
自 2021 年初以来,随着大量深度学习支持的文本到图像模型(例如DALL-E-2、Stable Diffusion和Midjourney等)的诞生,人工智能研究的进展发生了革命性的变化。
近日,谷歌Muse AI 系统正式亮相。据谷歌 Muse AI 团队称,Muse 是一种文本到图像的 Transformer 模型,该模型可以实现先进的图像生成性能。
我们提出 Muse,一种文本到图像的 Transformer 模型,可实现先进的图像生成性能,同时比扩散或自回归模型更有效。
——谷歌 Muse AI 团队
据开发团队介绍,与 Imagen 和 DALL-E 2 等像素空间扩散模型相比,Muse 由于使用离散标记并且需要更少的采样迭代,因此效率显着提高;与 Parti 和其他自回归模型不同,Muse 利用了并行解码。 为了生成高质量的图像并识别物体、它们的空间关系、姿态、基数等视觉概念,使用预训练的 LLM 可以实现细粒度的语言理解。Muse 还可以直接启用许多图像编辑应用程序,而无需微调或反转模型:修复、修复和无蒙版编辑。
Muse 的 900M 参数模型在 CC3M 上实现了新的 SOTA,FID 得分为 6.06。Muse 3B 参数模型在零样本 COCO 评估中实现了 7.88 的 FID,以及 0.32 的 CLIP 分数。Muse 还可以直接启用许多图像编辑应用程序,而无需微调或反转模型:修复、修复和无蒙版编辑。
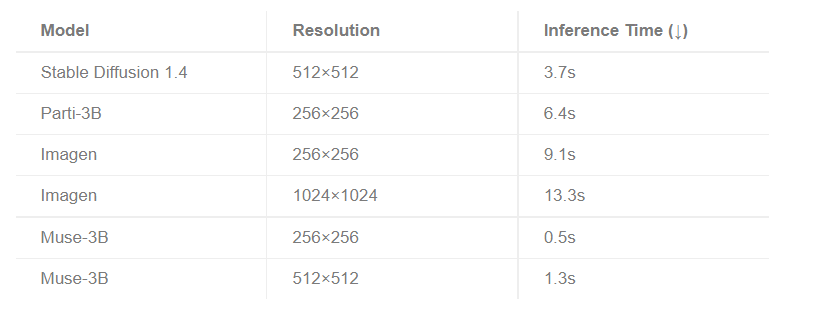
Muse 模型能够根据文本提示快速生成高质量图像:在 TPUv4 上,512x512 分辨率为 1.3 秒,256x256 分辨率为 0.5 秒。
根据 MUSE 的基准测试可以看出,Muse 的推理时间明显低于竞争模型。
参考链接:
https://dataconomy.com/2023/01/google-muse-ai-explained-how-does-it-work/




