
2020 年,DeepMind 发布了一种能够生成超越人类能力的深度强化学习芯片布局设计方法,随后在《自然》杂志上发表了该方法,并通过 GitHub 开源了相关成果。AlphaChip 项目激发了芯片设计 AI 领域的大量后续工作,并已在 Alphabet 最先进的芯片中得到应用,同时得到外部芯片制造商的支持和扩展。
不过之后,业内也持续有对 AlphaChip 的质疑。在 2024 年 11 月的《ACM 通讯》杂志上,Synopsys 架构师 Igor Markov 也发表了对三篇论文的元分析,主要包括 AlphaChip 原论文、Cheng 等人投稿到 ISPD 的论文以及 Markov 未发表的论文,总结了人们对 AlphaChip 的各种质疑。事件始末如下:
2020 年 4 月:发布 AlphaChip 《自然》论文的 arXiv 预印本。
2020 年 8 月:在 TPU v5e 中流片了 10 种由 AlphaChip 生成的布局。
2021 年 6 月:在《自然》杂志上发表论文。
2021 年 9 月:在 TPU v5p 中流片了 15 种由 AlphaChip 生成的布局。
2022 年 1 月至 2022 年 7 月:在确保遵守出口管制限制并消除内部依赖关系之后,DeepMind 开源了 AlphaChip。期间谷歌中另一支团队独立复现了 AlphaChip 在《自然》杂志上所发表论文中的结果。
2022 年 2 月:谷歌内部的独立委员会拒绝发表 Markov 等人的论文,因为数据并不支持其主张和结论。
2022 年 10 月:Trillium(最新发布的 TPU)中流片了 25 种由 AlphaChip 生成的布局。
2023 年 2 月:Cheng 等人在 arXiv 上发帖,声称对 AlphaChip 的方法进行了“大规模重新实现”。
2023 年 6 月:Markov 在 arXiv 上发布了他的“元分析”预印本论文。
2023 年 9 月:《自然》杂志发布编者注,称他们正在调查 DeepMind 的论文,并启动了第二轮同行评审流程。
2024 年 3 月:谷歌 Axion 处理器(基于 Arm 架构的 CPU)采用了 7 种由 AlphaChip 生成的布局。
2024 年 4 月:《自然》杂志完成了调查与出版后审查,并完全支持 DeepMind 的成果,结论是“最好的解决方式是以附录形式发布论文更新。”
2024 年 9 月:联发科高级副总裁宣布,他们扩展了 AlphaChip 以加速其最先进芯片的开发。
2024 年 11 月:Markov 重新发表了他的“元分析”文章,但此前在《自然》杂志的调查和二次同行评审过程中,他提出的担忧被发现毫无根据。
谷歌 DeepMind 三位高级研究员 Anna Goldie、Azalia Mirhoseini 和 Jeff Dean 联合发文,针对上述论文提出的质疑做出了回应。
DeepMind 指出,Cheng 等人受邀发表的 ISPD 论文没有遵循标准的机器学习实践,其中采用的强化学习方法与实验设置同 AlphaChip 在《自然》论文中的描述存在很大差异。此外,ISPD 的受邀论文未经同行评审。
“元分析”论文是一份未发表的 PDF,未列出作者名单,文章描述称其为“谷歌二号团队”进行的“单独评估”,但实际上是由 Markov 本人参与并共同撰写,且这一事实在文章中并未披露。这篇文章并不符合谷歌的出版标准。2022 年,谷歌独立委员会对其进行了审查,认定“草稿中的主张和结论并未得到实验科学的支持”,且“由于 AlphaChip 在其原始数据集上的结果确实可独立复现”,因此 [Markov 等人] 的强化学习评估结果受到质疑。DeepMind 向该委员会提供了一行脚本,该脚本生成的强化学习结果明显优于 Markov 等人报告的结果,也优于他们“更强”的模拟退火基准性能。DeepMind 三人称仍不清楚 Markov 及其他联合作者如何得出论文中的数字。
Markov 的“元分析”也让 DeepMind 产生了新的担忧,即谷歌内部存在一位“告密者”。但这位“告密者”向谷歌调查员承认,他并无确切理由怀疑 AlphaChip 论文存在欺诈行为:他曾表示怀疑 Goldie 和 Mirhoseini 的研究成果中存在欺诈行为,但表示没有证据支持他的这种怀疑。
“在他的‘元分析’中,Markov 在没有证据的情况下对 DeepMind 实际上并不存在的‘欺诈与学术不端行为’做出了疯狂推测。Markov 的大部分批评方式可以总结为:在他看来,DeepMind 的方法不应该起效,因此一定不会起效,而任何指向相反结论的证据都属于欺诈。《自然》杂志调查了 Markov 提出的质疑,发现其完全没有根据,并在调查结束后发表一份附录来为我们的工作正名。”DeepMind 表示。
Markov 指出,“在这篇论文中,我们发现机器学习中存在各种可疑的做法,包括不可复现的研究实践、刻意挑选结果、误报以及可能的数据污染(泄漏)。”对此,DeepMind 表示:
我们不存在任何此类行为,也没有任何其他形式的学术不端举动,Markov 亦没有为这些指控提供任何证据。Markov 在论文中没有对所谓“刻意挑选结果”做出任何具体描述,更遑论列举切实证据。他亦没有对所谓“误报”做出明确解释,或者提供证据。文中没有提供任何数据污染(泄漏)的证据,只表示这种情形可能有助于获得更好的研究结果。这些指控当中,相当一部分在正文中根本见不到,却在“结论”部分突然冒了出来。
顺带一提,Cheng 等人在脚注部分也提到,在其针对主数据表的 6 个测试案例中,RePlAce 在 2 项测试中无法得出任何结果。
DeepMind 表示,Markov 在他的“元分析”文章中完全没有提及他本人就是这两项“单独评估”之一的作者。他还在参考文献部分的论文作者中省略了自己的名字,只链接到一份匿名 PDF。当在 LinkedIn 上被问及时,Markov 先是承认了自己的作者身份,但后来又删除了该帖子。
Markov 也没有披露他在 Synopsys 公司担任高级职务的情况,该公司授权发布多种与 DeepMind 开源方案相竞争的商业工具。“请注意,Markov 的引文与我们的论文无关,这可能误导读者认为原始文章为其观点提供了佐证。”
DeepMind 进一步表示,“为了诋毁我们的 TPU 部署,Markov 还暗示谷歌是在故意‘护犊子’,即允许在 TPU 中使用劣质的 AlphaCip 生成布局来支持我们的研究发现。这既不符合事实,也十分荒谬。谷歌永远更关心 TPU 设计的效率——毕竟这是一个耗资数十亿美元的项目,也是 Google Cloud 以及多个 AI 项目的核心,重要程度远超一篇研究论文。”
DeepMind 总结道,简而言之,Markov 的论文未包含原始数据,仅仅是对两篇论文的“元分析”。第一篇论文未列出作者名单(尽管 Markov 本人就是作者之一)且从未发表过,提出的主张既没有科学数据支持也无法复现。第二篇由 Cheng 等人发表的论文,是 Markov“元分析”中唯一的实质性内容,因此我们在后文中将主要讨论此文声称在复现我们方法时遇到的重要问题。
“事实上,我们投入了很长时间才让 TPU 团队对我们的成果建立起足够的信任,让他们使用我们的布局。尽管 AlphaChip 在指标层面的表现已经超越了人类专家,但我们理解 TPU 团队的担忧——他们的工作是按时交付 TPU 芯片,并保证成果尽可能高效可靠,因此不想承担任何非必要的风险。AlphaChip 已被部署在 Alphabet 的其他硬件当中,但属于商业机密因此目前无法披露。”DeepMind 研究员称。
下面是 DeepMind 详细指出的质疑论文中存在的问题。
Cheng 等人在成果复现过程中的错误
Cheng 等人声称在新的测试用例上,将 DeepMind 的方法与其他方法进行了比较。DeepMind 研究院指出,Cheng 等人并未严格按照《自然》杂志上描述的方式运行成果,因此得到的结果自然也相去甚远。DeepMind 整理了他们在复现过程中的 5 个主要错误:
没有预先训练强化学习方法。从先前经验中学习的能力是 DeepMind 基于学习方法的主要优势,而将其消除本质上就是在评估一种完全不同且质量更差的方法。预训练也是 Gemini 和 ChatGPT 等大语言模型获取强大 AI 生成能力的前提(「GPT」中的「P」就代表「预训练」)。
使用的计算资源低了一个数量级:强化学习经验收集器仅相当于原始论文的二十分之一(26 个,《自然》论文中为 512 个),GPU 减少至一半(8 个,《自然》论文中为 16 个)。
未将模型训练到收敛。训练到收敛是机器学习领域的标准实践,因为这样才能保证性能稳定。
在不具代表性且不可重复的基准上进行评估。Cheng 等人的基准采用更旧且尺寸更大的制程节点(45 纳米与 12 纳米,《自然》论文中为 7 纳米以下),而且从物理设计角度来看存在很大差异。此外,作者无法或不愿公布其主数据表中复现结果所使用的综合网表。
对 DeepMind 的方法进行了“大规模重新实现”,但这可能会引发错误。
强化学习方法没有经过预训练
AlphaChip 是一种基于学习的方法,意味着随着其解决更多芯片布局问题实例,它也会变得更快、更好。这种改进是通过预训练实现的,预训练包括在运行保留的测试用例(测试数据)之前先在“练习”布局块(训练数据)上接受训练。
训练数据集越大,该方法在布局设计方面的表现就越好。Cheng 等人根本没有进行过预训练(即没有训练数据),这意味着强化学习代理之前从未接触过芯片设计,必须从头学习如何针对各个测试用例进行布局。这消除了 DeepMind 方法的关键优势,即从先前经验中学习的能力。
与其他知名的强化学习用例类似,这就像评估一个之前从未接触过围棋比赛的 AlphaGo 版本(而非经过过数百万场对弈预训练的版本),然后得出结论说 AlphaGo 不擅长围棋。
DeepMind 在《自然》论文中详细讨论了预训练的重要性(例如「预训练」一词出现了 37 次),并通过经验证明了其影响。例如,《自然》图四(在本文中为图三)显示预训练可以提高布局质量和收敛速度。在开源 Ariane RISC_V CPU 上,未经预训练的强化学习策略需要 48 个小时才能达到预训练模型在 6 小时内所产生的结果。正如 DeepMind 在《自然》杂志上所发表论文中所述,DeepMind 为了获取主数据表中的结果进行了 48 小时的预训练,而 Cheng 等人的预训练时长为 0 小时。
在 Cheng 等人的论文发表之前,DeepMind 与其中作者的最后一次沟通是在 2022 年 8 月。当时 DeepMind 与对方联系,并分享了 DeepMind 的最新消息。
相比之下,在《自然》杂志上发表之前,DeepMind 与 Cheng 等人的高级作者 Andrew Kahng 进行了广泛沟通。此外 DeepMind 还联系了此前最先进技术 RePlAce 的研究团队,以确保 DeepMind 使用了 RePlAce 的适当配置。
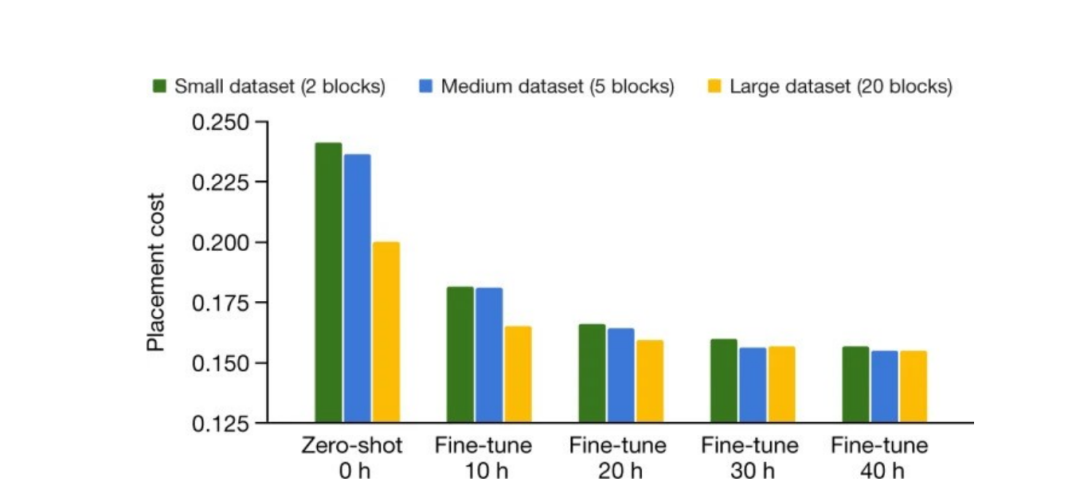
对大量布局块进行预训练所带来的性能提升
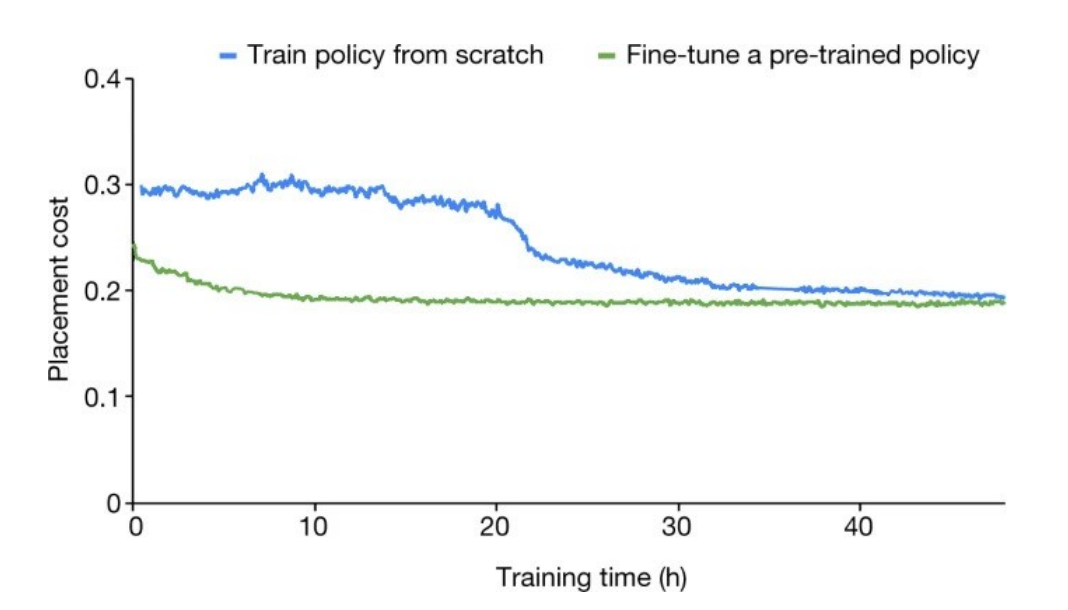
与从随机初始化策略开始相比,预训练能够提高收敛速度。在开源 Ariane RISC-V CPU 上,随机初始化策略需要 48 个小时才能达到预训练策略在 6 小时内所产生的结果。
DeepMind 的开源代码仓库可以完全复现在《自然》杂志上描述的方法。Cheng 等人试图为他们预训练的缺失寻找借口,称 DeepMind 的开源代码仓库不支持预训练,但这是不正确的。DeepMind 提供了多个预训练运行方法示例,且始终受到支持。
为强化学习方法提供的计算资源远少于原始论文
在 Cheng 等人的论文中,强化学习方法使用的经验收集器仅为原始论文的二十分之一(26 个,《自然》论文中为 512 个),GPU 数量减少至一半(8 个,《自然》论文为 16 个)。算力资源的减少可能会损害性能,或者需要运行更长时间才能实现相同(或者更差)的性能。
如下图,在大量 GPU 上进行训练可以加快收敛速度并获得更好的最终质量。如果 Cheng 等人在论文中使用与《自然》论文中相同的实验设置,可能会改善他们的复现结果。
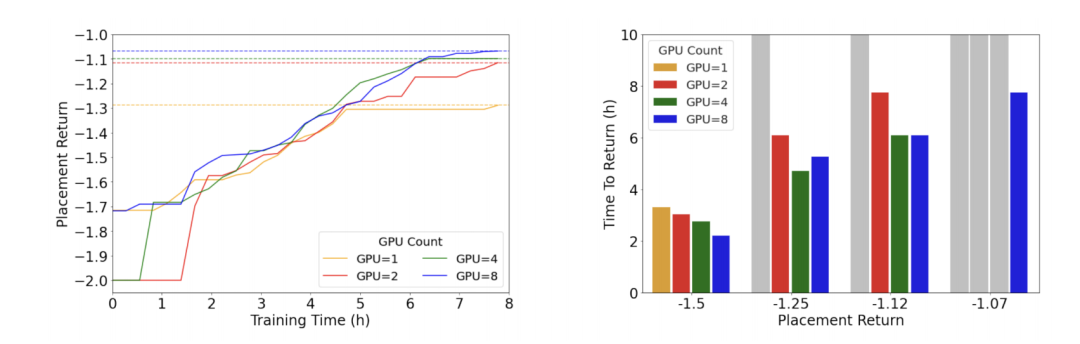
速度和质量会随着计算资源的增加而提高。左图:布局反馈(越高越好)与训练时间的关系,表现为一条关于 GPU 数量的函数。不可行的布局将获得 -2 的布局反馈,增加 GPU 数量则可获得更好的最终布局。右图:达到给定布局回报所需要的时间,表现为一条关于 GPU 数量的函数。灰色条表示实验未达到特定的回报值。最佳布局回报 -1.07 只能在 GPU=8 的情况下实现,而这已经是 Cheng 等人实验中的最高设置。
未将强化学习方法训练至收敛
随着机器学习模型不断接受训练,其损失通常会减少而后趋于稳定,代表其发生了“收敛”——即桺尼桑学会了它所能学到关于当前所执行任务的知识。训练收敛是机器学习领域的标准实践,未至收敛则会损害性能。
Cheng 等人在其随附项目站点上,没有提供四个布局块上任何一项达到收敛的训练结果图(其中 BlackParrot-NG45 和 Ariane-NG45 完全没有配图)。
图五所示,为 Cheng 等人项目站点上的收敛图。表一总结了其中的可用信息。对于所有四个配有收敛图的布局块(Ariane-GF12、MemPool-NG45、BlackParrot-GF12 和 MemPool-GF12),训练在相对较低的步数(分别为 350k、250k、160k 和 250k 步)10 处停止。遵循标准机器学习实践可能会提高这些测试用例的性能。
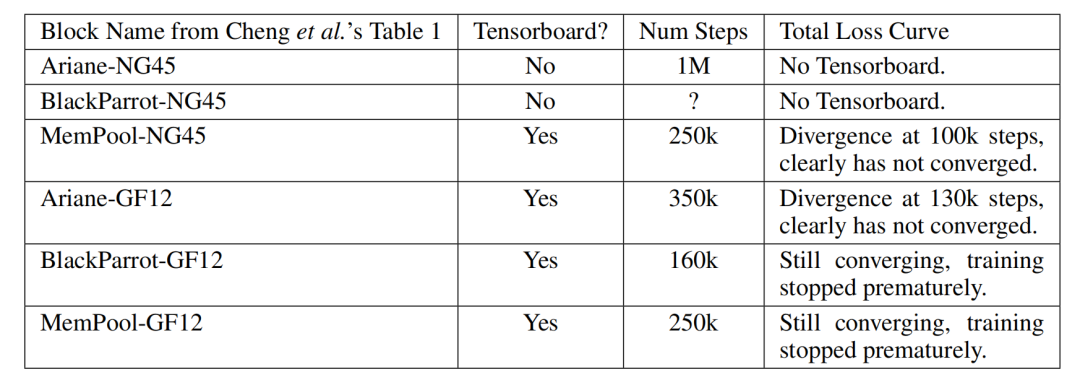
Cheng 等人未在随附项目站点上提供任何在测试用例上进行了正确训练的 Tensorboard 证据。
Cheng 等人的测试用例未使用现代芯片
尽管 Cheng 等人似乎显示 1M 步后在 Ariane-NG45 上实现了收敛,但却省略了总训练损失中的大部分内容,仅描述了线长、密度和拥塞成本。但除此之外,总损失还应涵盖熵正则化损失、KL 惩罚损失、L2 正则化损失、策略梯度损失和值估计损失。关于训练损失的详细信息,
_可参阅开源代码:_https://github.com/google-research/circuit_training/blob/ 90fbe0e939c3038e43db63d2cf1ff570e525547a/circuit_training/learning/agent.py#L408。
Cheng 等人没有为该布局块提供 TensorBoard,如表一所示,所有其他布局块的运行步数则远少于 1M 步。
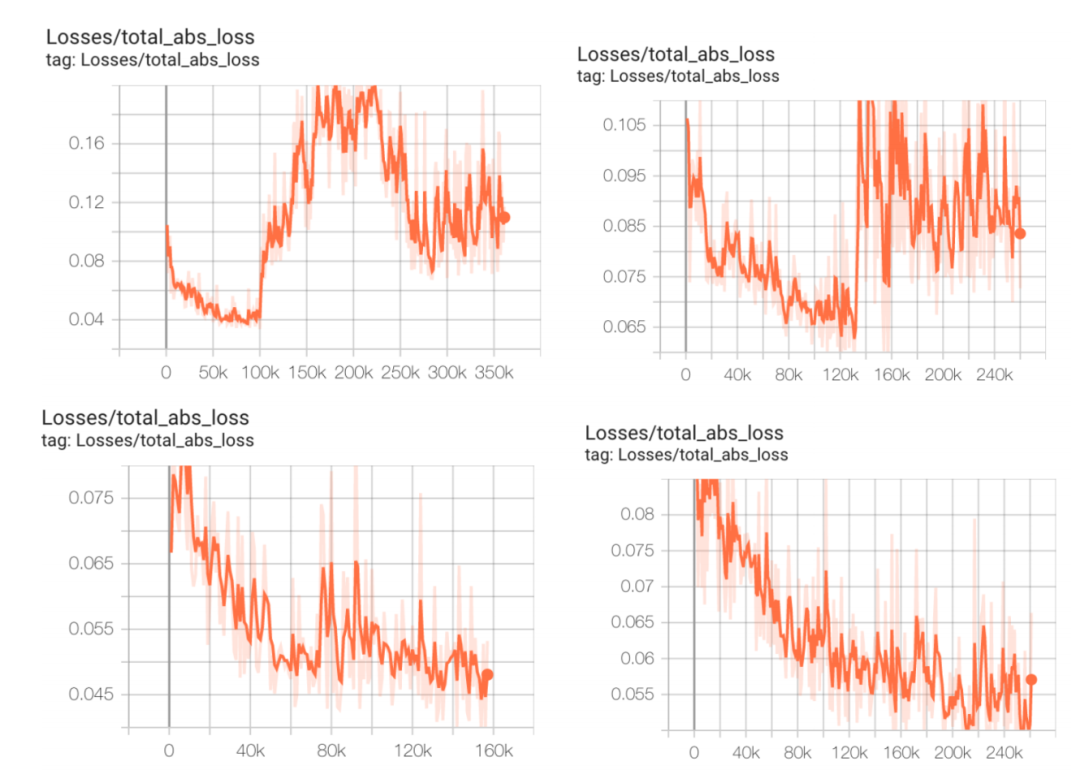
Cheng 等项目站点上公布的收敛图。在 Ariane-NG45(左上)和 MemPool-NG45(右上)中,在 100k 步左右出现了奇怪的发散,但损失似乎仍呈下降趋势,且可能随着进一步训练而改善。在 BlackParrot-GF12(左下)和 MemPool-GF12(右下)处,模型尚未收敛,且同样可能在更长的训练时间后改善。
在《自然》论文中,DeepMind 报告了在 7 纳米以下制程工艺的张量处理单元(TPU)运行布局块的结果,其代表现代芯片的典型特征。相比之下,Cheng 等人言说蝇使用的是较旧的制程节点(45 纳米和 12 纳米),其在物理设计角度存在很大区别;例如在 10 纳米以下,芯片通常使用多重图案化 [15.38],导致在较低密度下出现布线拥塞问题。因此对于较旧的制程节点,DeepMind 的方法可能受益于对其奖励函数 11 的拥塞或密度分量的调整。DeepMind 并没有专门将自己的技术方案应用于较旧的芯片节点设计,因为 DeepMind 所有的工作都运行在 7 纳米、5 纳米及更新的制程工艺之上。
Cheng 等人论文中的其他问题
与商业自动布局设计工具的不恰当比较
Cheng 等人将被严重弱化的强化学习方法,与在 DeepMind 方法发布多年之后的闭源专有软件进行了比较。“这显然不是对我们方法进行评估的合理方式——据我们所知,这款闭源工具可能就是基于我们的成果构建而成。”
谷歌工程师确实提出了验证建议,但并未遵循 Cheng 等人提出的具体方法。
2020 年 5 月,DeepMind 开展了一项内部盲测 12,将其方法与两款领先的商业自动布局设计工具的最新版本进行了比较。DeepMind 的方法优于后两者,以 13 比 4(3 平)的成绩优于其中一种,以 15 比 1(4 平)的成绩优于另外一种。遗憾的是,受到商业供应商的标准许可协议的限制,DeepMind 无法公开具体对比细节。
“消融”了标准单元簇重新均衡中的初始布局
在运行 DeepMind《自然》论文中的方法之前,DeepMind 利用物理合成(即芯片设计过程中的前一步)中的近似初始布局方式解决了 hMETIS 中标准单元簇大小不均衡的问题。
Cheng 等人对单个布局块(Ariane-NG45)进行了“消融”研究。他们没有简单跳过簇重新均衡步骤,而是尝试将所有芯片组件堆叠在左下角 13,导致重新均衡步骤产生了退化的标准单元簇。对于由此引发的性能损害,Cheng 等人得出结论,认为 DeepMind 的强化学习代理以某种方式利用了初始布局信息,却忽略了其根本未访问初始布局且未放置标准单元的现实情况。
DeepMind 也进行了一项消融研究,完全消除了对初始布局的使用,且没有观察到性能下降(见表二)。DeepMind 只是跳过了集群重新均衡的步骤,转而将 hMETIS 的簇“不均衡度”参数降低到最低设置 (UBFactor=1)14,借此保证 hMETIS 生成更加均衡的簇。这项辅助预处理步骤已被记录并自 2022 年 6 月 10 日起开源,但随后发现其没有必要,因此已被从 DeepMind 的生产流程中删除。

在存在和不存在初始布局的情况下,对标准单元进行聚类后的强化学习结果。对于所有指标来说,幅度均越低越好。不存在初始布局的聚类似乎不会造成性能损害。
代理成本与最终指标之间的相关性研究存在缺陷
Cheng 等人声称,DeepMind 的代理成本与最终指标间缺乏良好的相关性。但从他们的相关性研究方法来看,总体代理成本与除标准单元面积之外的所有最终指标间存在着较弱的正相关性。DeepMind 将布局面积视为硬约束条件,因此不会对其进行优化。
基于机器学习的做强 使用的代理成本,通常仅与目标具有弱相关性。例如,Gemini 和 ChatGPT 这样的大语言模型就通过训练来猜测序列中的下一个单词,这在本质上属于嘈杂信号。
此外,Cheng 等人在相关性研究中还做出了一些令人“匪夷所思”的选择:
DeepMind 的盲测将强化学习与 20 个 TPU 布局块上的人类专家与商业自动布局设计工具进行了比较。首先,负责放置给定布局块的物理设计工程师会对这几种匿名布局进行排名,且仅根据最终 QoR 指标进行评估,期间并不知晓各布局由哪种方式生成。接下来,由七名物理设计专家组成的小组负责审查排名结果是否可靠。在全部两轮评估完成之后,才最终揭晓答案。结果是,最佳布局多数由强化学习方法生成,其次是人类专家,最后是商业自动布局设计工具。
Cheng 等人还尝试将所有组件放置在右上角的顶部和中心的单个点上。不出所料,这同样引发了性能退化。
UBfactor 是一条范围从 1 到 49 的参数,其取值越低则代表 hMETIS 越是优先考虑对簇大小做出均衡。在 DeepMind 发表在《自然》上的论文中,UBfactor 被设置为 5。
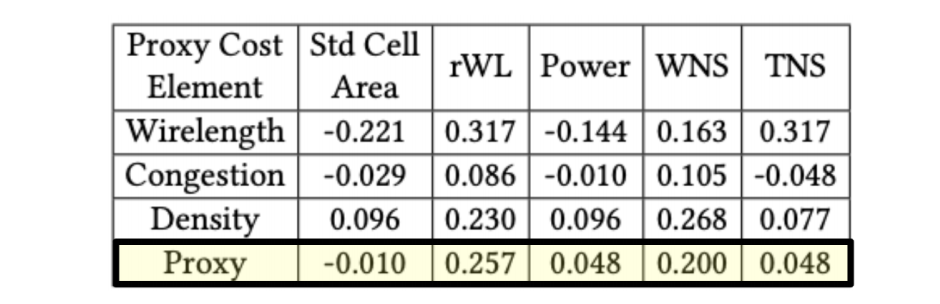
Cheng 等人论文中的表二显示,总体代理成本与最终指标之间存在较弱的正相关性,但标准单元面积除外,因为 DeepMind 将这项指标视为硬约束条件且不做优化。
Cheng 等人仅报告了代理成本低于 0.9 的相关性,且没有此为这种评判方式提供任何理由。这样的阈值排除了他们自己的大部分结果(参见 Cheng 等人论文中的表一)。
相关性研究仅考虑到单一 45 纳米测试案例(Ariane-NG45)。NG45 是一种更陈旧的制程节点规格,总体成本函数的拥塞和密度分量可能应该进行调整以更好地反映这种运行环境(参见第 2.4 节)。
Cheng 等人错误地声称谷歌工程师已经做出验证
Cheng 等人声称谷歌工程师证实了该文章的技术正确性,但事实并非如此。谷歌工程师(并非本《自然》论文的通讯作者)只是证实他们确实从头开始(即没有经过预训练)在 DeepMind 开源代码仓库的快速使用部分中,选取了单个测试用例并进行了训练。快速使用指南显然没有全面复制 DeepMind 在《自然》论文中描述的方法,只是作为确认所需软件已成功安装、代码已编译完成且能够在单个简单测试用例(Ariane)上成功运行的前置准备。
事实上,谷歌工程师们也提出了与 DeepMind 相同的担忧,并提供了建设性的反馈,但并未得到 Cheng 等人的理会。例如,在 Cheng 等人的论文发表之前,谷歌工程师们就已经通过书面交流和多次会议提出了改进意见,包括使用的计算资源过少、未能调整代理成本权重以解释截然不同的制程节点等等。
Cheng 等人在其文章的致谢部分,还列举了 DeepMind《自然》论文的通讯作者,以此暗示向他们征求过意见甚至参与过验证流程。但事实并非如此,通讯作者们完全是在该论文发表之后才得到消息。
透明度与可重复性
AlphaChip 属于完全开源项目
DeepMind 已经开源了自己的代码仓库,以完全复现 DeepMind 在《自然》论文中描述的方法。DeepMind 强化学习方法中的第一行代码均可自由接受检查、执行或修改,DeepMind 提供源代码或二进制文件来执行所有预处理及后处理步骤。TF-Agents 团队花了一年多时间公布了自己的开源代码,其中包括独立复现 DeepMind 的方法和《自然》论文中的结果。以下是我们开源代码仓库中的相关说明:
“我们在代码开源过程中与谷歌另一支团队(TF-Agents)共同合作。TF-Agents 首先使用我们的代码仓库复现了我们在《自然》论文中的结果,而后重新实现了具体方法并使用他们的实现再次复现了论文结果,而后将他们的实现版本进行开源,以保证其中不依赖任何内部基础设施。”
Cheng 等人毫无必要地对我们二进制文件中的两项函数进行了“逆向工程”以进行性能优化(分别为代理成本函数以及 FD 力导向标准单元布局器)。正如 MLCAD 2021 论文中所讨论,我们现在建议使用性能更高的 DREAMPlace 进行标准单元放置,而非 FD。我们提供传统 FD 二进制文件的唯一目的,仅在于精确复现我们在《自然》杂志上发表的方法。
关于公共基准,DeepMind 在《自然》论文中报告了开源 Ariane RISC-V CPU 的结果。此外,在 MLCAD 2021 的后续论文中,DeepMind 对开源 ISPD 2015 竞赛中的基准测试进行了评估 [6]。由于已经开源了项目代码,所以社区可以自由按照 DeepMind 的方法在任何公共基准测试上评估成果。
Cheng 等人声称他们无法公开他们的“开放”测试用例
DeepMind 对 Cheng 等人提出的批评之一,是其对《自然》论文的评估是在专有 TPU 布局块之上进行。Cheng 等人声称对一组开放测试用例进行评估是为了提高可重复性,但当 DeepMind 与对方沟通时,他们无法或不愿提供在其主数据表中“开放”测试用例上复现结果时使用的综合网表,这意味着 DeepMind 无法复现 Cheng 等人表一中的任何结果:
GF12(12 纳米):这些测试用例是专有的,不对公众开放,但却被 Cheng 等人在结果中予以混淆。意味着即使外部研究人员拥有访问权限,也仍然无法对结果直接进行比较。
NG45(45 纳米):尽管 Cheng 等人自 2024 年 2 月以来已收到 10 余次申请,但始终没有发布复现 NG45 结果所需的综合网表。请注意,其他论文也对 NG45 布局块进行了评估,但得到的结果与 Cheng 等人论文中表一的结果不一致,代表其结论的可重复性存疑。
现代芯片 IP 具有敏感和专有属性。据 DeepMind 所知,目前还没有针对前沿制程工艺的开放基准。目前,完全开放的设计通常为 28 纳米、45 纳米甚至 130 纳米,其许多物理设计特征与 7 纳米以下制程完全不同。
声明:本文为 InfoQ 翻译,未经许可禁止转载。




