
万物云上市当天,共有六人共同敲钟,其中一人为技术高管 — 万物云数据与技术中心算法负责人袁戟。这在一定程度上反映出,这家物业管理服务商希望带上更多的技术底色。近年来,物业管理行业越来越重视用 AI、大数据、云等技术赋能,智慧物业渐成发展趋势。
万物云正式登陆港交所,技术高管参与敲钟
9 月 29 日,万科集团分拆的物业管理服务商万物云于港交所上市。
据了解,万物云此次 IPO 吸引的基石投资人包括淡马锡、瑞银资管、中国诚通控股以及旗下的中国国有企业混合所有制改革基金、润晖投资、HHLR 基金及 YHG 投资、Athos 资本等。
招股书显示,万物云是一家物业管理服务提供商,建立了包括以下三大业务板块的业务模式:社区空间居住消费服务,商企和城市空间综合服务,AIoT 及 BPaaS 解决方案服务。根据弗若斯特沙利文的资料,按基础物业管理服务收入计,该公司于 2021 年在中国物业管理服务市场中排名第一,占有 4.28%的市场份额。
业绩方面,招股书显示,万物云 2019 年、2020 年、2021 年营收分别为 139.27 亿元、181.45 亿元、237 亿元。2022 年第一季度,万物云营收为 68.48 亿元,上年同期的营收为 47.48 亿元。
万物云董事长朱保全解释,万物云的定位与阿里云、华为云、腾讯云等以“云”命名的厂商不同,阿里云等做的都是底层的 IaaS,而非具体的云的运营。万物云不做IaaS层,反而会在这些云的基础上构建基于城市服务、工单管理的云服务。万物云有自身的独特之处,比如包含线下服务、人工运营、硬件施工能力等。不同于上述“云”的外包服务,万物云希望重点打造一个一体化的服务。
上市当天,万物云深圳战区前介专家杨鑫、万物梁行总部产品技术负责人兼超高层首席陈惠荣、科物业荔景大厦项目管家谢燕玉、万物云总部法务负责人袁嘉妮、万物云数据与技术中心算法负责人袁戟博士、万物为家首席合伙人周珂锐共同敲钟。
值得一提的是,作为敲钟人之一的袁戟曾在 InfoQ 今年 8 月举办的 QCon 全球软件开发大会广州站,担任《人工智能前沿应用》专题出品人,并在采访中分享了他对于算法模型的底层创新的观点。
据悉,万物云 DTC-机器智能产品部组建一年以来,在德国慕尼黑工业大学(Technische Universitaet Muenchen)博士袁戟的带领下以云端视觉、边端视觉以及运筹优化三个方向作为主要研究方向,开展算法研发工作,为万物云远程运营、智慧工地、城区巡航(无人机)、河道治理等其他应用和场景赋予 AI 能力,并通过智慧工单、保洁和运维的智能调度等算法实现 AI 能力的沉淀。本组共有成员 32 人,其中博士 1 人,硕士率超 50%,部分具有海外留学背景。近一年时间内,该团队结合公司业务实践和前沿算法,已录用论文 4 篇。
近日,袁戟博士带领的技术团队发表了一篇题为《基于深度学习的情感分析》的技术研究文章,以下为全文。本文作者是陈佳木、袁戟、吴远津。
对社区舆论的研究可以为物业管理提供有价值的信息。比如基于住这儿的论坛或者企业微信的聊天记录做情感分析可以帮助管理者更高效的了解用户意见,从而衍生出其他广泛的应用。然而,自然语言处理(NLP)遇到的挑战让情感分析的效率和准确性都受到了影响。
而深度学习模型是解决 NLP 问题的一个有前景的方案。本研究尝试基于物业服务的场景,用深度学习解决情感分析。在数据集上使用 term frequency-inverse document frequency (TF-IDF)和词嵌入( word embedding)模型,对不同模型的输入特征的实验结果进行比较。为了让普遍的读者更容易了解本研究,首先介绍下深度学习和情感分析。
基于深度学习的情感分析
深度学习(Deep learning)
深度学习采用多层方法处理神经网络的隐藏层。在传统的机器学习方法中,特征是手动定义和提取的,或者通过使用特征选择方法。而在深度学习模型中,特征是自动学习和提取的,实现了更好的准确性和性能。分类器模型的超参数也是自动测量的。下图显示了两种方法之间情感极性分类的差异:传统机器学习(支持向量机(SVM)、贝叶斯网络或决策树)和深度学习。

深度神经网络(Deep Neural Networks (DNN))
深度神经网络是具有两层以上的神经网络,其中部分是隐藏层。深度神经网络使用复杂的数学建模以多种不同的方式处理数据。神经网络是输出作为输入函数的可调模型,它由若干层组成:输入层,包括输入数据;隐藏层,包括称为神经元的处理节点;以及输出层,包括一个或多个神经元,其输出是网络输出。

卷积神经网络(Convolutional Neural Networks (CNN))
卷积神经网络是一种特殊类型的前馈神经网络,最初用于计算机视觉、推荐系统和自然语言处理等领域。它是基于深度神经网络架构,通常由卷积和池化层或子采样层组成,以向完全连接的分类层提供输入。卷积层过滤其输入以提取特征;可以组合多个滤波器的输出。合并或子采样层降低了特征的分辨率,这可以提高 CNN 对噪声和失真的鲁棒性。完全连接的层执行分类任务。
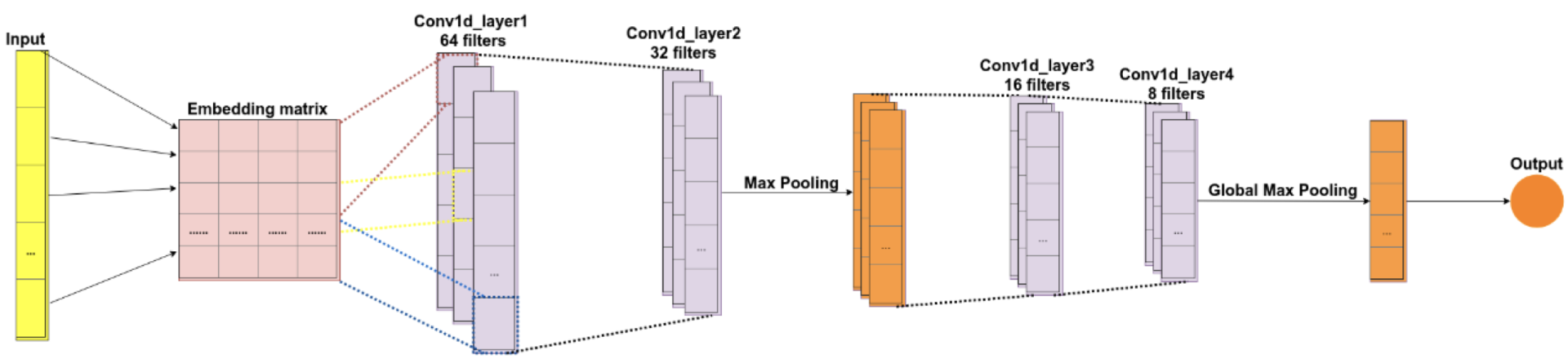
CNN 架构示例如下图所示。输入数据经过预处理,以重新形成嵌入矩阵。该图显示了由四个卷积层和两个最大池层处理的输入嵌入矩阵。前两个卷积层具有用于训练不同特征的 64 和 32 个滤波器;然后是最大池层,用于降低输出的复杂性并防止数据过度拟合。第三和第四卷积层分别具有 16 个和 8 个滤波器,其后面还跟随最大池层。最后一层是一个完全连接的层,将高度 8 的向量减少为输出向量 1,假设有两个类要预测(正、负)。
递归神经网络 (Recurrent Neural Networks (RNN))
递归神经网络(RNN)的神经元之间连接形成有向循环,从而在 RNN 内创建反馈回路。RNN 的主要功能是基于有向循环捕获的内部存储器处理顺序信息。与传统的神经网络不同,RNN 可以记住之前的信息计算,并可以通过将其应用于输入序列中的下一个元素来重用它。一种特殊类型的 RNN 是 LSTM,它能够使用长存储器作为隐藏层中激活函数的输入。
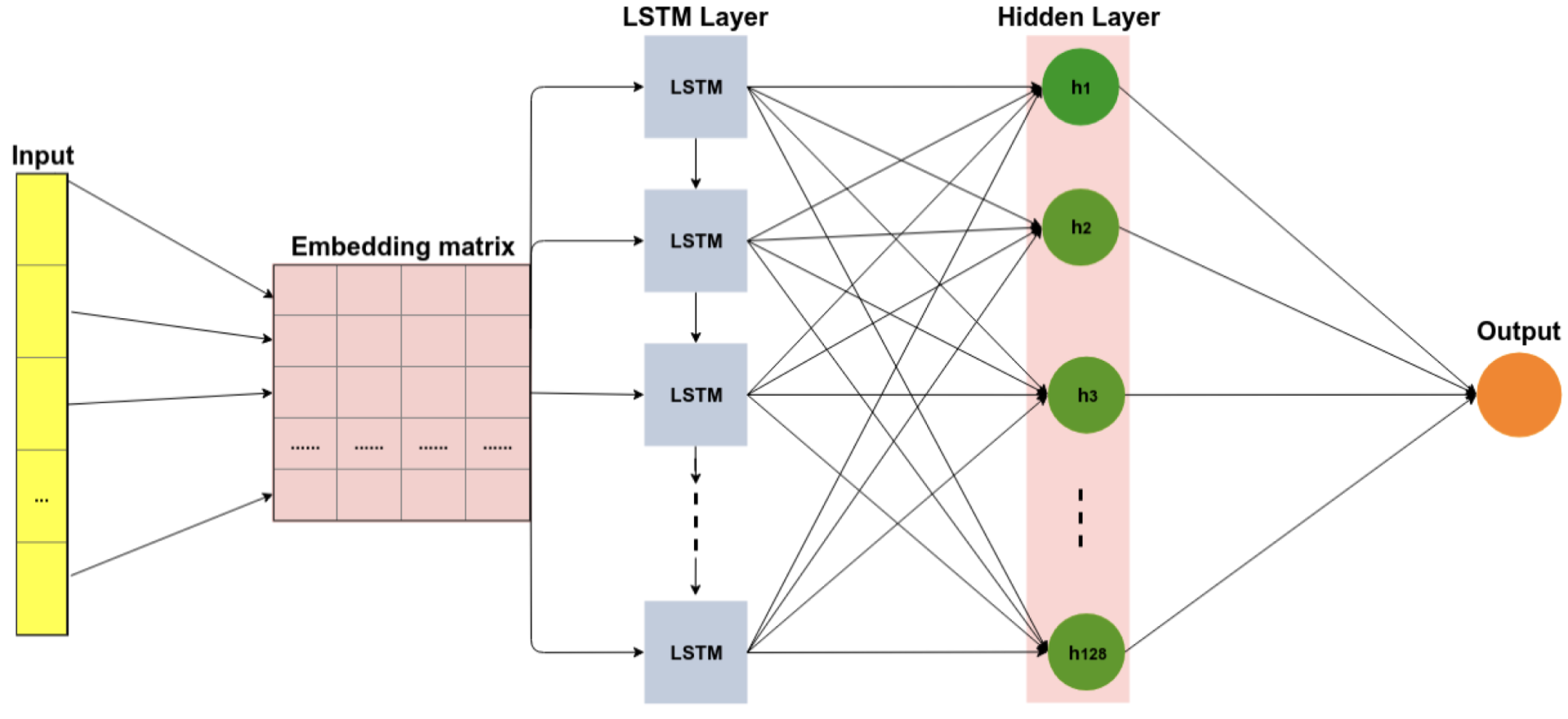
下图是 LSTM 架构。对输入数据进行预处理,以重塑嵌入矩阵的数据(该过程类似于 CNN 所述的过程)。下一层是 LSTM,包括 200 个单元。最后一层是完全连接的层,包括 128 个用于文本分类的单元。最后一层使用 sigmoid 激活函数将高度 128 的向量减少为 1 的输出向量,假设有两类要预测(正、负)。
情感分析 (Sentiment Analysis)
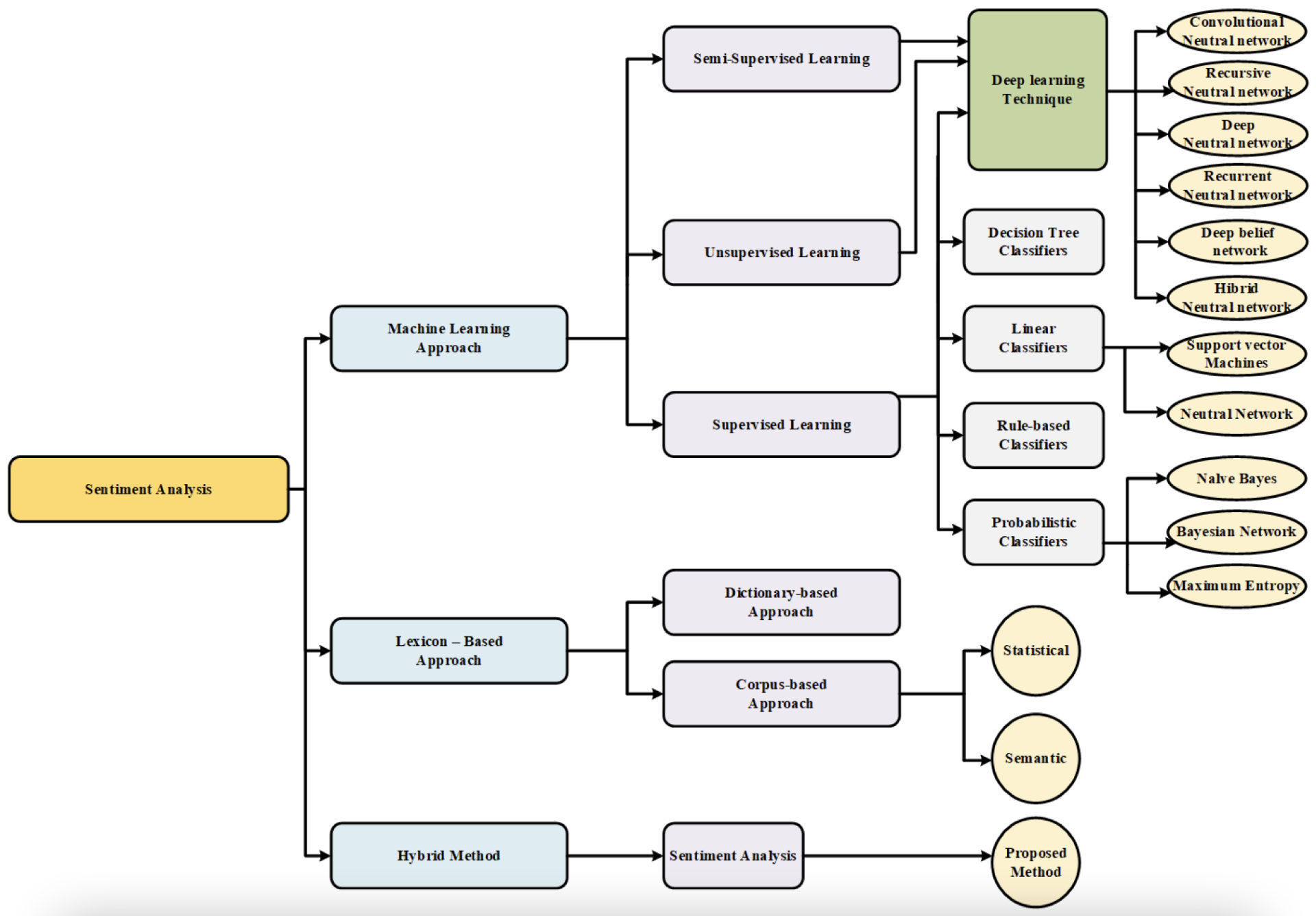
情感分析是提取实体信息并自动识别该实体的任何主观性的过程。目的是确定用户生成的文本是否传达了他们的正面、负面或中性意见。情感分类可以在三个提取级别上进行:方面或特征级别、句子级别和文档级别。目前,有三种方法来解决情感分析问题:基于词典的技术(Lexicon-based),基于机器学习的技术(Machine-learning-based),以及混合方法(The hybrid approaches)。
基于词典的技术首次用于情感分析。它们分为两种方法:基于词典的方法和基于语料库的方法。在前一种类型中,情感分类是通过使用术语词典来执行的,例如在 SentiWordNet 和 WordNet 中找到的术语。而基于语料库的情感分析是依赖于对文档集合内容的统计分析,使用基于 k 近邻(k-NN)、Conditional Random Field(CRF)和隐马尔可夫模型(HMM)等的技术。
针对情感分析基于机器学习的技术可分为两类:传统模型和深度学习模型。传统模型指的是经典的机器学习技术,如朴素贝叶斯分类器、最大熵分类器或支持向量机(SVM)。这些算法的输入包括词汇特征、基于情感词汇的特征、词类或形容词和副词。这些模型的精度取决于选择的特征。深度学习模型可以提供比传统模型更好的结果。不同类型的深度学习模型可用于情绪分析,包括 CNN、DNN 和 RNN。这种方法在文档级、句子级或方面级解决分类问题。
混合方法结合了基于词典和机器学习的方法。情感词汇通常在大多数策略中起着关键作用。下图说明了基于深度学习的情感分析方法的分类。
情感分析,无论是通过深度学习还是传统的机器学习进行,都需要在用于分类模型之前清理文本训练数据。企业微信文本通常包含空白、标点符号、非字符、转发、“@”和停止词。这些字符可以使用诸如 BeautifulSoup 之类的库删除,因为它们不包含任何对情感分析有用的信息。清理后,文本可以被分解为单个单词,通过词元化将其转换为基本形式,然后使用单词嵌入或术语频率逆文档频率(TF-IDF)等方法将其转换成数字向量。
词嵌入是一种用于语言建模和特征学习的技术,每个单词都映射到实值向量,使得具有相似含义的单词具有相似的表示。可以使用神经网络进行价值学习。一种常用的单词嵌入系统是 Word2vec(GloVe, 或 Gensim),它包含 skip-gram 和 continuous bag-of-words (CBOW)。这两种模型都是基于单词出现在彼此附近的概率。Skip gram 可以从一个单词开始,并预测可能围绕它的单词。Continuous bag-of-words 通过预测基于特定上下文词可能出现的词来逆转这种情况。
TF-IDF 是反映一个词对集合或语料库中的文档的重要性的统计度量。该度量考虑目标文档中单词的频率以及语料库中其他文档中的频率。目标文档中单词的频率越高,在其他文档中的频率越低,其重要性越大。Scikit-learn 库中的矢量器类通常用于计算 TF-IDF。
词嵌入和 TF-IDF 都被用作 NLP 中深度学习算法的输入特征。情感分析任务将原始数据集合转换为连续实数向量。
有不同类型的任务,如客观或主观分类、极性情绪检测和基于特征或方面的情感分析。单词和短语的主观性可能取决于其上下文,客观文档可能包含主观句子。基于 aspect level 的情感分析是指对实体的特定方面(例如,价值、房间、位置、清洁度或服务)表达的情感。极性和强度是情感分析评分的两个组成部分。极性表示情绪是消极的、中性的还是积极的。强度表示情感的相对强度。
数据集:

试验结果:

使用 Keras 和 Tensorflow 框架进行测试。在数据集上应用 DNN、CNN 和 RNN 模型进行实验,分析这些算法使用词嵌入和 TF-IDF 特征提取的性能。
在所有实验中,都为代码配置了参数,例如回声=5,批量大小=4096,k 倍=10。
使用准确度、AUC 和 F 分数评估所有实验评估模型性能。由于 F 分数来自召回率和准确率,因此还显示了这两个指标。
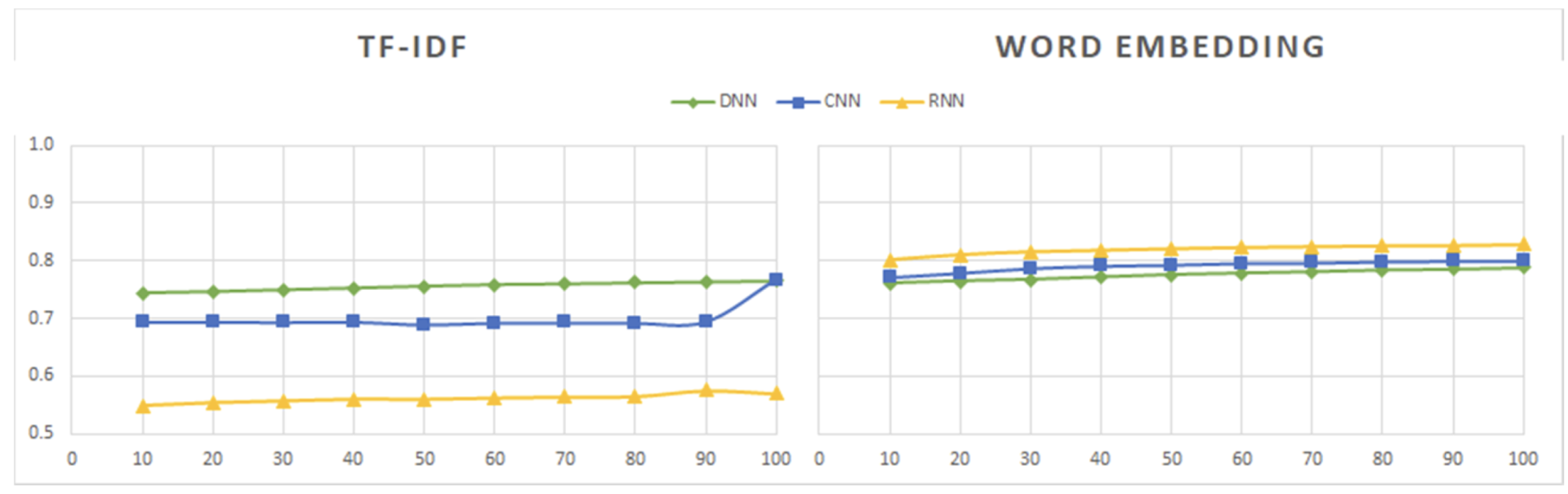
使用 TF-IDF 和单词嵌入的深度学习模型的准确度值:
使用 TF-IDF 和词嵌入 DNN、CNN 和 RNN 模型的 recall 值:
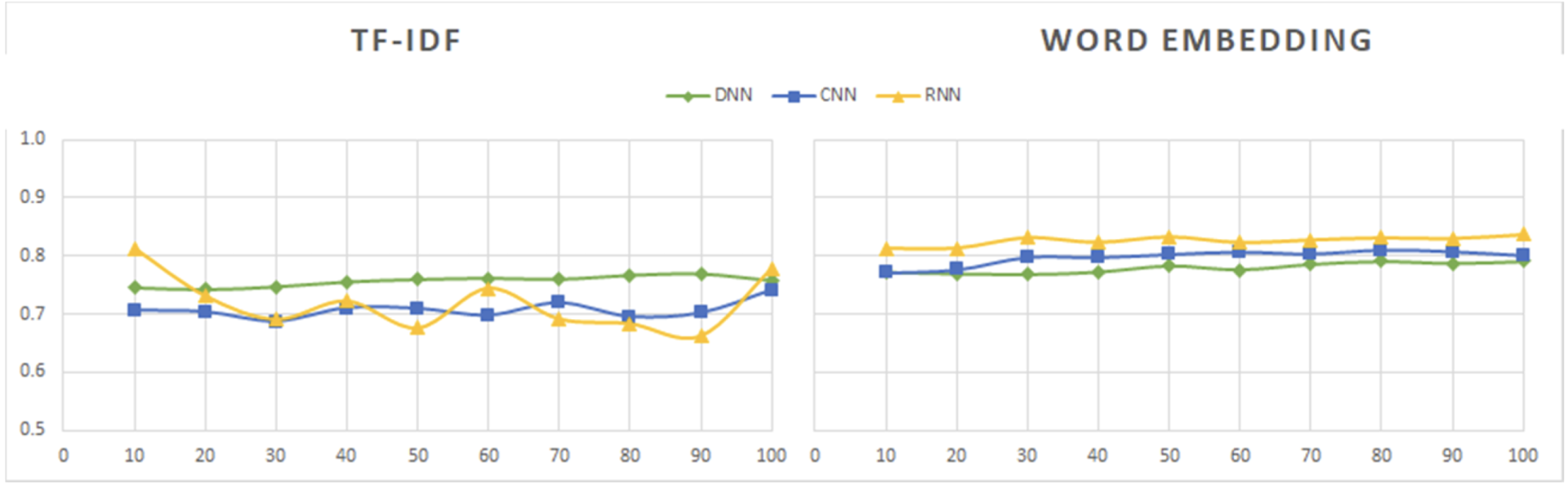
使用 TF-IDF 和词嵌入的 DNN、CNN 和 RNN 模型的精度值:
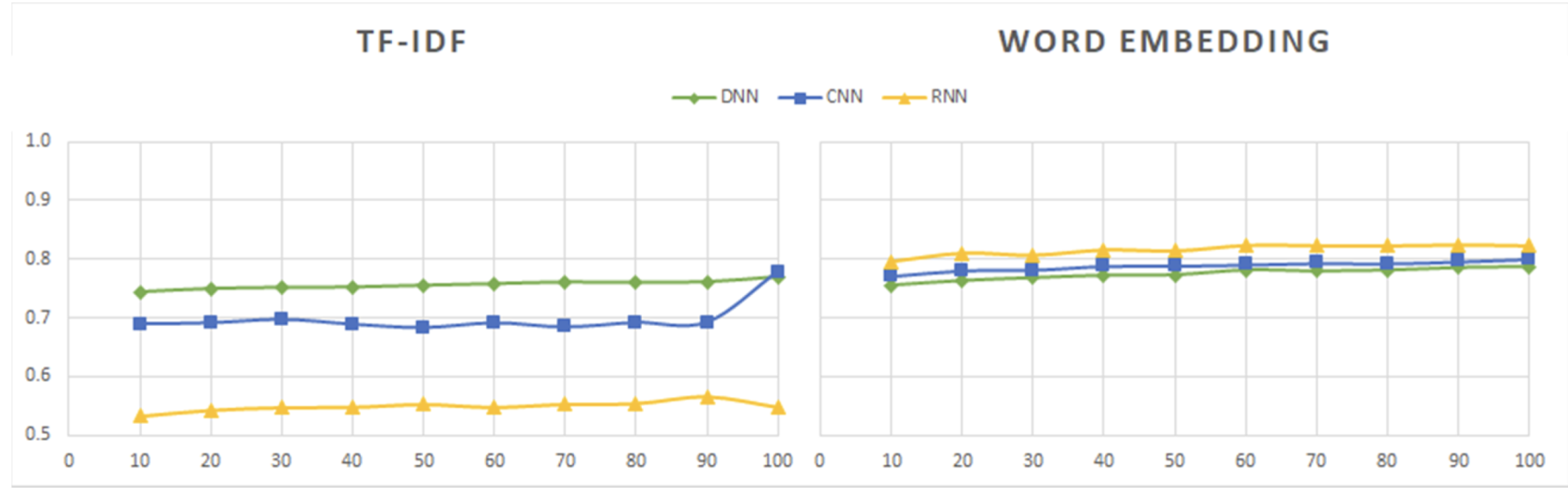
使用 TF-IDF 和词嵌入的 DNN、CNN 和 RNN 模型的 F 分数值:

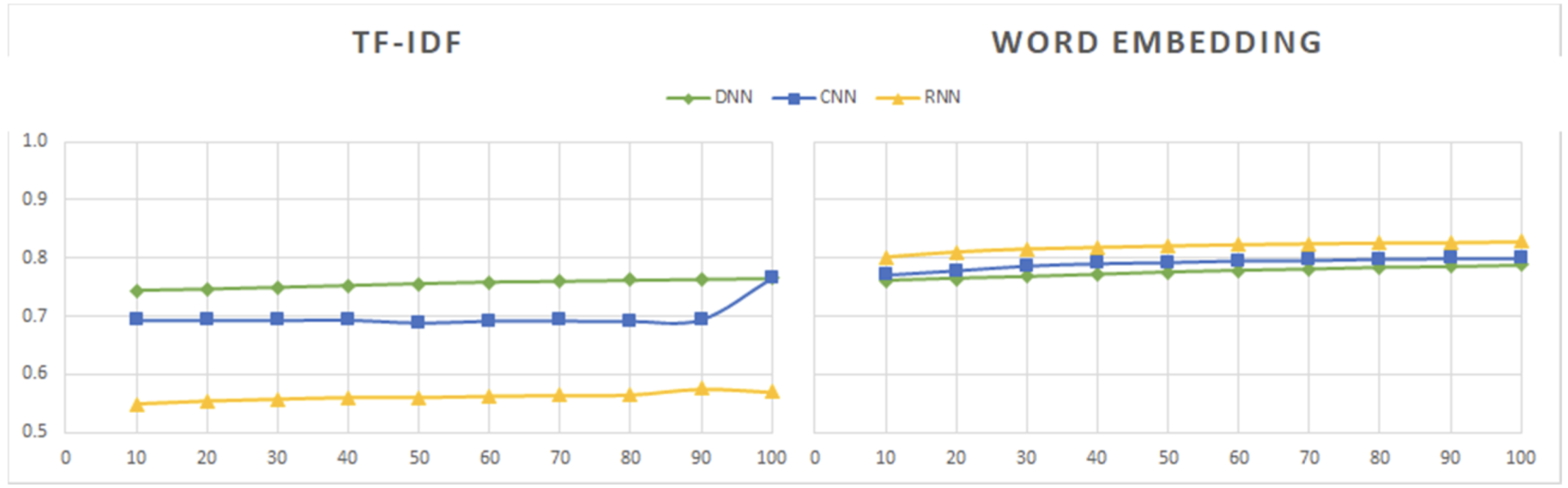
使用 TF-IDF 和词嵌入的 DNN、CNN 和 RNN 模型的 AUC 值:
使用 TF-IDF(左)和字嵌入(右)比较 RNN 的所有分数:

结论
使用词嵌入和 TF-IDF 进行情感分析。使用词嵌入和 TF-IDF 进行情感分析。对企微聊天记录的数据集进行了实验,以评估 DNN、CNN 和 RNN 模型。这些信息,结合实验结果,为我们提供了将深度学习模型应用于情感分析以及将这些模型与文本预处理技术相结合的广阔前景。
通过分析,DNN、CNN 和混合方法是情感极性分析最广泛使用的模型。另一个结论是,在这些研究中,CNN、RNN 和 LSTM 等常用技术在不同数据集上进行了单独测试,但缺乏对它们的比较分析。此外,大多数论文中给出的结果是在可靠性方面给出的,没有考虑计算时间。
通过研究不同类型的数据集、特征提取技术和深度学习模型的影响,特别关注情绪极性分析问题。结果表明,在进行情感分析时,深度学习技术与单词嵌入相结合比 TF-IDF 更好。实验还表明,CNN 优于其他模型,在准确性和 CPU 运行时间之间提供了良好的平衡。对于大多数数据集,RNN 可靠性略高于 CNN 可靠性,但其计算时间要长得多。研究得出的最后一个结论是,算法的有效性在很大程度上取决于数据集的特征,因此,为了覆盖更大的特征多样性,可以方便地使用更多的数据集测试深度学习方法。
基于此研究为基础,我们将重点探索混合方法,利用多个模型和技术相结合,以提高单个模型或技术实现的情感分类精度,并降低计算成本。扩大比较研究,包括新方法和新类型的数据。并将使用几种类型的数据评估混合模型的可靠性和处理时间。如状态、评论和帖子等的内容。还计划解决 aspect 情绪分析的问题,以便通过将用户情感与特定功能或主题相关联来更深入地了解用户。这对像我们这样提供服务的公司来说非常重要,因为从用户那里获得详细的反馈,从而知道其服务或产品的哪些方面应该改进,是提升我们服务质量和满意度的高效方法之一。




