
了解 Kylin 的技术同仁,一定对预计算这个概念不陌生。业内对于预计算的价值一直褒贬不一,今天笔者将结合自己的十多年的工作经验,从预计算的历史、原理到企业的应用,以及未来的发展来为大家带来更为全面的解读。
预计算的早期形式
预计算是一种用于信息检索和分析的常用技术, 其基本含义是提前计算和存储中间结果,再使用这些预先计算的结果加快进一步的查询。
其实在我们不知道预计算的时候,我们就已经使用过预计算了。 预计算的历史大概可以追溯到 4000 年前古巴比伦人最早使用的乘法表。 你回想小学背过的乘法表(如下图所示), 记住了乘法口诀,我们就可以通过心算来进行一些简单的乘法运算,这个过程其实就是一种简单的预计算。
乘法图表来源:
https://en.wikipedia.org/wiki/Multiplication_table
数据库中的预计算
预计算也广泛应用于数据库技术中。比如,关系数据库中的索引其实就是一种预计算。为了快速地检索数据,数据库会主动维护一个数据索引的结构,用来描述表格中一列或者多列数据的缩影。一旦索引的预计算完成,数据库不用每次都重新查找表格的每一行,就能快速地定位数据。假设 N 是表格的行数,有了索引的预计算,数据检索的时间可以从 O(N)减少至 O(log(N)) 甚至到 O(1)。
索引作为一种预计算,带来便利的同时也存在一些弊端。当表格中插入新的行数时,就需要重新进行的计算和储存。 当索引越多,查询响应越快时,那其实也意味着要进行更多的预计算,这当然也会显著减缓数据更新的速度。 下列图表展示了索引数量增加后,表格插入行的性能也相应降低 。
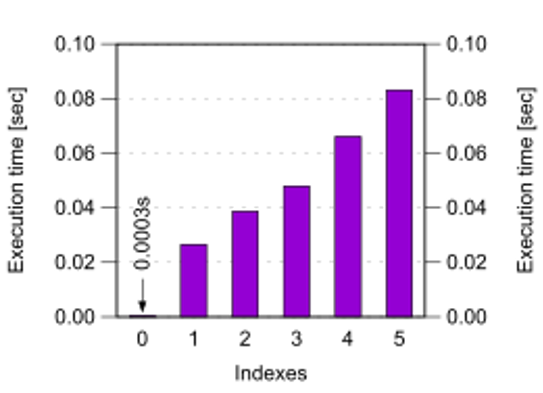
索引数量对插入行性能的影响图表来源:
https://use-the-index-luke.com/sql/dml/insert
汇总表,通常由物化视图实现,也是数据库中预计算应用的另一种形式。汇总表本质上是对于原始表格的汇总。一个十亿行的交易表按照日期进行聚合以后,可能就只剩几千行了。对数据的分析就可以通过汇总表而不是原始表来完成。受益于汇总表中数据量的大幅缩小,交互式的数据探索在汇总表上能提速数百倍甚至数千倍。而想在原始表格中完成这样的交互式分析几乎是不可能的。构建一个交易表的成本并不低,而且如果需要与初始表格保持同步更新的话,那成本就更高了。不过,考虑到分析速度的大幅提升及其所带来的价值,汇总表仍然是现代数据分析中广泛使用的一种工具。
OLAP 和 Cube 中的预计算
随着数据库技术的演进,数据库根据用途也出现了专精和分工。1993 年,关系数据库之父埃德加·科德(Edgar F. Codd)创造了 OLAP(On-Line Analytical Processing)这一术语来表示联机分析处理。 由此,数据库被分为专精于在线事务处理的 OLTP 数据库,和专精于在线分析的 OLAP 数据库。 就同你推测的一样,OLAP 数据库将预计算技术的运用提升到了更高的层次。
Cube 系统是一种特殊的 OLAP 数据库,它将预计算发挥到了极致。分析时数据可以具有任意数量的维度,而 Cube 就一个数据的多维度数组。将关系型数据载入到 Cube 的过程就是一种预计算,其中包括了对表格的关联和聚合。一个满载的 Cube 约等于 2n 个汇总表,其中 n 是维度的数量。这种巨量的预计算可能需要数小时才能完成!
Cube 的优势和劣势都十分明显。一方面来说,一旦 Cube 构建完成,就能带来最快的分析体验,因为所有的计算都已经预先完成了。无论你想查看数据哪个维度,结果其实都早已计算好了。 除了从 Cube 获取查询结果和进行可视化操作之外,几乎不需要再进行联机计算,这完美实现了低延迟和高并发。
另一方面,Cube 不够灵活,而且维护成本较高。这不仅仅是因为预计算和存储本身消耗资源,更多是因为将数据从关系数据库中载入 Cube 通常需要人工建设数据管道。每次业务需求变更时,都需要一个新的开发周期来更新数据管道和 Cube。这既需要投入时间,也需要投入金钱。
尽管投入不菲,在追求极致的低延迟高并发的大数据多维分析场景下,Cube 技术一直是不可或缺的一个选项。
Cube 图源:
https://en.wikipedia.org/wiki/OLAP_cube
大数据时代的挑战与机遇
展望未来,预计算在大数据时代又会面临什么挑战和机遇呢?
先说结论,随着数据总量和数据用户的持续增加,预计算将成为数据服务层中必不可少的基石。 为了更好地解释这一点,我们先要理解数字化转型时代的大背景和预计算的技术特征。
先来看看当下企业数字化转型的一些大背景。
数据量在持续增长(如下图所示)。未来,将有更多的数据需要分析,这也就是说,企业将每年投入更多的算力来处理每年新增的数据。
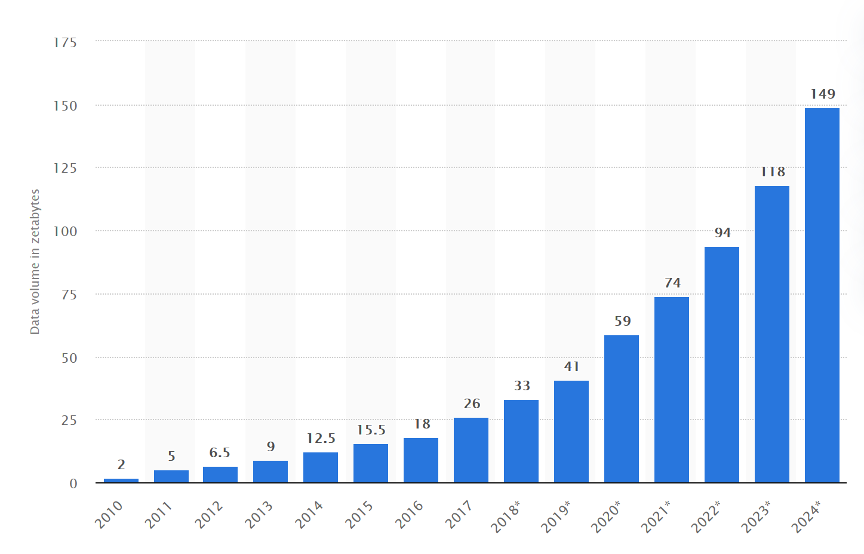
数据增长图来源:
https://www.statista.com/statistics/871513/worldwide-data-created/
摩尔定律已经走到尽头。德克萨斯大学的研究表明,从芯片制造的角度来看,过去十年中摩尔定律的影响已大不如前。与此同时,云计算的价格近年来基本保持平稳。这意味着,企业的计算成本会与数据量的增长保持同步。
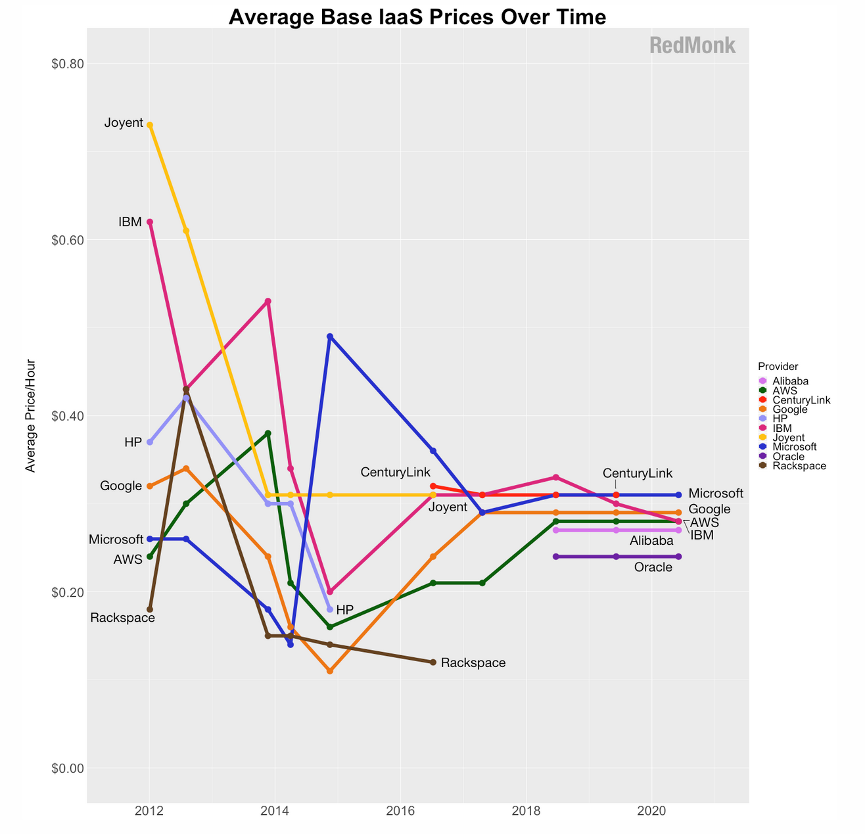
云计算价格图源:
https://redmonk.com/rstephens/2020/07/10/iaas-pricing-patterns-and-trends-2020/
数据使用者的数量会显著增加。只有当数据被用于决策时,数据才有价值。为了让数据这个“新石油”更好地驱动业务发展,理想状态是公司中的每位员工都会使用数据。这也就是说,未来分析系统上的用户可能将会是现在的数十倍甚至数百倍。平民数据分析师的时代要来了。
再来总结一下预计算的技术特征:
预计算其实是以空间换回了时间。如果追求响应速度,那么当然优先考虑预计算。
预计算增加了数据准备的时间与成本,但同时减少了数据服务的时间与成本。如果追求高并发和服务更多的消费者,那也优先考虑预计算。
预计算会导致数据管道边长并增加端到端的数据延迟。这是需要改进的部分,这点我们也将在后文详细介绍。
在以上的大背景下,让我们一起来看看,预计算将会如何帮助我们解决一些基本的分析需求。
如何在数据增长的同时依旧保持快速查询响应?
当我们使用联机计算(通常是 MPP 数据库)进行查询时,查询时间复杂度最小为 O(N),这意味着其所需的计算势必与数据成线性增长的关系。假设,今天一条查询运行时间是 3 秒,当数据量翻倍时,同样的查询运行时间就会变为 6 秒。要想数据分析师不抱怨,让查询响应时间保持在 3 秒之内,你只能向 MPP 供应商付双倍钱,让 MPP 系统资源增加一倍。与联机计算不同,当通过预计算进行查询时,你会觉得它好像不受数据增长的影响。因为大多数结果都被预计算了,所以查询时间复杂度接近 O(1)。即使数据量加倍,查询返回结果的耗时也与之前相差不大,查询的响应时间仍将为 3 秒。
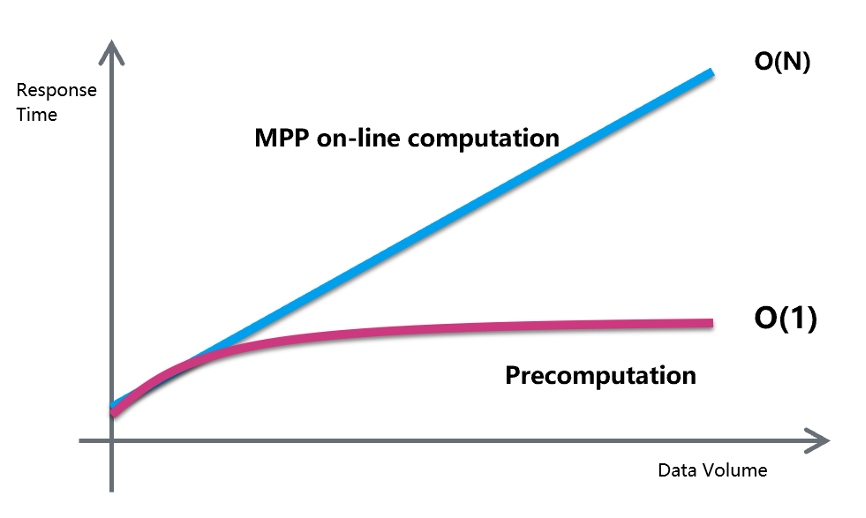
随着数据量增长,对比在线计算和预计算完成查询的时间复杂度
如何更好地满足“平民分析师”的并发需求?
对于联机计算而言,用户增长的影响类似于数据增长的影响。所需的计算量随并发用户的增长而线性增长。MPP 供应商可能会劝说你将集群规模增加一倍,来支持数量翻倍的分析师,不过公司的 IT 预算可能不允许,因为价格也翻倍了。另一方面,由于预计算将单条查询所需的资源最小化,新增用户所需的额外资源也能实现最小化。
当数据量和用户数量同时增长,如何管理 TCO(总拥有成本)?
云的优势在于,在云上所有资源消耗都可以通过成本进行量化。下图展示了在 AWS 中 MPP 数据服务和预计算数据服务之间的实际成本比较。实际成本包含数据准备成本和查询服务成本。其中,测评使用的工作负载是具有 1 TB 数据的 TPC-H(决策支持基准测试)。 假设我们今天有 40 位分析师,每位分析师每天运行 100 个查询语句,那么问题来了,如果数据量增长 25%,用户增长 5 倍,一年后的总成本将是多少?
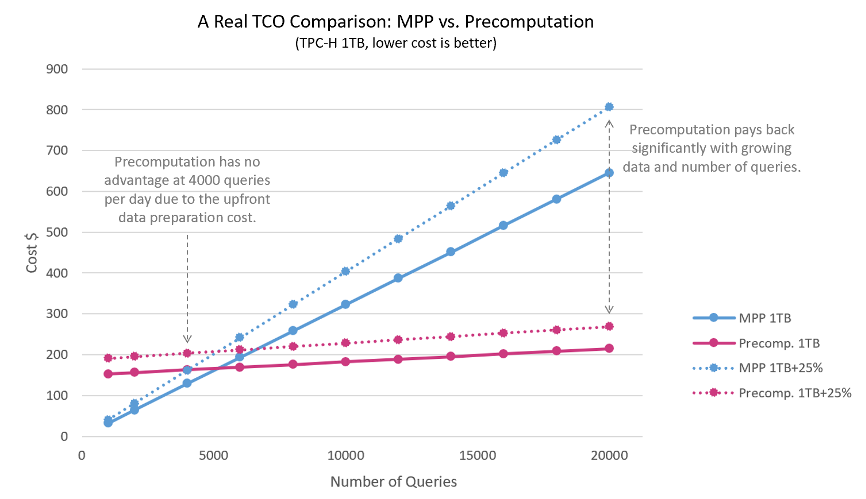
预计算数据服务和 MPP 服务总体拥有成本对比
实验表明,当查询或用户数量增长时,预计算的 TCO 优势明显。 尤其是当每天查询数量达到 20000 之后,预计算数据服务的 TCO 仅为 MPP 服务的 1/3。数据量增长越大,预计算的优势就越明显。
总而言之,在数字化转型的时代,预计算将会是大规模数据变现的关键技术。 数据服务系统在预计算加持下,能够同时实现快速响应时间,高并发和低 TCO。当然,就额外的数据准备而言,预计算也有它缺,这一点我们也会在下文展开讨论。
举例:将 OLAP 查询提速 200 倍
下面我们近距离观察一个实例,看看 Apache Kylin 如何使用预计算,将一个 TPC-H 查询加速 200 倍。 TPC-H 是一个数据库研究领域常用的决策分析测试基准。
在 100 GB 数据量下,TPC-H 基准里的 7 号查询在 Hive+Tez 的 MPP 引擎下需要执行 35.23 秒。从下图可以看到,这个查询并不简单,包括了一个子查询。执行计划显示,这个查询的包含了多个 Join 运算和一个 Aggregate 运算。这两种计算也是整体执行中最大的瓶颈。
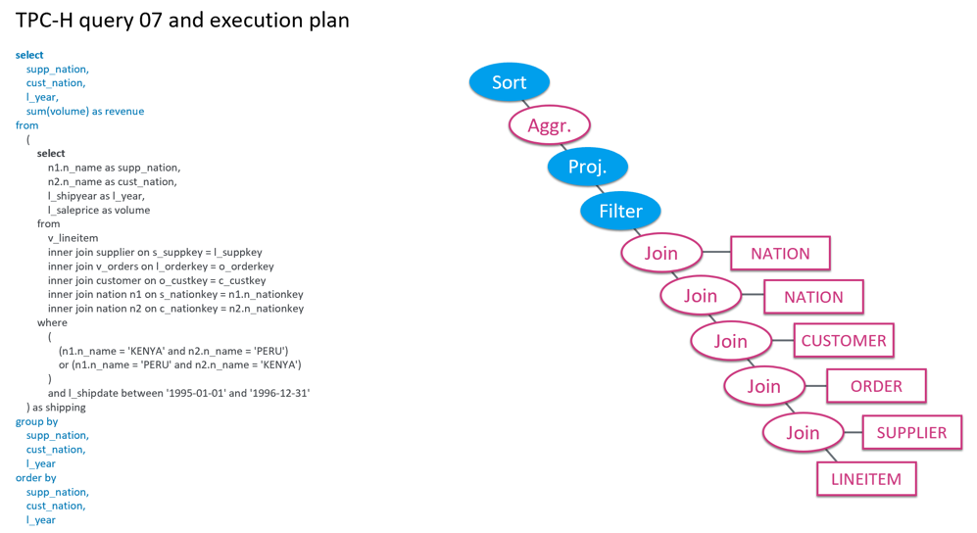
TPC-H 基准里的 7 号查询在 MPP 引擎下的执行计划
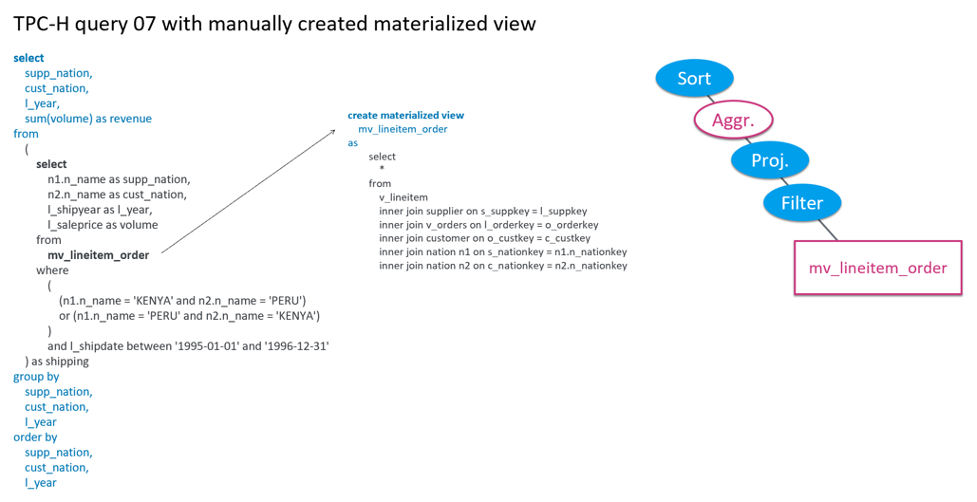
从预计算视角,我们容易想到使用一个物化视图,可以将 Join 运算提前算好,从而节省查询时的开销。如果人工来做,方法大致如下。
TPC-H 基准里的 7 号查询人工处理物化视图
注意到新的执行计划由于 Join 运算被替换为物化视图而大大简化了。但这个方法的缺点在于物化视图需要人编程工来创建和维护,并且应用层需要改写 SQL 来查询新的物化视图,而不是原始表。这种改写在实际工程中代价很大,因为涉及大面积的应用层重构,通常需要一个完整的开发周期,并需要全回归的应用测试。最后,Aggregate 运算仍然在线计算,预计算还有较大的提升空间。
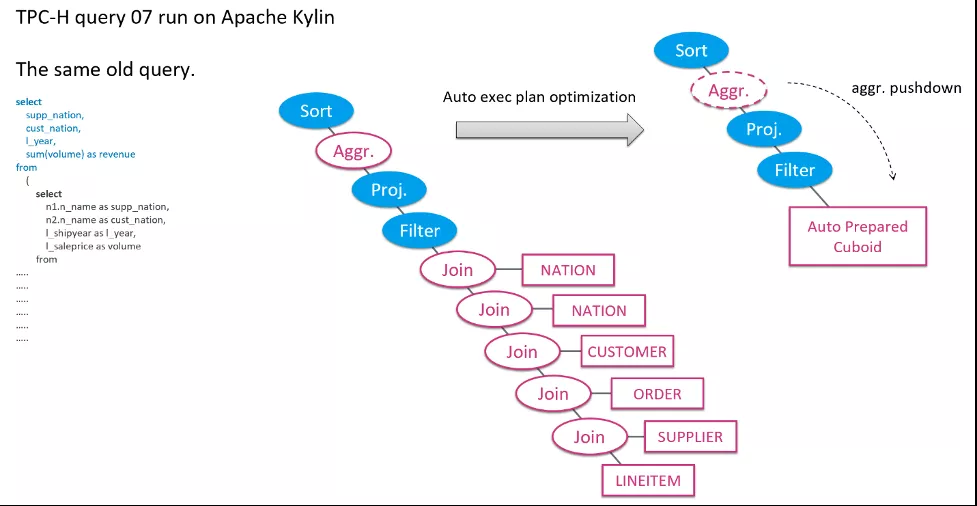
为了做到更完美的预计算,Apache Kylin 做了一下设计:
引入了多维立方体概念。一个 Cuboid 简单来说,就是一个包含了 Join 和 Aggregate 预计算结果的物化视图
帮助用户通过 GUI 配置方式,自动创建和维护 Cuboid
能自动优化查询的执行计划,动态选择最合适的 Cuboid 执行查询,而用户无需修改 SQL
TPC-H 基准里的 7 号查询在 Apache Kylin 环境下的执行计划
在 Apache Kylin 上执行同样的查询,在相当的硬件条件下,只需要 0.17 秒。充分的预计算消除了 Join 和 Aggregate 两个最大运算瓶颈。 在执行计划优化过程中,系统会自动挑选最合适的 Cuboid 并替换到执行计划里。应用层的 SQL 不需要修改,就能获得透明加速 200 倍的分析体验。
预计算未来可期
尽管预计算在大数据领域表现优异,但也确实存在一些缺点,例如,预计算可能会加剧数据管道的延迟,还需要额外的人工运维。不过好消息是,Gartner 预测:“到 2022 年,通过机器学习的增加和自动服务级别管理的壮大,数据管理手动任务将减少 45%”。我们将会在接下来的两年内,看到新一代智能数据库系统缓解甚至彻底消除这些问题。
在不久的将来,新一代数据库将以智能化和自动化的方式融入预计算技术。 下面是我们对未来一些预测:
为了支持更大的数据量和服务更多的平民分析师,预计算将会被会在数据服务层广泛使用。
借助人工智能和自动化技术,预计算的数据准备工作将会实现全面的自动化。例如,炙手可热的云上数仓 Snowflake 就在底层数据块上自动作小量聚合预计算并加以物化(small materialized aggregates [Moerkotte98]),过程对用户完全透明,完全自动化。 大数据 OLAP 引擎 Apache Kylin 也能根据用户配置的维度组合,自动化的完成将关系数据加载到 Cube 中预计算。整体配置过程在 GUI 中完成,不需要编程或大数据技能就可以实现 ,达到了半自动化的水平。
OLAP 数据库开始配备智能或透明的预计算功能。这样的数据库将能够在联机计算和预计算之间透明地切换。当需要查询最新数据时,就可以直接从 MPP 引擎查询最新数据,不会受困于数据管道的延迟。当查询能击中某些预计算时,那么已经计算好的结果将会在最大程度上减少查询成本,同时系统吞吐量也会提高。新型数据库将能够实现自动决定何时预计算,作哪些预计算,并智能地运用预计算来实现各种运维目标,比如快速响应时间,高并发性和低 TCO。而以上这些对终端用户都是透明的,彻底解放数据库管理员。
参考文献
Multiplication table https://en.wikipedia.org/wiki/Multiplication_table
Database index https://en.wikipedia.org/wiki/Database_index
More indexes, slower INSERT https://use-the-index-luke.com/sql/dml/insert
OLAP cube https://en.wikipedia.org/wiki/OLAP_cube
The Rise and Fall of the OLAP Cube https://www.holistics.io/blog/the-rise-and-fall-of-the-olap-cube/
Worldwide data volume https://www.statista.com/statistics/871513/worldwide-data-created/
Measuring Moore's Law 2020 https://www.nber.org/system/files/chapters/c13897/c13897.pdf
IaaS Pricing Patterns and Trends 2020 https://redmonk.com/rstephens/2020/07/10/iaas-pricing-patterns-and-trends-2020/
TPC-H decision support benchmark http://www.tpc.org/tpch/
Augmented Data Management https://www.gartner.com/en/conferences/apac/data-analytics-india/gartner-insights/rn-top-10-data-analytics-trends/augmented-data-management
作者介绍:
李扬,Kyligence 联合创始人兼 CTO
Apache Kylin 联合创建者及项目管理委员会成员 (PMC),曾任 eBay 全球分析基础架构部大数据资深架构师、IBM InfoSphere BigInsights 技术负责人和摩根士丹利副总裁,IBM“杰出技术贡献奖”获奖者,具有大数据分析领域 10 多年实战经验。
专注于大数据分析、并行计算、数据索引、关系数学、近似算法和压缩算法等前沿技术。在过去 15 年的工作经历中,见证并直接参与了 OLAP 技术的发展 。
本文转载自公众号 Kyligence(ID:Kyligence)。
原文链接:




