
近日,爱奇艺技术产品团队举办了“i 技术会”线下技术沙龙,本次技术会的主题是“云原生落地探索与实践”,邀请快手、百度和字节跳动的技术专家,与爱奇艺技术产品团队共同分享与探讨云原生落地的实践经验。
其中,来自爱奇艺的技术专家赵慰为大家带来了爱奇艺容器实践的分享,讲述了爱奇艺的容器应用场景和在容器网络、容器运行时方面的实践经验。
本场分享的主要内容包括爱奇艺近年来在容器方面的实践经验和遇到过的问题,以及我们在选型和探索过程中的一些心路历程。
爱奇艺容器应用场景
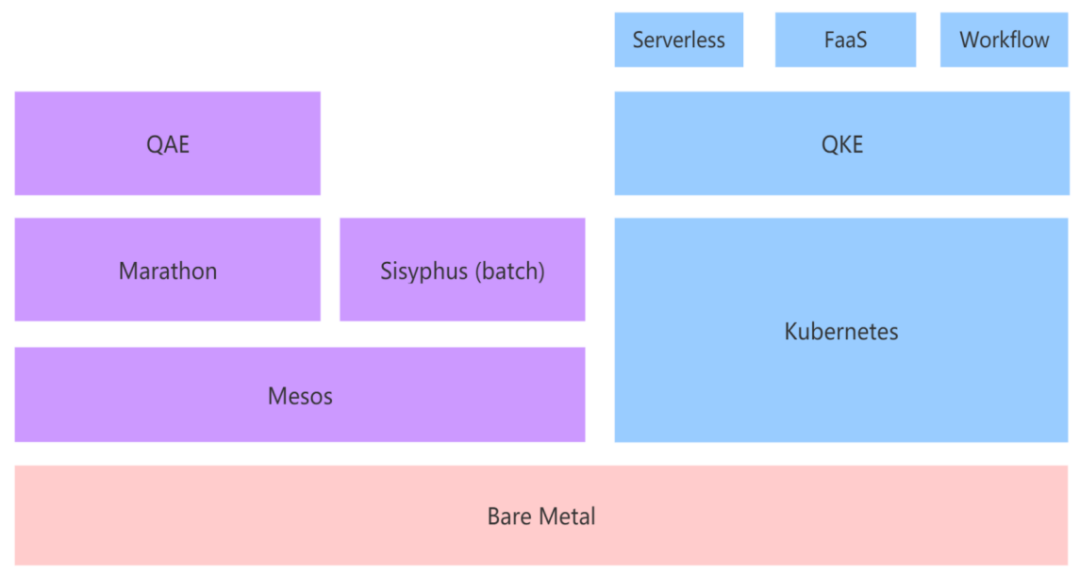
爱奇艺内部超过一半的应用实例正在以容器形式运行,这些容器基本都运行在物理机集群上面。最初爱奇艺采用 Mesos 框架、基于 Mesos 的开源服务调度框架 Marathon 和自研批处理框架 Sisyphus,并基于 Marathon 研发了 QAE(iQIYI App Engine)。当时,大量公司以 Mesos/Marathon 为基础做着类似的事情。前不久,有消息表明 Mesos 即将从 Apache 光荣退休,而 Twitter 贡献的著名 Mesos 调度框架 Aurora 项目也早在去年二月份就已进入 Apache 退役名单。对于 Mesos 的告别,我们感到非常遗憾,同时也加快了向 Kubernetes 转型的脚步。爱奇艺在 Kubernetes 方面起步较晚,之后除提供原生 K8S 服务之外,我们还会进一步在 K8S 基础上提供不同抽象级别的应用引擎,包括 Serverless、FaaS、workflow 等,希望以后能够有机会和大家分享我们后续的工作。
容器网络实践
爱奇艺容器网络应用的发展如图所示:
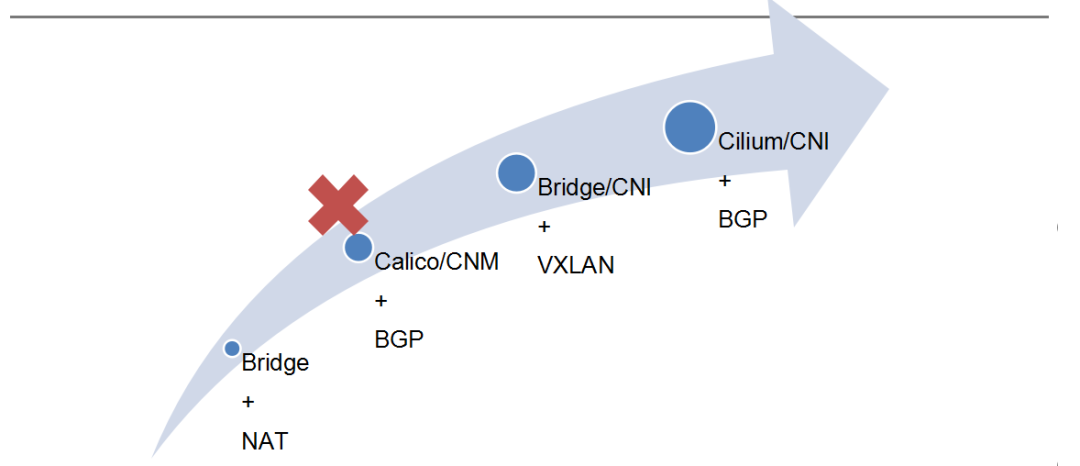
我们在 Mesos 框架用的最多的是 Docker 原生的 local Bridge + NAT,于 2014 年投入使用,现在还在大量运行;中途尝试过 Calico,然而当时 Docker 和 K8S 等组织有关容器网络标准的争论导致我们无法全力投入某种技术,加之管理难度的限制,最终导致 Calico 方案并没有在爱奇艺大规模应用;后来发展 K8S 时,由于之前 NAT 策略在应用上不太友好,所以我们定了一个基础方向,将容器网络跟内网打通,并选了一些具体实现方法,比如 VXLAN、Calico/CNI。后来 Cilium 出现,并在一些公司得到应用,大家比较感兴趣;既然我们起步已经晚了,倒不如直接采用一些激进的新方案奋起直追。
可能有些同学对 CNM(Container Network Model,容器网络模型)和 CNI(Container Network Interface,容器网络接口)的容器标准之争不太了解,下面做一个简单的解释:
Docker 将自己的网络方面剥离出一个独立项目 libnetwork 并提出了 CNM,定义了网络、接入点等概念以及创建网络、加入网络等操作,允许第三方插件按照标准与 Docker 对接;CoreOS 则提出了更为简单的 CNI,只定义了往网络里面加减容器的接口标准。当时对于两款接口的使用,两家公司各执一词。对于 K8S 方来说,他们觉得 CNM 的接口和 Docker 的结合过于紧密,所定的用户操作标准也过于复杂,CNI 相比 CNM 来说更加安全、简单、松耦合;Docker 方对此的官方回复是,K8S 等社区的意见和建议不符合 Docker 的整体设计。最终 K8S 选择了 CNI 作为网络方案。现在 CNI 在行业应用中占据主导地位,但对于插件来说,无论对哪个接口,所做的工作内容都是差不多的,例如 CNM 要求网络配置要通过 Docker 的 libKV 存储,而 CNI 没有这方面的要求,但对于网络插件来说,它的存储总是要有的,只不过由插件自己管理或由 K8S 统一管理对于 K8S 用户来说更加方便。
(1)Bridge + NAT
回到 Mesos 环境中。由于当时 Mesos 还没有很好地支持 CNI,而爱奇艺在使用 CNM 中遇到了很多管理和运维上的困难,最简单可靠的 Bridge + NAT 方案成为了唯一选择。当时我们想的也比较简单、理想化,认为不管走 NAT 还是不走 NAT,在服务注册发现把这些信息掩饰掉就好。但在长期的实践中,这层 NAT 还是给我们的运维工作带来了无比多的烦恼。
我们遇到的常见问题包括 RPC 暴露服务地址、排障时 IP PORT 查应用不能正常使用、Nginx Keepalive 失效等。另外还有一些偶发问题比如网卡无法释放、IP 冲突等等,但整体来说还是比较可靠。
Nginx Keepalive 失效是这几个问题里面比较棘手的一个。
问题:多个 RS,通过 Nginx 代理请求,QPS 极低,偶发 502,有一定规律复现。
解决:
1)抓包:——Nginx:502 时,直接收到 RST;
——RS 容器内:中间发送过 FIN,502 时没有包。
2)解决:
推测几个可能性:
——iptables 有 bug——然而相关文章表明,这种情况只会小概率出现并不会稳定出现,不太符合这个 bug 的现象,而且该服务使用短链接访问 FIN 正常,故排除此原因;
