
导读 :手把手教你不受 YouTube 算法的操控,创造自己的算法观看你真正想要的视频!
本文最初发表于 Towards Data Science 博客,经原作者 Chris Lovejoy 授权,InfoQ 中文站翻译并分享。
摆脱 YouTube 算法
我喜欢观看 YouTube 上的视频,他们在某种程度上改善了我的生活。可惜,YouTube 的算法并不一致。这就像是提供点击和其他垃圾信息。
一点也不奇怪。算法会优先考虑点击量和观看时间。
于是我开始了一项任务: 我能不能编写出代码,能自动帮助我找到有价值的视频,消除我对 YouTube 算法的依赖?
事情是这样的。
完美的计划
首先想象一下这个工具能做些什么。我希望这个工具能够:
(i) 根据我可能的相关性 对视频进行排名 ,
(ii) 自动向我发送推荐的视频 ,我可以从中选择。
我想,如果我能够批量地决定每周要看的视频,并避免无限滚动的 YouTube 浏览,我就能大幅提高工作效率。
我知道,为了获得视频信息,我需要 YouTube API(什么是 API?),接下来我将会创建一个公式,对这些信息进行处理,并对视频进行排名。最后一步,我计划使用 AWS Lambda 给自己设置一封自动邮件,它将会列出排名靠前的视频。
然而,最后的结果却并非如此。
(如果你希望跳过本文,直接查看最终代码,请点击 此处)
浏览 YouTube API
我想找到一些指标,这样我就可以根据视频可能引起的兴趣对我可能产生的兴趣来对其进行排名。
我在这里阅读了 YouTube 的文档,发现你可以在 视频 级别(标题、发布时间、观看次数、缩略图等)和 频道 级别(订阅者数量、评论、观看次数、频道播放列表等)获得信息。
看到这篇文章后,我非常自信能够用它来定义一个指标并对视频进行排名。
我通过这里的开发者控制台获得了一个 API 密钥,并将其复制到 Python 脚本中。
这使你能够使用以下代码段对 API 调用进行初始化,并检索结果:
# Call the YouTube APIapi_key = ‘AIzpSyAq3L9DiPK0KxrGBbdY7wNN7kfPbm_hsPg’ # Enter your own API key – this one won’t workyoutube_api = build(‘youtube’, ‘v3’, developerKey = api_key)results = youtube_api.search().list(q=search_terms, part=’snippet’, type=’video’, order=’viewCount’, maxResults=50).execute()这将返回一个 JSON 对象,我可以对其进行解析以找到合适的信息。例如,为了查找发布的日期,我可以对结果进行索引,如下所示:
publishedAt = results[‘items’](0)[‘snippet’](‘publishedAt’)这里有一个很有用的视频系列,可以帮助你理解如何使用 YouTube API。
寻找有价值的视频:定义公式
既然我可以查询合适的信息了,我就需要使用获得的值根据我对视频的兴趣来对它们进行排名。
这是个棘手的问题。 什么是好视频? 是看观看次数吗?评论的数量?还是看这个频道的订阅者数量?
我决定从总观看次数开始,作为一个合理的一级代理,来衡量视频的价值。从理论上讲,那些有趣或解释得很清楚的视频将获得积极的观众反馈,并得到更多的推广,从而获得更多的观看次数。
然而,有一些事情是总观看次数没有考虑到的:
首先, 如果一个频道吸引了大量的观众,那么与较小的频道相比,获得可比的观看次数要容易得多 。其中一些可能反映了更多的经验导致更好的视频,但我不想忽视小渠道潜在的高质量视频。一个有用 1 万订阅者的频道的 10 万观看次数的视频可能比一个拥有 100 万订阅者的频道的 10 万观看次数的视频更好。
其次,视频可能会 因错误的原因而获得大量的浏览量 ,比如标题党或缩略图,或者引起争议。我个人对这类视频不太感冒。
我需要加入其他指标,下一个是订阅者数量。
我测试的排名完全基于 浏览量和订阅者的比率 (即用浏览量除以订阅者数)。
# Function to calculate view-to-sub ratiodef view_to_sub_ratio(viewcount, num_subscribers): if num_subscribers == 0: return 0 else: ratio = viewcount / num_subscribers return ratio当我看到结果时,其中一些看起来很有前途。然而,我确实注意到了一个问题:对于订阅者数量非常小的视频,分数会被严重放大并浮现在顶部。
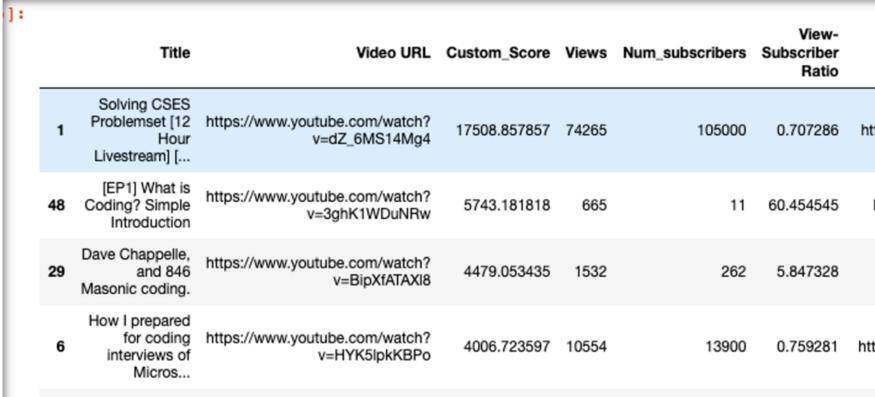
虽然排名靠前的视频看起来可能很有趣,但第二个和第三个视频并不是我真正想要的。
我花了一些力气去消除这些负面的边缘案例。
我把最低观看次数设为 5000 次;
我将观看次数 / 订阅者数量的最大比率设为 5。
# Calculating ratio while removing edge cases (of low views or low subscribers)def custom_score(viewcount, ratio, days_since_published): ratio = min(ratio, 5) score = (viewcount * ratio) return score我尝试了各种阈值,这些阈值似乎能很好地过滤掉那些观看次数很低的视频。我在几个不同的主题上测试了一下代码,并开始获得相当不错的结果。
然而,我注意到了另一个问题: 发布时间较长的视频获得更多观看次数的机会更大 。它们只是有更长的时间来积累观看次数而已。
我的计划是每周运行一次代码,因此我决定将搜索限制在过去 7 天内发布的视频。
def get_start_date_string(search_period_days): """Returns string for date at start of search period.""" search_start_date = datetime.today() – timedelta(search_period_days) date_string = datetime(year=search_start_date.year,month=search_start_date.month, day=search_start_date.day).strftime(‘%Y-%m-%dT%H:%M:%SZ’) return date_string# Creating date string and executing searchdate_string = get_start_date_string(7)results = youtube_api.search().list(q=search_terms, part=’snippet’, type=’video’, order=’viewCount’, maxResults=50, publishedAfter=date_string).execute()我还将“发布后的天数”添加到排名指标中。我决定用之前的分数除以天数,这样最后的指标就与视频播放的时间成正比了。
# Adding days since published into custom scoredef custom_score(viewcount, ratio, days_since_published): if ratio > 5: ratio = 5 score = (viewcount * ratio) / days_since_published return score通过对代码的进一步测试,我发现我总是能找到想看的好视频。对于公式的不同部分,我做了不同的改编和加权处理,但我发现这是一门不精确的科学,因此,我决定采用下面的公式,我发现这个公式既简单又有效:
$${videoValue }=\frac{{Views } * { min}({ViewToSubscriber Ratio,} 5)}{{Days} {SincePublished}}$$
测试新工具
首先,我使用查询词“medical school”进行测试。我得出了以下结果:
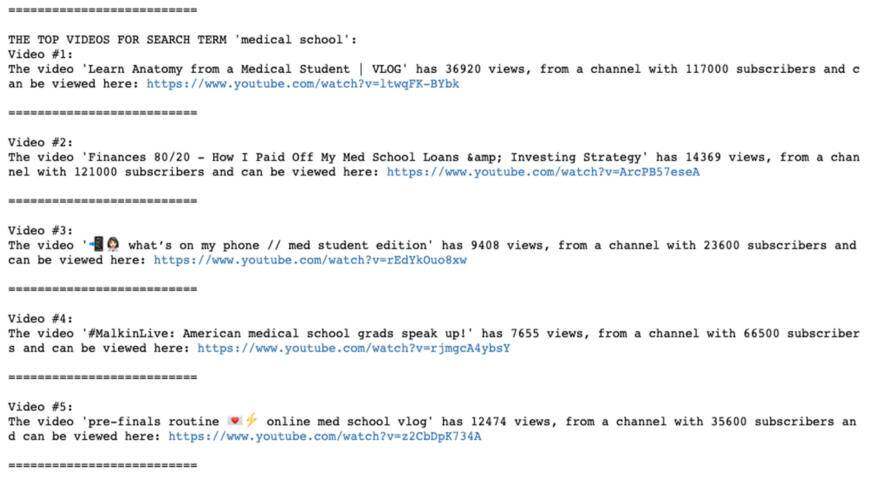
于是我就上了 YouTube,手动搜索与 medical school 相关的视频。我发现,我的工具已经捕捉到了所有我感兴趣的视频。尤其是 Kevin Jabbal 医生录制的第二个视频,非常受欢迎。
我用另一个搜索词“productivity”进行测试,结果再次令人满意:

第二个视频是一个略显无赖的视频:这并不是我所寻找的视频类型。但我实在想不出一个简单的方法来筛选出这些视频,这些视频之所以被选中是由于搜索词的另一种含义。
几个月前,OpenAI 分享了一个非常有趣的新神经网络,叫做“GPT-3”。我决定用 GPT-3 作为搜索词来测试我的视频搜索器,并找到了下面这个视频:

这是一个只有几千名订阅者的创作者发布的有趣视频。
如果我在 youtube.com 上做同样的搜索,我必须从所有大频道滚动查看关于 GPT-3 的视频,然后才能在第 31 个视频找到上面那个视频。
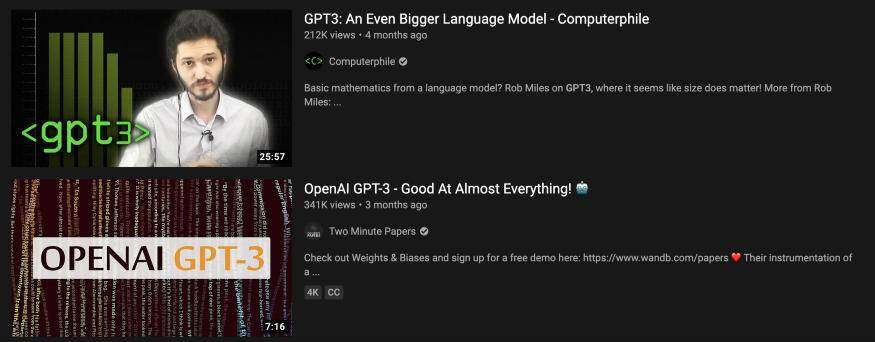
可见,使用我编写的视频搜索代码,找到这些有趣的、视角新颖的视频要容易得多。
在过去的几个月里,我根据自己的兴趣尝试了多个不同的搜索词,比如“artificial intelligence”、“medical AI”、“Python programming”。 在视频搜索器推荐的前五个视频中,几乎无一例外地至少有一个是有趣的视频。
设置工作流
我整理了所有代码,并上传到了 GitHub。
在较高的层次上,我的代码现在的工作方式如下:
使用搜索词、搜索时间段和 API 密钥从 YouTube 中提取视频信息;
解析出感兴趣的视频指标;
使用“价值函数”根据预测的兴趣对这些视频进行排名;
将相关的视频信息存储到 DataFrame 中;
将前五个视频的详细信息(包括链接)输出到控制台。
我想要一种自动运行这个脚本的方法,并决定使用 AWS Lambda (一种无服务器平台)。Lambda 允许你编写在触发前处于休眠状态的代码(例如,每周一次,或者基于某个事件)。
我最完美的工作流应该是每周用 Lambda 自动给自己发送视频列表的电子邮件。这样我就可以挑选出下一周想看的视频,而且我再也不用访问 YouTube 的主页了。
然而,这并没有奏效。
这是我第一次使用 Lambda,尽管我很努力,但就是无法让所有导入的库同时工作。为了执行,这段代码需要 boto3 邮件客户端、用于 API 调用的 OAuth、用于存储结果的 Pandas 和许多子依赖。通常情况下,安装这些包是相当简单的,但在 Lambda 上有额外的挑战。首先,上传是有内存限制的,所以我需要将库压缩,上传后再解压。第二,原来 AWS Lambda 使用的是定制的 Linux,这可能会使导入正确的、交叉兼容的库变得更加棘手。第三,我的 Mac 的虚拟环境表现得很奇怪。
在投入了大约 10~15 个小时在 StackOverFlow 上搜索,上传和重新上传不同的代码库,并咨询了几个朋友之后,我仍然无法让它运行。所以最终,让我沮丧的是,我决定放弃(如果你有什么好主意,请告诉我!)。
所以,我决定采取 B 计划 :我每周在本地计算机上手动运行一次脚本(在自动发送电子邮件提示后)。老实说,这不算世界末日。
最后的想法
总而言之,这是一个非常有趣的项目 。我学会了如何使用 YouTube API,熟悉了 AWS Lambda,并创建了一个可以继续使用的工具。
使用我的代码来决定观看哪些视频似乎确实提高了我的工作效率,只要我能够做到自律,不去点击太多的“接下来播放”链接。我可能会错过一些有趣的视频,但我的目标并不是全面捕捉所有值得观看的好视频(我认为这是不可能的)。 相反,我想提高我观看的视频质量的标准 。
这个项目只是我对自动化信息处理的众多想法之一。通过智能数字极简主义,我相信,我们有巨大的潜力来提高我们的生产力,并重新夺回我们的时间。
潜在的后续步骤
总的来说,这个项目仍然很粗糙,还有很多我可以做的事。
视频排名的指标相当粗糙,我可以进一步完善它。自然的下一步就是把喜欢 / 不喜欢的比率包含进去。
对搜索词也有很大的依赖性。如果文本不在标题或描述中,视频就不会被选中。我可以探索解决这个问题的方法。
我还可以构建一个界面,用户可以在其中输入搜索词和搜索时间段。这将使它更容易访问,也可以让用户不用登录 YouTube 就能观看视频。
目前,代码运行起来相当 man。由于我只计划每周运行一次,因此我并没有投入太多的精力去优化速度。但我可以改进一些明显的效率低下的地方。
其他有用的链接
类似项目:
YouTube API:
AWS Lambda:
作者介绍:
Chris Lovejoy,伦敦数据科学家、初级医生,毕业于剑桥大学医学院,致力于通过技术和教育改善医疗保健。
原文链接:




