
本文来自火山引擎视频云的技术实践分享
RTC 是一个“发布-订阅”系统,我们在发布端和订阅端做的很多关于画质、性能、卡顿、延时的优化,在经过网络传输之后,不一定能够达到端到端的最优效果。本文介绍 RTC 如何通过发布端和接收端的联动优化,为用户提供更佳的视频通话体验。
传统 RTC 上下行联动优化技术——带宽探测
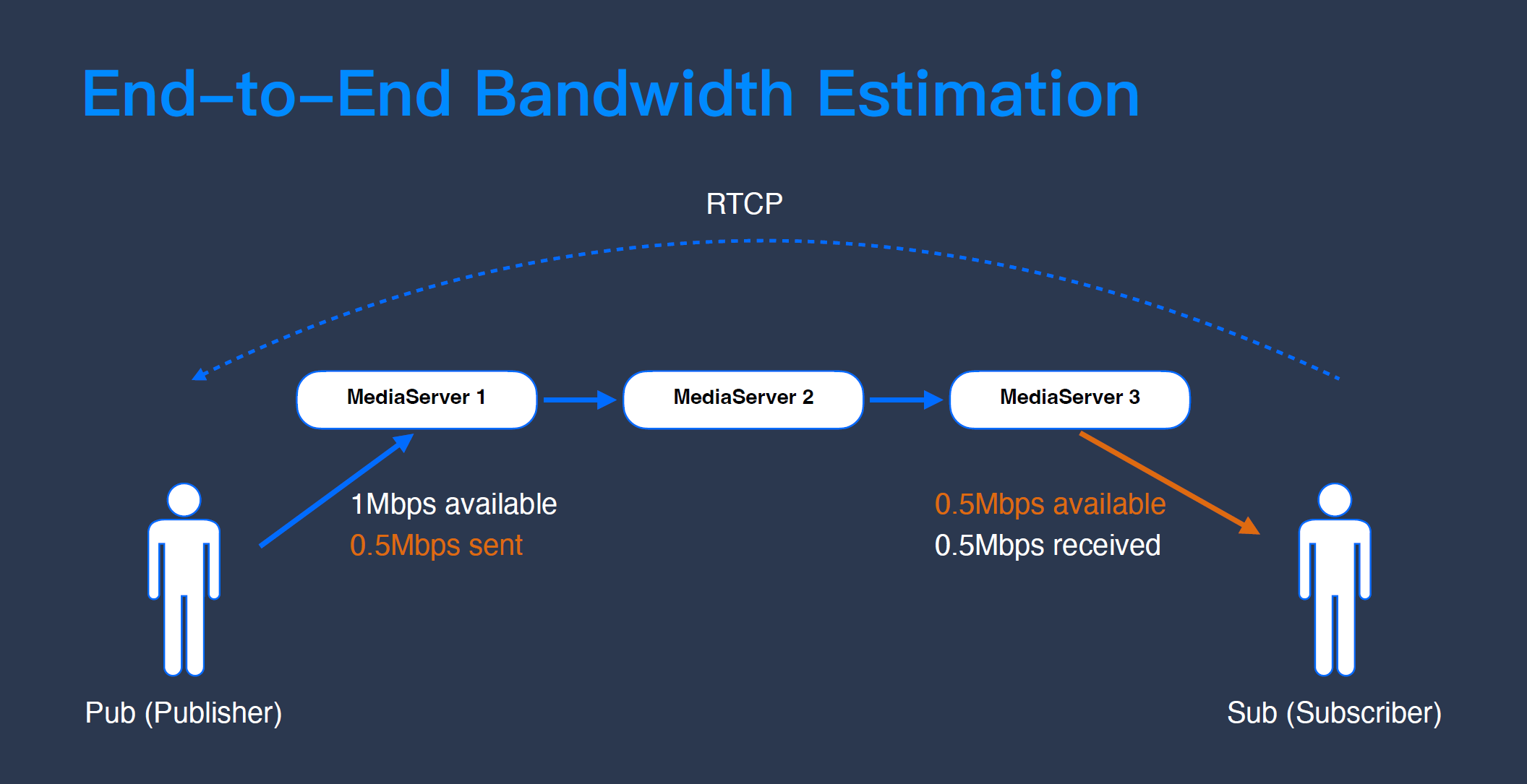
这是一个多人 RTC 系统的示意图,左边是发布端 Pub(Publisher),右边是接收端 Sub(Subscriber),把视频流从发布端通过一连串的媒体级联服务器送到接收端,就是“发布——接收”的整体链路。在这条链路上,我们可以有效利用一些信息来帮助 RTC 系统做端到端优化,比如把接收端的信息送回发布端做优化。
上图是一个比较常见的端到端优化的例子——上下行带宽联动探测。发布端上行带宽有 1 Mbps,接收端下行带宽只有 0.5 Mbps,如果发布端和接收端不做“沟通”,发布端就会按照它的带宽探测 1 Mbps 发流,造成的结果就是下行带宽不够了,接收端收不了,延时不断增加,当增加到一定程度的时候,Buffer 清空重新发 I 帧造成大卡顿,用户的感受就是突然一个画面闪过去,中间一段内容都看不到了。
当前市面上 99% 的 RTC 厂商都是基于 WebRTC 来开发自己的 RTC 系统,WebRTC 系统支持 RTCP(RTP 的传输控制协议,专门用来传输控制信号),通过 RTCP 协议,我们可以把接收端探测到的网络状况,包括接收端网络的抖动信息、延时信息等回传给发送端,让发送端知道现在接收端的网络状况怎么样。由于 WebRTC 是一个点对点的系统,既然可以通过媒体级联服务器传递音视频数据,也能够使用同样的链路传递其他信息。通过 RTCP 传回的接收端带宽信息,发布端就会“知道”虽然自己有 1 Mbps 的带宽,但考虑到接收端的情况,用 0.5 Mbps 来发流更合理。
以上是最常见的一个「上下行带宽联动应用」的例子。
真·端到端上下行联动优化实践
RTC 系统中的这些“通道”以及通过这些通道传递的“信息”可以被应用来做一些上下行的联动优化,解决一些 RTC 深水区的问题。由于不同应用会使用不同的“信息”和不同的“通道”,我们先归纳一下发布端和接收端的特点,看看哪些是发布端有、接收端没有的,或者哪些是接收端有、发布端没有的“独有信息”。
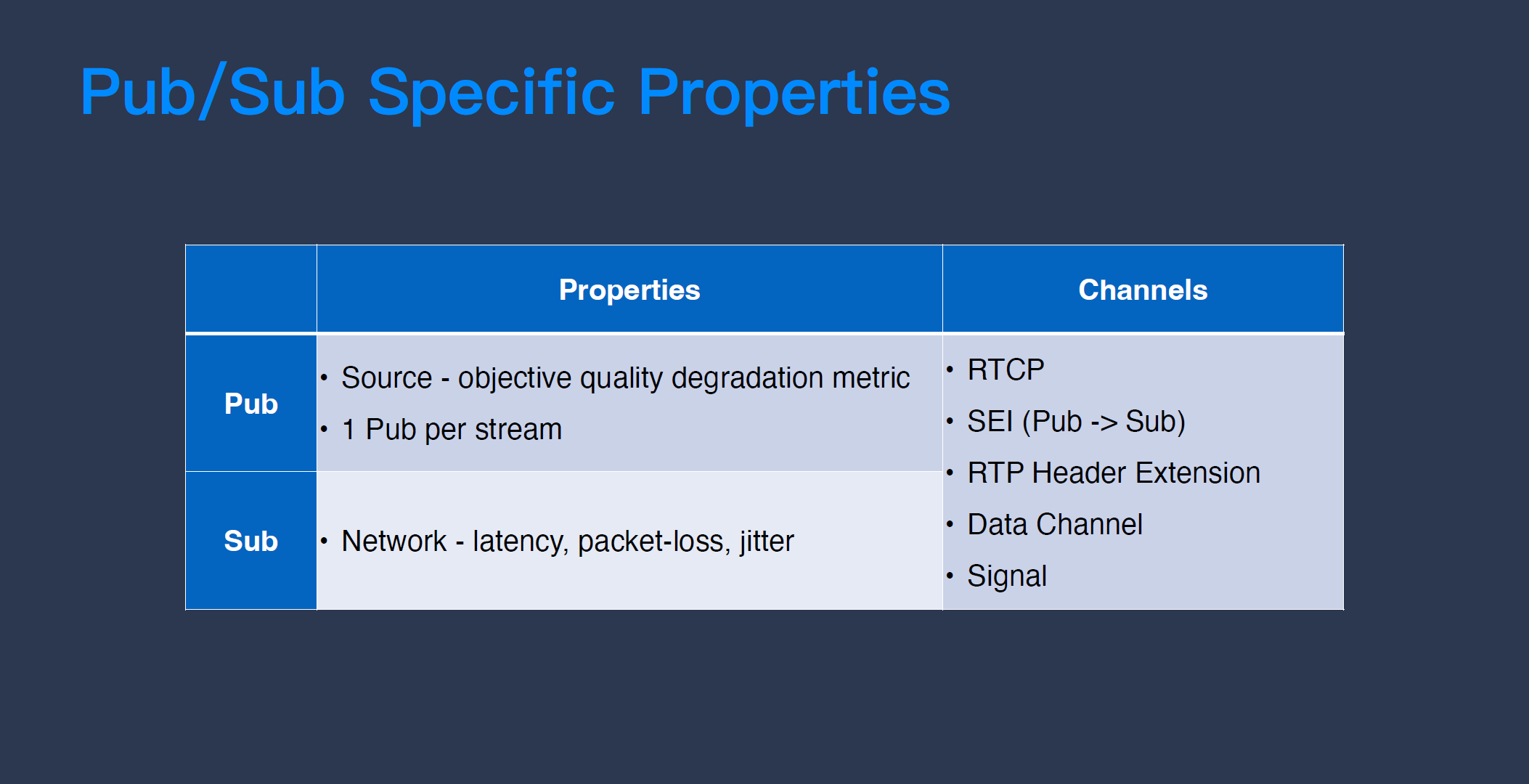
先看发布端。发布端的特点之一是它有“视频源”,即采集或美颜后未受压缩损坏的视频源。RTC 系统中间是网络传输,网络传输的时候不可避免会碰到一些带宽波动,比如弱网、丢包、抖动等情况,为了确保把内容传输出去,发布端势必要做压缩,有压缩就会有损伤,所以接收端永远拿不到损伤前的“源”,只有在发布端才有“源”。如果我们要做质量评估,想知道 RTC 里画质好不好,只有在发布端做才更准确——因为只有在有“源”的情况下,我们才能客观评价接收到的内容跟“源”有多少差距。
发布端还有一个特点,就是 1 条流只有 1 个发布端,但可能有多个接收端。如果我们需要在 RTC 系统里做 1 个任务,特别是在多人通话场景下,一定会选择在发布端做,因为只要做 1 次就够了。比如在下文「智能场景识别/内容识别」的例子中,我们需要做一些视频内容的分析识别任务,假设 1 条流有 10 个接收端,如果在接收端做识别就需要做 10 遍重复的事,不如在发布端做 1 次识别,然后把这个信息传递给接收端来得高效。
接收端的特点是它能拿到所有网络相关的信息,常见的有丢包、抖动、延时等状态信息,它还“知道”收到了哪些帧,丢了哪些帧,而发布端只“知道”它发出了哪些帧。
说完了发布端和接收端的特点,我们再来看看有哪些“通道”可以传输这些信息。
上文中已提到,WebRTC 已经可以实现利用标准的“沟通”通道 RTCP 把接收端的网络状态信息回传给发布端。视频的压缩码流标准定义了一个叫 SEI 的 协议,SEI 里面可以带一些 meta data,可以通过它来携带一些个性化的内容信息。SEI 的好处是它可以做到“帧”级别的对齐,RTCP 无法保证什么时候到达,无法精准地控制在某一视频帧做什么事情,但是 SEI 可以,SEI 的劣势是它只能“单向沟通”,只能从“发布端”传到“接收端”。
同样方向的流还有 RTP,RTP 是 WebRTC 的标准传输协议,它提供扩展头(Header Extension)功能,我们可以自定义地去扩展一些头部,在 RTP 数据包头中附加一些需要的信息传输。以上 RTCP、SEI、RTP 走的都是 UDP 协议,所以它们有可能会丢。
RTC 系统里也有一些“不会丢”的沟通通道,比如 data channel(它在 UDP 协议里做了一些可靠传输机制),还有基于 TCP 传输的信令,这两个都不会丢。不过,“不会丢”并不表示它就是好的,一般来说,“不会丢”表示丢了以后会重传,所以相对来说比较慢。
有了这些总结归纳后,下面通过三个故事来介绍我们如何使用这些信息和通道来做上下行联动优化,解决弱网、丢包、4K 屏幕分享卡顿等问题。这三个小故事的基本叙事逻辑是一致的——走的是什么通道?传的是什么信息?解决的是什么问题?
超分辨率的性能迭代优化框架
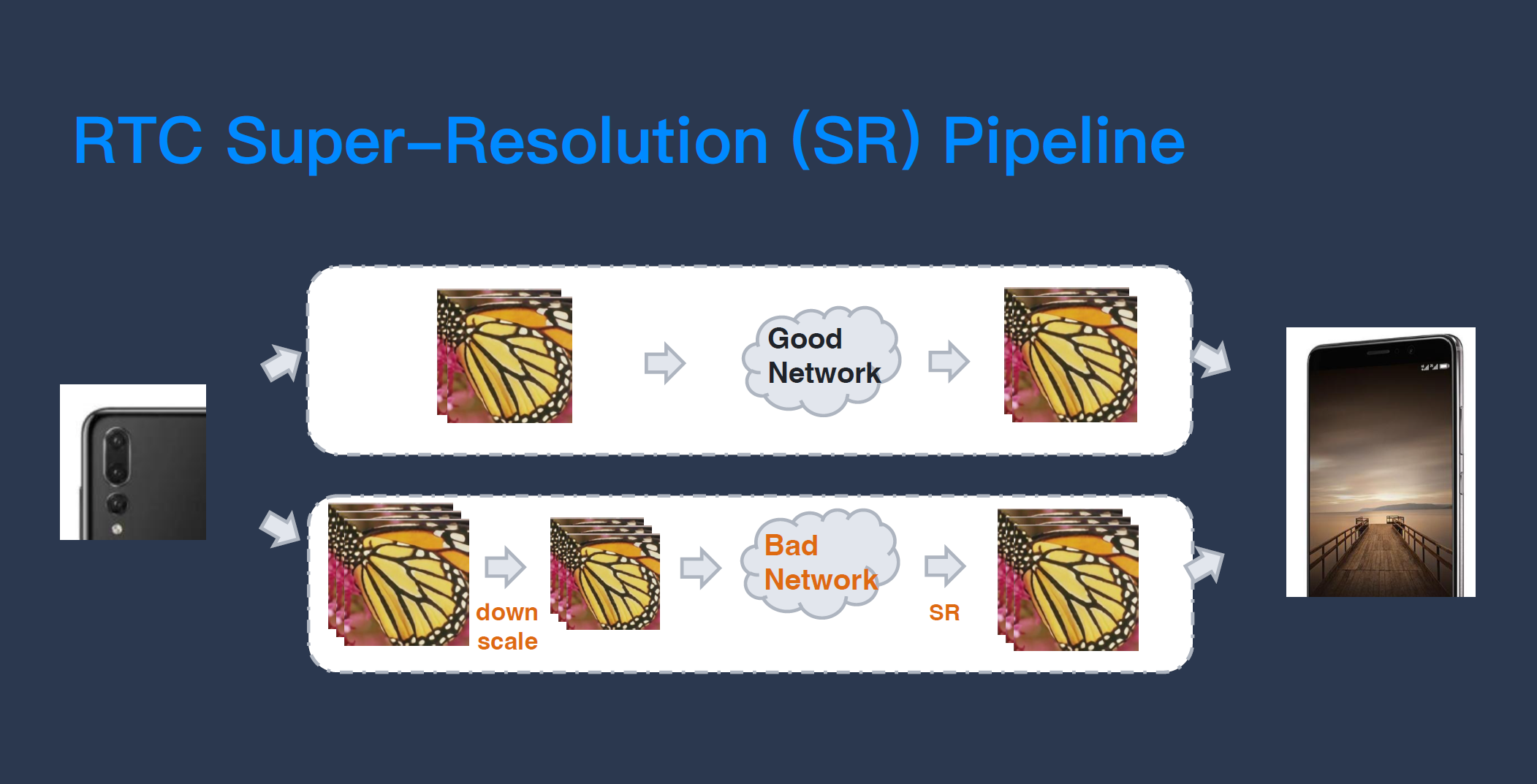
第一个故事是关于「超分辨率」。超分辨率是一个比较古老的图像处理问题,它的本质是把低分辨率的图像放大到高分辨率,并想办法恢复或重建图像中的一些细节。由于网络带宽等限制,视频在压缩时无可避免地会受到一些损坏,超分可以做一个“修复者”的工作,它最合适的位置是在接收端。
超分在 RTC 中的作用很大,它解决的问题是在系统资源有“限制”的情况下,视频质量被损坏,它能够部分恢复视频的质量(不是完全恢复)。“限制”包含了带宽限制和系统性能限制,比如在网络带宽非常低的时候,假设只有 200Kbps,我们需要要传一个 720P 分辨率的视频,这时传输的视频质量就会非常差,在这种情况下,我们不如先把它先缩小(比如先下采样到 360P),用好一点的质量把小分辨率先传出去,再在接收端用超分把画质还原回来。还有比如一些低端机发不出 720P 的视频,一发就卡顿,我们就可以先降低分辨率发出去,再通过超分把它修复回来。

超分在 RTC 中应用会遇到一些挑战。首先是计算复杂度的问题,超分不是简单的上采样,目前学术界的方式都是用深度学习卷积神经网络去训练超分模型,不可避免地,这是一个计算量非常大的操作,计算量大会限制超分的分辨率和运行设备,比如限制在比较低的分辨率,或者一些超分模型只能限制在一些高端机上使用,低端机上跑不动。
其次是所有类似的后处理技术都会面临的一个问题:如何衡量超分做得好不好?线上打开超分后,我们非常需要知道,超分到底让画质增加了多少?新的模型在线上是不是比旧的模型要好?这些数据不仅对线上运营有帮助,对之后的算法模型迭代也有帮助。另外,由于深度学习并不是我们设计的一个我们能够理解的算法,它也有可能会造成“损坏”,比如损坏一些暗场景增强、一些美颜特效的效果。“衡量效果”是一个比较大的难题,因为我们只知道它在线下训练模型的测试组里面跑得好不好,无法知道这个模型在线上跑的效果好不好。
这两个挑战是我们在 RTC 中应用超分时遇到的比较实际的问题。
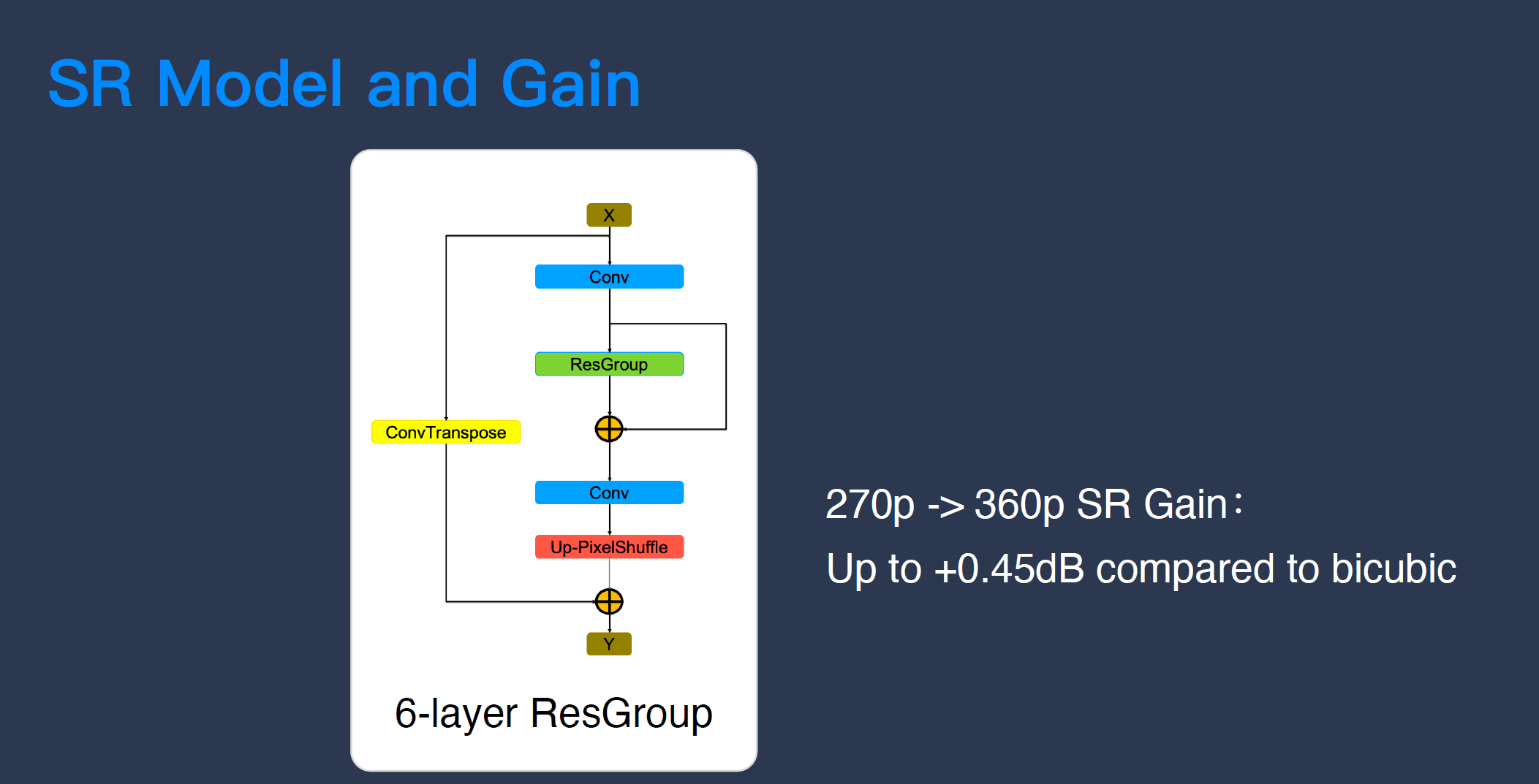
在讨论如何解决这两个问题之前,我们先了解一下 RTC 系统中实现视频超分的卷积神经网络——使用 Resnet 的残差神经网络。Resnet 网络可以有很多层,甚至可能高达一百五十几层,但因为要跑在客户端上,所以我们使用了一个非常小的神经网络,我们使用的这个网络有 6 层,但即使是这样,它的复杂度也远比做一些线性的上采样要高。
和 Bicubic(OpenCV 常用的一种上采样方法)相比,当我们把视频从 270P 超分到 360P,基本可以达到 0.5dB 左右的视频修复能力。0.5dB 是什么概念?1.5dB 大概是 H.264 和 H.265 两代视频压缩标准之间相差的压缩收益,0.5dB 是它的 1/3。也就是说,在什么事情都不做、所有网络传输条件都一样的情况下,通过超分就可以平白让视频质量增加 0.5dB,这是很高的收益。
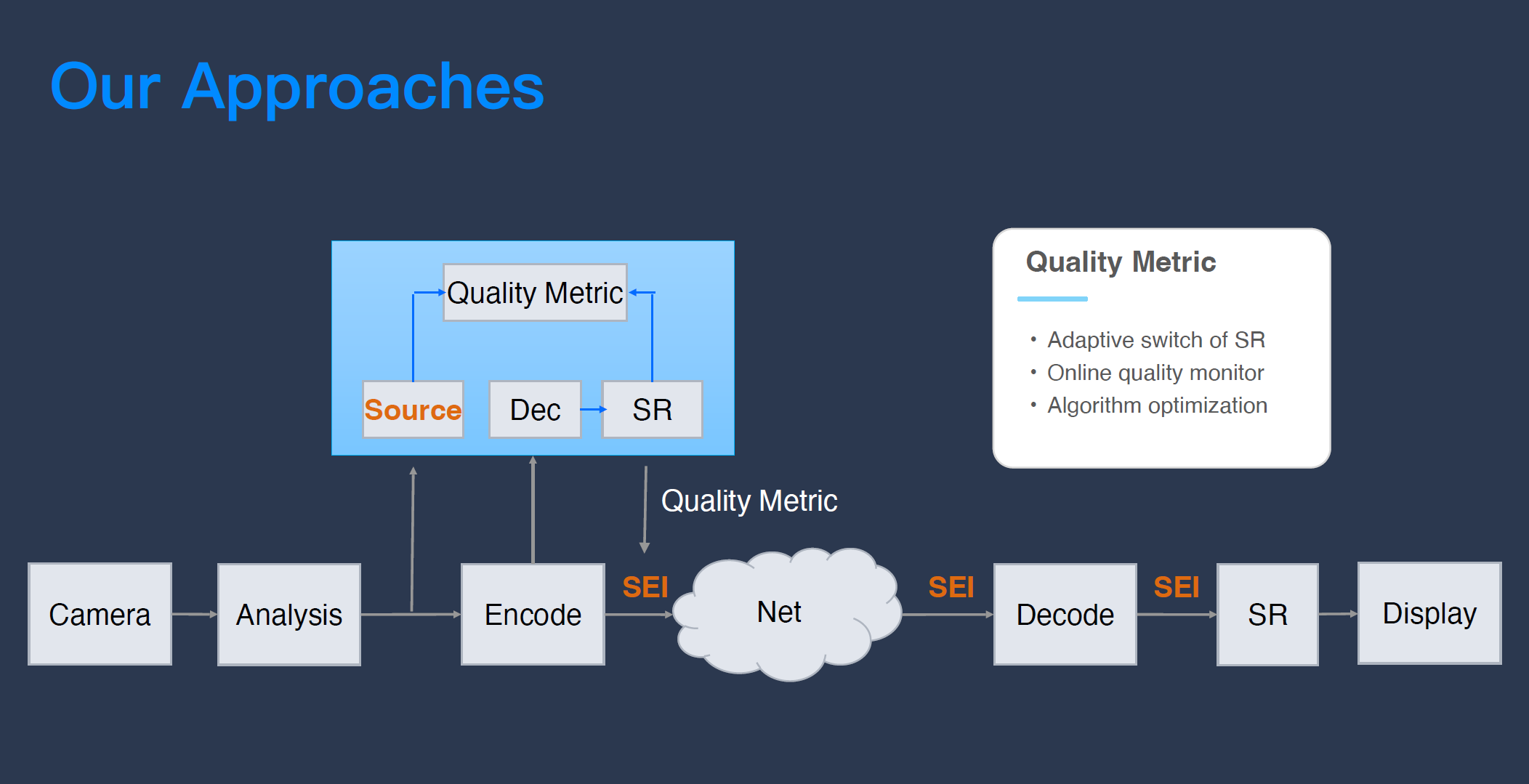
我们怎么用“收发联动端到端优化”这个思路解决超分“复杂度高”和“结果难衡量”的问题?
刚才我们说过,因为只有发送端有“视频源”,如果要做质量评估,只有在发送端做才是最直接、最准确的,所以我们的解法很简单,就是把超分搬到发布端去做质量评估,计算出超分能够在接收端恢复多少质量。通过这个方式,我们可以对每一个超分迭代模型在线上的表现进行评价。大家可能会认为这么做的复杂度很高,不建议这么做,但实际上,我们在线上只会放比如 2% 的量来做评价,再利用大数据来了解这个模型在线上的表现,了解这个模型在线上到底跑得好不好,第二代模型有没有比第一代模型好。
然后,我们用 SEI 把“超分收益好不好、值不值得做”的评估结果传递给接收端。这样做有什么好处?因为超分是在恢复带宽造成的质量“损伤”,但 RTC 系统弱网情况大概只占 20%,也就是说,80% 的情况都是好网,并不会造成视频的损伤,如果我们打开了超分,它不管网络好坏照样跑,把绝大部分计算量资源跑去恢复一个并没有什么损伤的视频是资源的浪费。
所以,当发布端已经知道超分在这一系列帧到底有多少恢复量的时候,如果恢复不多(比如网络很好没有什么压缩破坏,或者这帧视频非常简单,低带宽就可以压缩得很好),它就可以直接告诉接收端“现在不值得做超分,把超分关了”,这样我们就可以把复杂度投入在它产出最高画质、修复最高的那一段视频帧里,降低计算的复杂度。
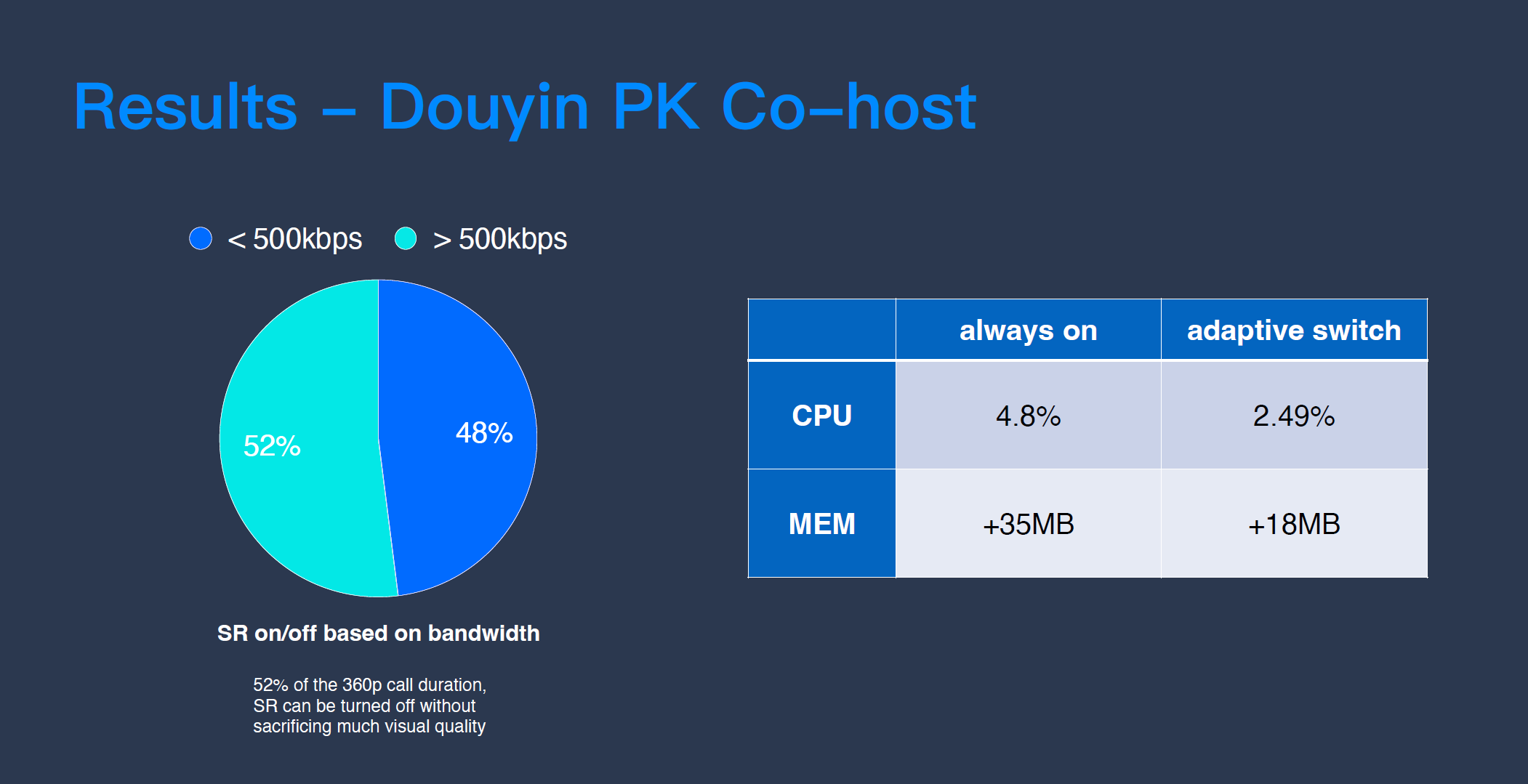
经过端到端优化后的超分技术在抖音直播连麦场景帮我们节省了很多计算量。抖音直播连麦在实际应用时,如果处于弱网条件下,我们的做法是先下采样到 270P,再通过超分把它还原到 360P。由于 52% 的网络情况是带宽大于 500Kbps,网络传输并不会给视频带来额外的质量损伤,这时候用超分做修复的收益是很低的,可以忽略的。
所以,针对带宽大于 500Kbps 的场景,我们告诉接收端“不用开启超分”;针对带宽小于 500Kbps 的场景,我们则告诉接收端“开启超分”。发布端通过 SEI 把决策传递给接收端,接收端开启“Adaptive Switch”,动态地开关超分这个功能。通过这个动态的开关,CPU 计算量增量从 4.8% 降到 2.5%,内存的增量也可以几乎减少一半,从 35MB 到 18MB,但整体的质量修复并没有明显的减少,证明了我们其实是把计算量放在了真正有修复能力的这段视频帧上。
智能内容模式的下行延时优化
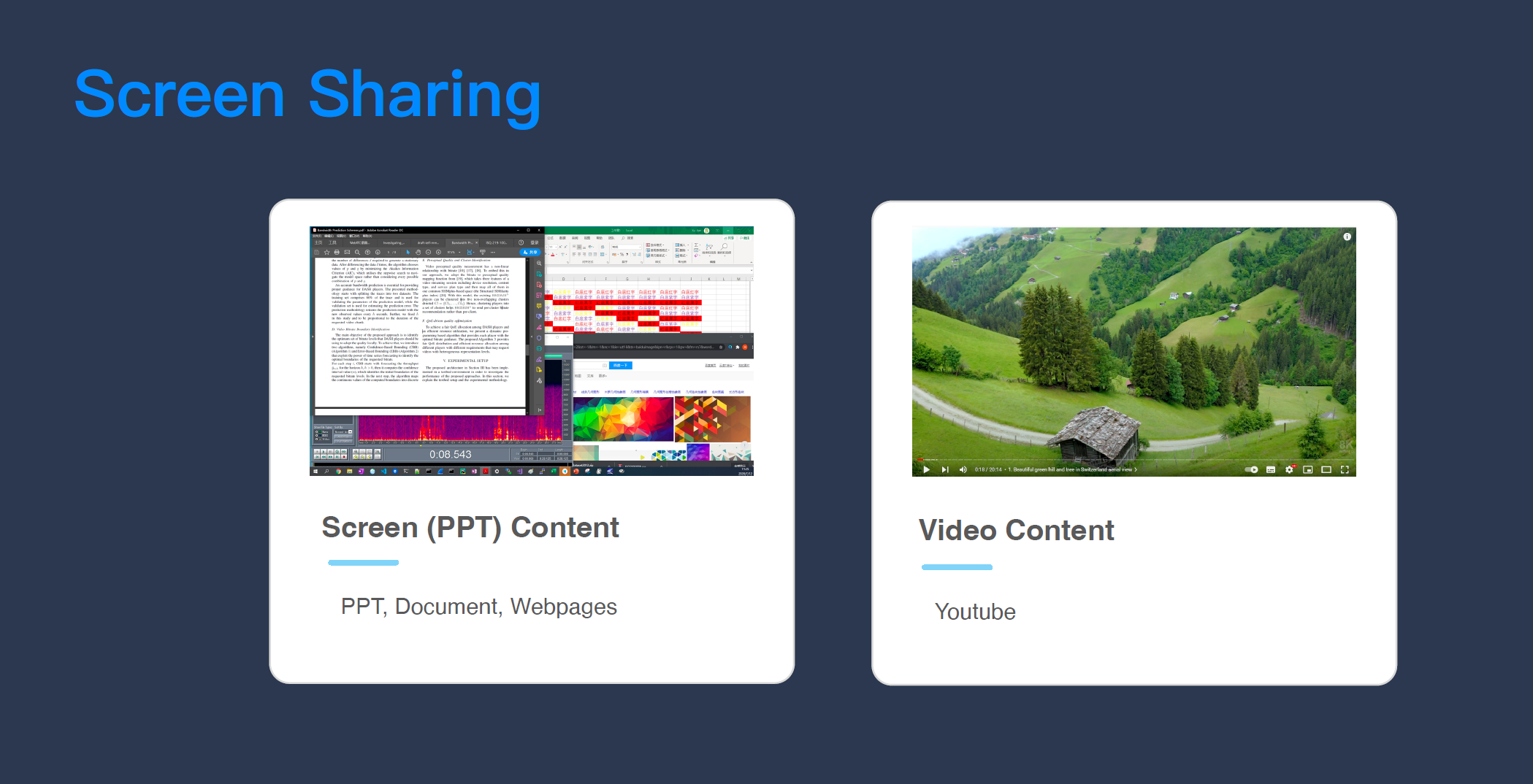
第二个故事是关于「屏幕分享」的。屏幕分享是视频会议的一个常用功能,它在视频会议里的使用率比开视频还要高。大家在使用屏幕分享时可能会遇到这种情况:在讲 PPT 时突然播一段视频,视频会变得很卡,帧率很低。有一些视频会议厂商针对这种情况支持提供一个模式,叫“流畅模式”,如果播放视频卡,勾一下“流畅模式”,视频就流畅了;下一页 PPT 又变成了文字,我们又发现文字变模糊了,然后厂商会说,这时候应该选择“清晰模式”,它就会变清晰了。这种做法给用户的体验非常差,用户很容易忘记,切来切去也很麻烦。

这个问题的本质在于,屏幕分享的 PPT 和视频是两种截然不同特性的内容,它们具备完全不同的视频参数和弱网对抗策略参数:在共享 PPT(或文档)的时候,我们的要求是越清晰越好,也就是说,它对分辨率的要求很高,但帧率可以很低,一般我们在分享文档的时候,如果是 4K,其实只要每秒 1 帧就够了,大家会看着就会觉得非常舒适,很清楚;在共享视频的时候(比如电影),它对帧率的要求很高,但分辨率可以很低,比如一般的视频可能 720P 就够了,但帧率需要 30FPS。
这是在视频参数上的不同,在弱网情况下,这两种内容也有非常不一样的弱网对抗策略:PPT(或文档)需要非常低的延时,特别是投屏场景,大家一定希望电脑换页的时候投屏也马上换页,但它可以忍受非常高的卡顿,两帧之间可以忍受 500ms 的间隔,甚至很多时候每 2 秒 1 帧用户也不会感受到它有没有卡;视频则是完全相反的,视频需要非常高的流畅性和非常低的卡顿,但是它可以容忍比较高的延时,大家其实并不太在意他看到的视频和演讲人分享的视频差了 2 秒钟,只要视频本身是流畅的就可以,但一旦两帧之间有有卡顿的情况,大家就会觉得很不舒服。
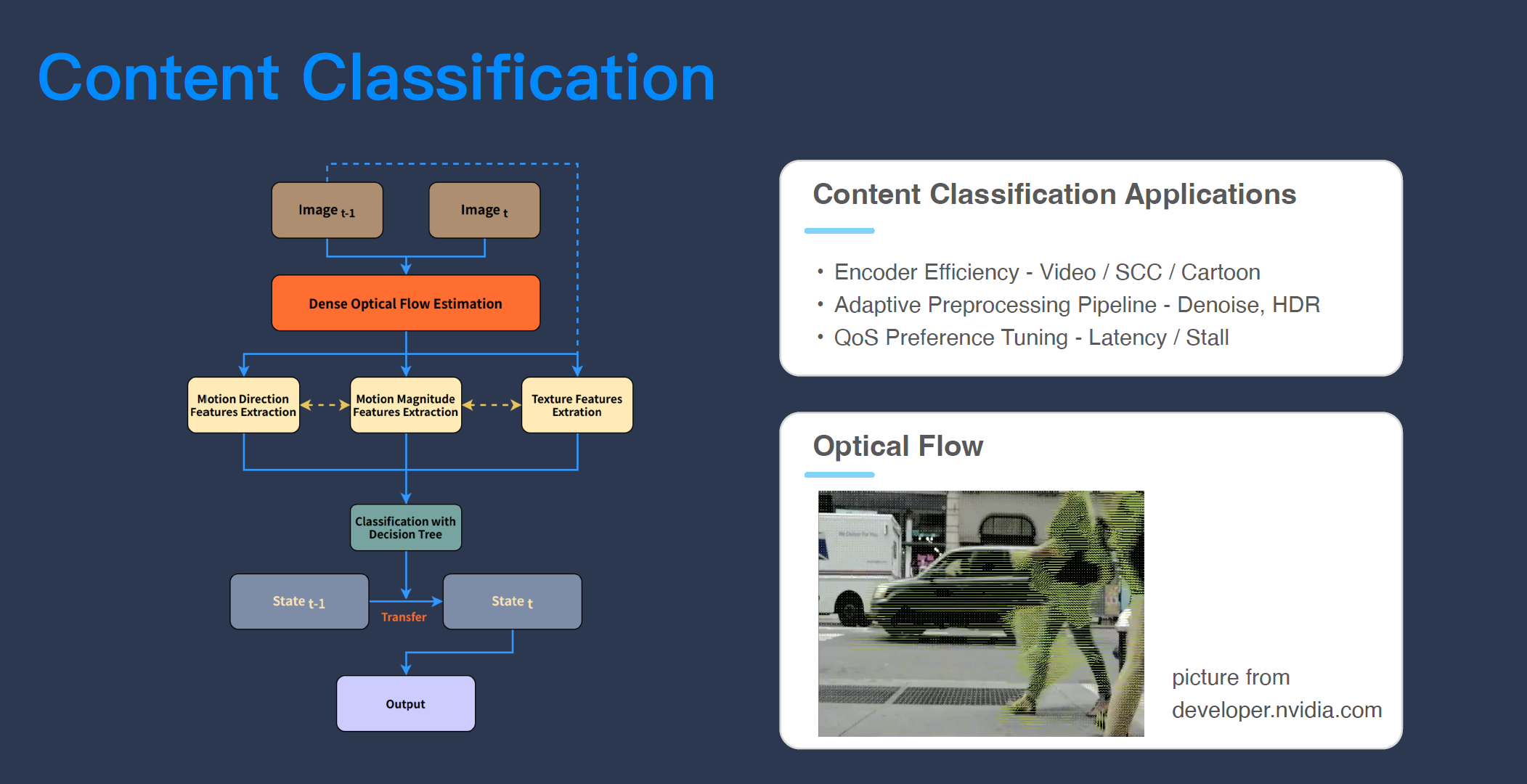
在实际情况中,分享的内容是视频还是 PPT 是会动态变化的,用这种“屏幕分享前勾选“清晰模式”或“流畅模式”,勾选后就不动”的做法不太行得通,我们需要一个实时的、能够动态去分辨分享内容类型的机制——我们叫内容检测,去分辨当前分享的视频帧到底是 PPT 还是视频,然后通过这个信息在发布端做一些策略联动,比如分享 PPT 需要 4K 的分辨率,发布端就可以通知采集来提升分辨率。同时,编码器也可以针对不同的视频内容做不同的参数调整。
举几个比较常见的例子,在 H.264 年代有一个非常有名的开源编码器叫 X264 直播,虽然那时还没有“屏幕分享”,但已经有“动画模式 Animation”,如果你告诉它现在在编码的是一个动画,它就可以通过参数调整把压缩率提高 30%。在 H.265 年代,视频标准里面直接写入了 SCC(Screen Content Coding),这是一种针对文字的编码模式,它里面用的 Hash ME 可以针对屏幕内容去做压缩,将压缩率提升 40%,也就是说,如果你告诉编码器它编码的内容是什么,它就可以降低 40% 的带宽。同样地,如果你告诉 Pacer(Pacer 是发布端的一个网络控制模块,它可以决定冗余控制,FEC、重传控制的响应)现在共享的是什么类型的内容,它也可以去控制屏幕内容和视频内容的延时。
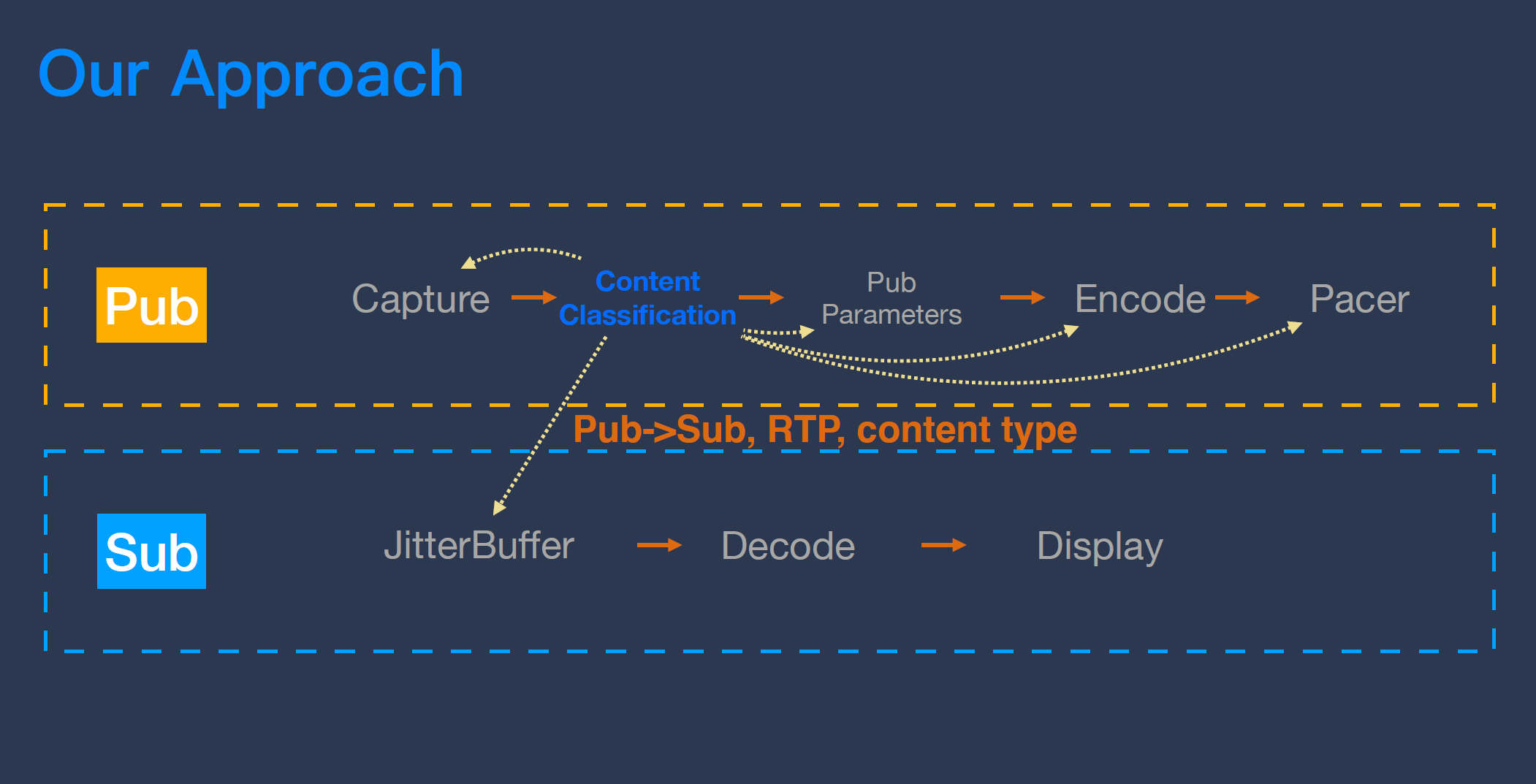
当然,这里最关键的是发布端要怎么把内容检测的结果传给接收端。接收端里的 Jitter Buffer 是整个 RTC 系统里控制延时和卡顿 Trade Off 的关键模块,它可以决定系统的延时是多少,而延时则会直接决定卡顿程度。一个简单的概念,如果愿意使用延时很大的策略,换来的就是系统卡顿减少,类似地,像分享视频这种场景对卡顿的要求很高,就可以选择一定程度的“牺牲延时”。目前,我们使用 RTP 扩展头的方式把内容检测的结果传递给接收端,传递给 Jitter Buffer,由 Jitter Buffer 来决定“延时”和“卡顿”的偏好。

我们看一下这个策略为“飞书屏幕分享”带来的收益。在体验方面,如果用户分享的是 PPT,屏幕可以直接从 1080P 提升到 4K,帧率从 15FPS 降到 5FPS,如果用户分享的是视频,帧率可以从 15FPS 提升到 30FPS。另外,通过收发联动优化,Jitter Buffer 收到了内容检测信息以后,可以针对 PPT 限制它的 Max Jitter Delay,同时关闭 AV 同步,这样做以后,整体分享文档的延时可以从 400ms 降低到 240ms。
智能参考帧的极致弱网延时体验优化

第三个故事是关于「智能参考帧」的一些实践。智能参考帧技术解决了 RTC 的一个深水区问题——大卡顿(我们一般定义两帧间隔超过 2s 以上的叫做大卡)。一个丢包造成的弱网很容易导致卡死的情况(Frozen Frames),它是怎么造成的?
举个简单的例子,一般情况下,如果丢包了,短时间之内接收端会请求重传,让发送端再传一次(视频参考帧是有依赖关系的,这一帧其实依赖前一帧,下一帧就依赖这一帧),如果发送端能够重传过来,接收端能够补上这一帧,后面就都可以顺利地解码和输出。但如果重传失败,时间到一定的长度,接收端就会直接请求一个 PLI(Package Loss Indication),它会触发发布端开始发送 I 帧,I 帧就是关键帧,它不依赖任何其他帧,所以它特别大,在丢包网络中,越大的帧越容易丢包,越丢包它越传不到,越传不到越请求它,它就越编一个更大的帧给接收端,然后越接收不到,如此便会造成大卡顿的恶性循环。
大家可能会想到,把 I 帧编小一点是不是就解决问题了。这里给大家一个数字,I 帧跟 P 帧大概是 3-5 倍的大小差,也就是说,I 帧约是 P 帧的 5 倍大。如果把它限制在 2 倍大,让它好传一点,它的质量就会特别差。大家在开视频会议的时候,如果发现每 2 秒画面就会闪一下,这种间隔的闪动叫呼吸效应,它表示你看到 I 帧了。 为了把 I 帧缩小,I 帧就会很模糊,它的质量和前后帧会很不一样。
这并不是我们想要的结果。
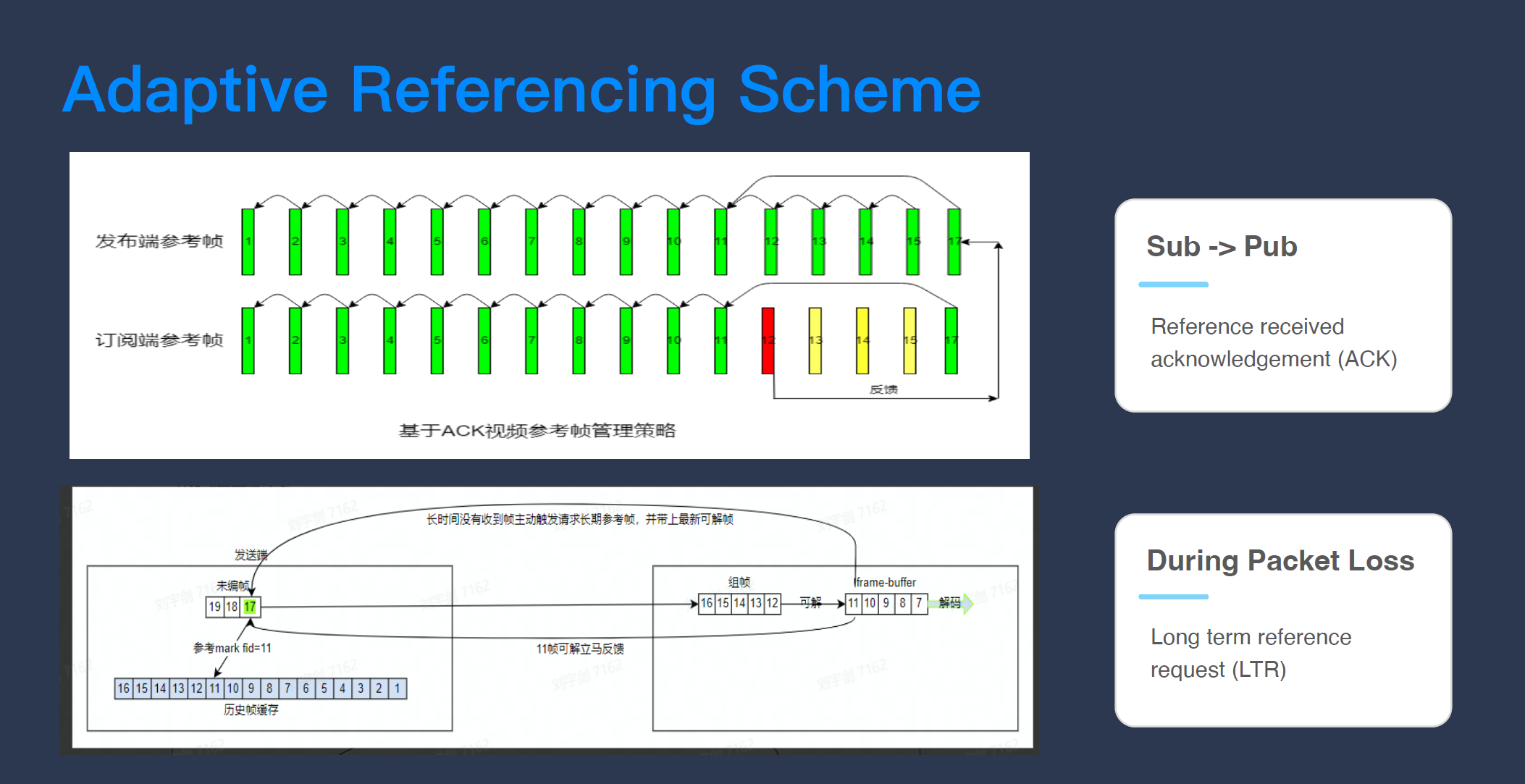
智能参考帧提供的方案很简单,它在接收端跟发布端维持了一套一模一样的参考帧关系。这样做的好处是,当系统进入大卡时,发布端其实知道接收端手上有什么已经成功解码的关键帧,所以它可以发布一个接收端已经有的参考帧,而不是重新发 I 帧,这个技术叫做 LTR (Long Term Reference),它的原理是,不管什么时候向发布端请求,因为发布端“知道”接收端已经完整收到了某些帧(这些帧可以当参考),它就发一个接收端手上已有的参考帧。它改变了原来固定的参考帧关系,变成“我知道你有什么,让你去参考你自己有的东西,这样你永远可以解码”。其次,它可以解决带宽浪费的问题,原来接收端请求一个关键帧,需要清空 Buffer;现在发布端发送的任何东西,除非被网络丢包了,只要接收端可以收,它就可以解码。这一点很重要,尤其是在丢包网络的情况下,这么做可以避免带宽浪费。

智能参考帧的关键是在发布端和接收端维护一样的参考帧关系,即,接收端需要把它的参考帧关系通过编一个很精炼的信息来传递给发布端。通过在 RTCP 加入 ACK(Acknowledgement),接收端告诉发布端它已经收到并完整解码了哪些帧,这些帧可以进入参考帧关系结构,一旦发生弱网,接收端就告诉发布端取消 PLI,不再请求 I 帧,而是请求 LTR,避免弱网情况下发 I 帧导致弱网情况更恶化、甚至导致卡死的状况。

智能参考帧技术在一些对卡顿、延时比较敏感的场景中对提升用户体验有很大帮助,比如在抖音好友通话场景中,通过智能参考帧,“大卡”比例下降了 14%(两秒钟不出帧的“大卡”比“小卡”对用户体验的影响要大很多),而在一般的卡顿指标上,200ms 卡顿和 500ms 卡顿分别下降了 2.6% 和 0.7%。另外,智能参考帧在很大程度上也解决了延时的问题。刚才有提到,智能参考帧只要收到就能解码,而不需要通过重传,因此在智能参考帧中大部分重传是可以被关掉的,关掉后延时可以降低 11%,也就是说, 200ms 的传输可以减少 20ms,端到端延时 200ms 的达标率可以提升 16%。
视频端到端优化技术的未来展望
以上三个故事就是利用收发联动优化的技术解决视频参数上升、带宽限制下的视频修复、弱网丢包、延时、“大卡”体验的问题,未来我们还可以做哪些优化呢?

在「超分辨率」上,除了告诉接收端它可以开关超分,针对线上不同的机型,我们还可以推荐它使用不同的模型,比如高端一点的机型可以使用复杂一点、强一点的模型,我们可以告诉接收端哪个模型最适合它,哪个模型的“性价比”更高。另外,发布端其实是可以知道接收端有没有超分的能力,如果知道接收端有超分的能力,那么在碰到弱网的时候,发布端可以更进一步地去主动降低分辨率。
现在的做法虽然也可以主动降低分辨率,但做得不够激进,因为发布端并不“确定”接收端能不能开启超分。如果发布端“确定”接收端可以开启超分,那么,也许本来是在 200K 的带宽才降低分辨率,现在甚至可以在 300K 的带宽下就降低分辨率——因为降低分辨率后之后再进行画质修复的效果,会比不降分辨率直接传输的效果更好。这就是所谓的 SR-aware 参数选择。
在「内容检测」上,我们也可以扩展一下,目前内容检测的结果是非黑即白的,即,内容的分类不是 PPT 就是视频,未来它会向更精细的视频分析方向演进,比如检测视频内容是运动的还是偏静止的,是复杂的运动还是简单的运动(比如是有人在跳舞健身,还是只是一个主播在播新闻)。视频和 PPT 是两个非常极端的场景,中间频谱上还可以细分很多档位,每一个档位都可以有不同的视频参数以及弱网对抗的策略(比如运动的内容可能需要 60FPS,但是一个静态的主播可能只需要 15FPS)。未来,内容检测可以告诉我们这个视频的复杂程度、或运动的程度是怎么样,而不只是简单告诉我们它是文字还是视频。
在「智能参考帧」上,智能参考帧技术和编解码器有强绑定的关系,目前支持智能参考帧的硬件编码器非常少,基本只支持 Nvidia 和 Intel 这类比较常见的硬件,iOS 跟 Android 大部分没有硬件编码器支持,这会把智能参考帧的性能限制在软件编码器中,而用软编实现的方案会限制智能参考帧只能应用在一些分辨率较低的场景。未来,智能参考帧技术还将往移动端硬件方向进一步发展,研究让更多的硬件编码器来支持这个技术,拓展更多高分辨率的应用场景。
未来,RTC 的问题会越来越破碎化,特别是当我们进入深水区以后。「上下行联动优化」是一种方式,希望以上这些分享可以帮助大家在一堆混乱的麻绪之中理出一些思路,来思考或解决一些问题。




