(遮蔽内容,遮蔽时间长短),并确保增加遮蔽模型所需的功能,而非主模型。
我们发现内置的自动遮蔽功能带来了额外的好处:
大部分的主模型和遮蔽模型具有一套共同的特征,实时预测服务只能从在线的特征库提取主模型中未使用的特征,从而用于遮蔽模型。
通过结合内置的预测日志逻辑和遮蔽采样逻辑,实时预测服务可以将遮蔽流量减少到那些注定要被记录的流量。
如果服务受到压力,可以将遮蔽模型看作是一个二级模型,并暂停 / 恢复,以缓解负载压力。
持续集成和部署
我们依靠 CI/CD 为一个实时预测服务的集群进行服务发布部署。由于我们支持关键的业务用例,除了在模型部署期间进行验证之外,我们还需要确保对自动持续集成和部署过程的高度信任。
我们的解决方案尝试通过新版本解决下列问题:
代码变化不兼容:这个问题可能有两个症状 —— 模型无法加载或用新的二进制文件进行预测,或者其行为会随着新版本的发布而改变。后一种方法难以识别和修正,对模型的正确性也至关重要。
依赖关系不兼容:由于基础依赖关系的改变,服务无法启动。
构建脚本不兼容:由于构建脚本的改变,版本无法构建。
针对以上问题,我们采用了三个阶段的策略来验证和部署二进制文件的最新实时预测服务:staging 集成测试、金丝雀集成测试以及产品发布。
staging 集成测试和金丝雀集成测试将运行于非生产环境。staging 集成测试用于验证基本功能,当 staging 集成测试通过后,我们将运行金丝雀集成测试来确保所有产品模型的服务性能。在确保生产模型的行为不变后,以滚动部署的方式,将该版本部署到所有实时预测服务的生产实例上。
最后的想法
我们已经分享了我们针对一些 MLOps 挑战的解决方案。随着我们发展 Uber 的机器学习基础设施和平台并支持新的机器学习用例,我们看到新的 MLOps 挑战出现。其中,有几个方面是:几乎实时地监测推理的准确性、特征质量和业务指标;部署和维护多任务学习和混合模型;进行特征验证;改进模型回归机制;模型可追溯性和可调试性等。敬请关注。
作者介绍:
Joseph Wang,Uber 机器学习平台团队软件工程师。住在旧金山。致力于特征存储、实时模型预测服务、模型质量平台和模型性能。
Jia Li,Uber 机器学习平台团队高级软件工程师。致力于模型部署、实时预测和模型监控。
Yi Zhang,Uber 机器学习平台团队高级软件工程师。在解决从数据基础设施到数据应用层的大数据问题方面表现出色。
Yunfeng Bai,Uber 机器学习平台团队的 TLM 成员。他领导团队在模型管理和实时预测方面作出了相关努力。
原文链接:




