
欢迎阅读新一期的数据库内核杂谈。再次和大家道歉,拖更太久了,工作忙,然后出差,然后就阳了,恢复花了好久时间。一言难尽的 2022 年结束了,希望 2023 年能够善待我们(虽然,2022 年初的时候,我也这么说)。数据湖(data lake)这个概念提出已经有了一段时间,各个大数据公司,或者技术厂商都有推出过自家的数据湖产品,比如 DataBricks 的 Delta Lake,Uber 开源的 Apache Hudi 以及 Netflix 开源的 Apache Iceberg。一直想写一篇关于数据湖的文章。但,总觉得自己的理解和思考不深,可以学习和阅读的材料也不多。前阵子,读了不少博客,也阅读了 Databricks 关于数据湖的技术论文:Delta Lake:High-Performance ACID Table Storage over Cloud Object Stores。这一期,我们尝试着来聊一下数据湖。
为什么需要数据湖?
第一个问题依然是 Why。为什么需要数据湖?数据湖要真正解决的问题是什么?我自己的理解就是,一套数据系统解决在线和离线数据统一查询的问题。
我们都知道, hdfs, hadoop 系统,让处理海量数据成为可能。但数据主要是以离线的形式呈现:批量导入数据,且历史数据不会被改动,新数据会周期性地新增(比如,按天级)。而这种形式带来的问题也显而易见,就是,不支持对及时更新的数据的查询。当然,我们也需要辩证地去思考这个问题。业务逻辑是否需要最新的数据。对于一些离线的报表,统计业务,T+1 的延时已经完全能满足要求(在很多情况下,我也会和团队的同学去讨论,我们的业务是否需要小时级别的数据同步,往往答案是否定的)。
在数据湖之前,其他系统是如何解决这个问题的。答案就是 Lambda 架构和 Kappa 架构。
Lambda 架构介绍
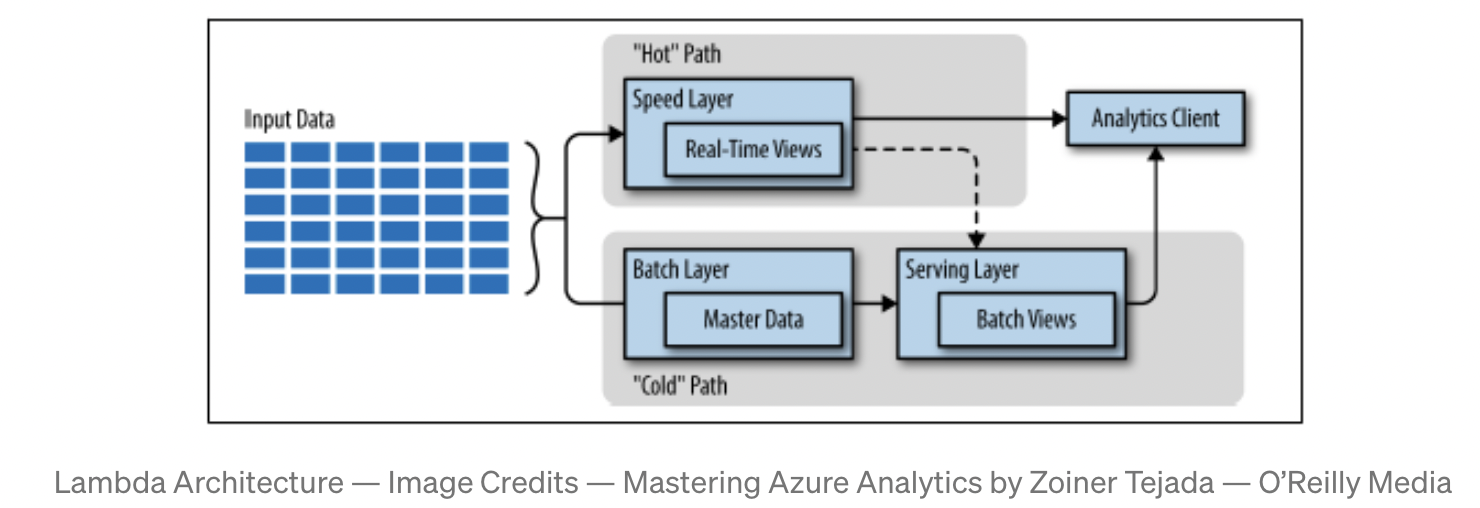
Lambda 架构最早被提出是 Nathan Mars 发表于 2013 年的一篇博客,名为"How to beat the CAP theorem",在文中 Lambda 架构被指为"离线(batch)和在线(realtime)架构的结合:Lambda 架构是一个数据处理和服务架构,通过协同并利用好离线和实时处理子系统来处理海量数据。Lambda 架构通过使用离线子系统来计算出完整正确的离线数据,使用实时子系统来处理在线数据,并结合两者的结果,以此来平衡返回延时,吞吐量,以及容错率。Lambda 架构的出现旨在通过实时数据处理解决大数据系统中 MapReduce 的延迟较高的问题。
离线计算引擎(Batch Layer)
离线计算引擎通常使用大规模计算引擎,离线处理并计算好结果(precompute)。离线计算引擎的好处在于,对于结果不追求时效性,比如 T+1 事件计算好即可。但同时由于计算的时候,离线计算引擎可以读取某个时间点(snapshot)内的所有数据,因此数据的准确性有保障(理论上是 100%正确)。计算的结果通常会写到一个只读(read-only)的数据库里面。如果需要更新,也是完全覆盖旧的结果。
2014 年,开源的 Hadoop(hdfs/mapreduce)被认为是一个具有代表性且应用广泛的离线计算引擎。这之后,一些其他的数据库系统比如 Snowflake,Redshift,或者 Big Query 也被广泛使用。
实时处理引擎(Speed Layer)
实时处理引擎,通常使用流式计算来处理数据,并不强求数据的完整性和正确性。它通过流式引擎来处理最实时的数据,以牺牲整体数据吞吐量的方式来进一步减少实时数据查询的延时。实时处理引擎是用来弥补离线引擎对于新数据的缺失。从数据正确性上来看,实时引擎不可能比肩离线引擎,但从时效性上来看,实时引擎几乎可以在读取到最新数据的同时(秒甚至毫秒级别)给出查询结果。
常见的实时处理引擎有 Amazon Kinesis,Apache Storm,Apache Samza,Apache Spark Streaming 等。
服务层(Serving Layer)
服务层通常存储了离线和实时处理引擎处理后的数据结果,然后根据查询请求来决定是否直接返回离线结果,或者直接返回在线结果还是需要结合离线和实时数据,行程一个 joint view,然后再返回。
下图给出了 Lambda 架构示例:
Kappa 架构
介绍完了 Lambda 架构,不知道大家是否发现了 Lambda 架构不好,或者说不优雅的地方。我引用一下 Jay Kreps 在 2014 年的一篇博客"Questioning the Lambda Architecture"中的一句话"The problem with the Lambda Architecture is that maintaining code that needs to produce the same result in two complex distributed systemsis painful and easily get wrong. "。翻译过来就是指,离线引擎和在线引擎对于数据处理的逻辑是一致的,但 Lambda 架构需要维护两套代码在不同的引擎上(由于技术栈的不同)。
也因此,Jay 在博客中提出了 Kappa 架构。Kappa 架构的主旨就是,既然在线处理引擎已经要做一次数据处理,是否可以提升在线引擎的吞吐量,把离线的任务也都交给它。下图给出了 Kaapa 架构的示意图:
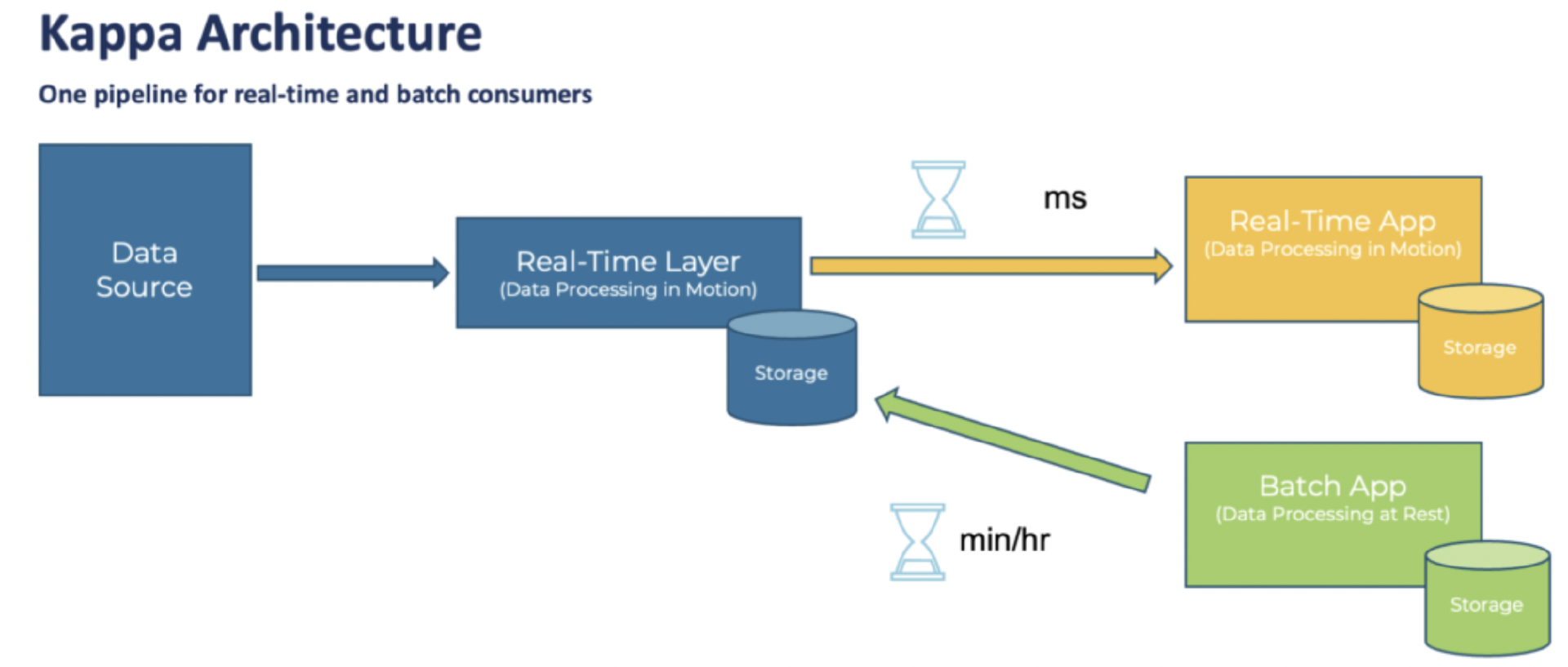
只用在线引擎来做数据处理,对于离线 request,可以做好预处理存储起来,直接返回结果(可以利用 hdfs 来存储预处理的结果,但只作为 serving layer),也可以重新 feed 原始的数据流来到在线引擎来支持新的计算。
说一些我个人的理解,Kappa 主打一套系统 rule them all。但在线处理引擎,或者流式处理系统相对于离线系统还是有局限性的,比如功能不完善,特别是做一些需要复杂 join 的情形。第二,重新 feed 原始数据流来做计算并不是一个高效的实现方式。现实系统的演进也说明了问题,如果 Kappa 真的 fit 所有的用例,那也不会持续有新的 NewSql,或者数据湖这类技术的持续改进。
稍微总结一下, Lambda 架构,是用两套系统来解决这个问题;Kappa 架构是希望用流式系统解决,但并没有很好地解决这个问题。那数据湖又是如何去解决数据统一的问题呢?咱们围绕 Delta lake 这篇论文来讨论。
使用对象存储作为存储介质
Delta lake 文中讨论的第一个观点就是,使用对象存储(比如 S3,Ceph)作为存储介质。Hadoop 或者 Spark 的存储系统一般都是 HDFS。通常情况下,HDFS 和 Hadoop 或者 Spark 是部署在相同的计算节点上的。因为 HDFS 重存储,而 MapReduce 或者 Spark 重计算(memory, CPU)。部署在一起的好处是,可以最大化地利用 data locality 来做移动计算。
而数据湖架构,推荐使用对象存储作为存储介质。 原因如下:1)更贴近云原生。云厂商通常提供了超大规模,稳定,且性价比很高的对象存储服务。2)统一了结构化和非结构化的存储,非结构化的数据本来就会使用对象存储。3)更好地支持存算分离。 数据存储完全交给对象存储,计算就可以通过弹性资源来更好地 scale,同时,也更符合云原生的概念。
当然对象存储也面临一些问题。文中也梳理了一下:1)对象存储通常提供了 key-value 形式的 access pattern,但不具备文件系统的很多功能。虽然 key 的命名可以去匹配 directory 的命名法则,且大部分的对象存储也支持 list 操作,但这些文件并不是物理存储在一个文件夹下,导致 list 操作并不是很高效(通常需要十几到几百毫秒),甚至有 return 数的限制(S3 的 list 操作限制 return 1000 个 key)。2)并不是强一致性:这也是对象存储性质决定的。当有新文件被创建时,list 操作并不能保证会返回这个新文件。
文章在介绍 Delta lake 技术方案之前,讨论了现有数据系统是如何基于对象存储做数据存储。
directories of files
这个方法和使用 hdfs 存储数据完全一致,数据以文件和文件夹的形式存在,只是将介质换到了对象存储。文件夹的构造通过通过命名规则来实现。比如
namespace1/table1/partition1/1.data
namespace1/table1/partition1/2.data
namespace1/table1/partition2/1.data
...
这种方法的优势在于,实现非常简单,所有的信息都存储在对象存储上。数据引擎可以以很小的代价从支持 hdfs 读取到支持对象存储读取。并且,其他数据工具,在不需要额外工作的情况下(只要知道存储命名规则),也可以读写数据。劣势依然逃不开性能和一致性的问题。
custom storage engines(自研元数据管理中心)
另一种方法(文中介绍了 Snowflake),就是使用对象存储来存储数据文件,但通过自研的元数据管理中心来管理数据文件到表,namespace 的映射。我个人其实是比较倾向这种设计的,用正确的技术做正确的事嘛。文中也提到了这类方法的挑战。1)需要额外的研发资源来建造这个元数据管理中心,2)所有对数据的读写都需要和这个元数据中心做交互,使得这个元数据中心要做到高性能,强一致,且始终在线。这是一个不小的挑战。3)source of truth 都存储在这个元数据中心里,使得这个数据系统相对而言更闭源,其他数据系统接入的成本也会更高。
Delta lake 存储格式介绍
比较了上述两种管理方式,来看 Delta lake 是如何实现对数据的管理。原理也挺容易想到的,就是对现有两种方法的结合:除了存储数据文件,也将数据的变更操作(log)存储在对象存储中。下图给出了示意:

除了数据文件,每个表会有一个单独的_delta_log 的子目录,里面会记录数据变更的操作(虽然 Apache Iceberg 不在本文的介绍中,但我读过相关的 blog 以及 Apache Iceberg 的 spec,方法是类似的)。
log 文件夹下存储着序列号递增的 log 文件,顺序记录着数据管理的操作。在某些情况下,也会有 checkpoint 的 log 文件存在(这些 checkpoint log 文件以 parquet format 存储,相当于 snapshot,用来合并前面 log 的操作来提升读取性能)。每个 log 文件,记录着从上一个版本的数据,到这个版本的数据要做哪些操作。常见的操作有:
元数据改变(change metadata): 比如 schema 改变,或者 partition column 改变。
数据文件改变(Add or Remove files):记录着对于一个表数据,有新的数据文件生成,或者旧的数据文件删除。
协议改变(protocol evolution):主要用于明示系统目前使用的是哪个版本的 Delta table protocol。
文中也介绍了一些关于 log 读取的优化操作,除了已经介绍过的 checkpoint 文件,在 log 里也会存储一个_last_checkpoint 的文件用来告诉系统最新的 checkpoint 的 version 是哪一个,方便快速读取而不用 list 所有的 log 文件后再做判断。
介绍了 log 的存储格式,再来看如何支持数据读写操作。这边以读取最新版本的数据为例。
读取_last_checkpoint(如果存在的话),找到最新的 checkpoint 的版本号。
以这个版本号为 start-key(如果没有,就是 0),读取大于这个版本号的 json-log 或者 checkpoint parquet 文件(这边为什么还需要读取 checkpoint,主要原因也是因为系统没有强一致保障,不能保证_last_checkpoint 里存储的就是最新的 checkpoint)。
用最新的 checkpoint 文件加上后续的 log 文件来获得当前数据表的最新元数据,包括 schema 信息,数据文件信息,statistics 等等。
根据上面获得的信息,结合 query,读取相应的数据文件。
写操作则如下:
获取数据表最新的元数据信息,这个操作和读操作里面的 1,2,3 步一致。
如果是数据更新操作,将新的数据文件写到 data folder 里面。
假如目前版本是 n,尝试创建 n+1.json,并将元数据改变的操作写入这个文件。
判断是否需要创建一个新的 checkpoint log(目前的判断逻辑是每 10 个版本创建一个 checkpoint),如果需要,将最新的元数据信息写入 checkpoint,并更新_last_checkpoint 文件。
细心的读者会发现写操作的第三步,创建 n+1.json 需要原子操作,但并不是所有的对象存储都支持原子操作。文中介绍了,Google Cloud Storage 和 Azure Blob Store 都支持原子的 put-if-abscent 操作,因此可以直接使用,但如果是 AWS S3,需要配合 DataBricks 的轻量级的 coordination service 来保证原子操作。
介绍完了实现,文中也梳理了一些 Delta lake 的属性:
TPS 支持:考虑到对象存储的写入性能,可以预料其实 transaction per second (TPS)不会特别高,可能也就是每秒个位数的 transaction 级别。文中也写到了可以通过 batch 操作来减少 TPS,并表示,目前的 TPS 可以满足绝大部分 usecase 的需求。
支持 time travel query 和 rollbacks: 由于保留了全部的 log 记录,Delta lake 的表可以很好地支持 time travel 查询和 rollback 操作。
支持 update, delete, merge 等数据操作:理由同上。
Schema evolution and enforcement 支持:理由同上。
总结
本期内容,结合 DataBricks 发表的介绍他们数据湖产品 Delta Lake 的论文,我们讨论了为什么需要数据湖架构,并学习了 Delta Lake 的数据湖的一些细节。说一些我自己不成熟的想法:数据湖相比原先的 Lambda 架构,通过 log 手段加入了对数据更新的支持,希望通过一套数据管理系统支持所有业务。但从目前的实现来看,实现上还是有很多限制,对于实时性非常高的应用场景,数据湖并不能满足。感谢阅读!
相关阅读:
数据库内核杂谈 (二十二) 自动驾驶数据库 - Behavior Modeling
数据库内核杂谈(二十三)- Hologres,支持 Hybrid serving/analytical Processing 的数据引擎
数据库内核杂谈(二十四)- Hologres,支持 Hybrid serving/analytical Processing 的数据引擎