——bridge 网络问题:小概率出现,同样不符合;
——iptables NAT 规则问题:继续抓包,从 RS 容器发出的 FIN 包入手,主机上被没有处理,进而发现时主机 NAT 表里已经没有了 Nginx 到 RS 的连接转换规则,联系到低频请求的情况,最终判断为是 RS 空闲超时后主动断开 keepalive 连接,而 Nginx 并不知情仍尝试使用旧连接导致访问失败。
这个问题没有完美的解决方案,缓解思路有几个:
1)将内核参数 net.netfilter.nf_conntrack_tcp_timeout_established 调大,使 NAT 规则容忍的空闲时间超过 RS 容忍的空闲连接时间;
2)Nginx 或其他客户端使用 Keepalive 时使用 TCP 心跳等机制维持连接;
3)全部使用短连接请求。
(2)Bridge/CNI + VXLAN
应用 K8S 之后,一开始爱奇艺尝试了 Bridge/CNI + VXLAN。对于二层网络,K8S 官方至今没有给出最佳实践方案。我们只了解到类似 GCE 等公有云通过这种方式使用,但整个工作应该和 Docker 早期一个叫 pipework 的工具差不多,还是比较简单好用的。
在应用过程中也遇到过一些问题:
问题:该模式下,Pod 内访问 Service IP 的请求如果被转发到同节点的实例,则收不到响应。
解决:这个问题是也和 iptables 有关,如果内核参数 net.bridge.bridge-nf-call-iptables 值为 1,则数据包会经过主机 iptables 处理并遗憾丢失。将参数开机置为 0 后,仍发现各节点的参数值为 1;经过一系列排查,最终发现是 Docker 启动时会加载除 bridge 外还加载 br_netfilter 模块,同时修改参数为 1。于是将 br_netfilter 设置为开机加载,加之内核参数开机置 0,问题即被解决。另一个解决思路是,放弃 Docker,更换为 Containerd。
(3)Cilium/CNI + BGP
Cilium 这部分是比较冒险的一个尝试,它的工作原理简单而言,就是把一些工作通过 eBPF 机制实现到内核里。这种程序本身不会比普通程序执行更快,但它大大缩短了执行路径。
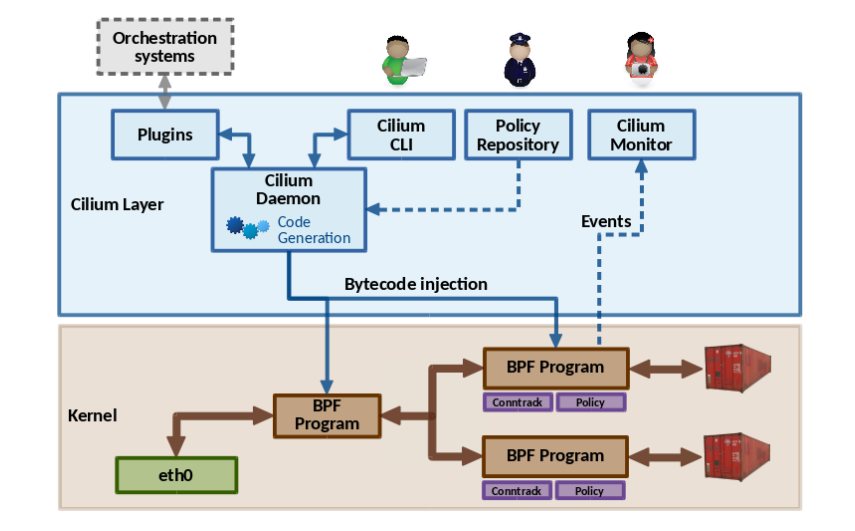
(图片来自网络)
与 Bridge/CNI + VXLAN 相比,Cilium/CNI + BGP 涉及到整个基础网络环境的改动。其中 IPAM 和 BGP 与网络规划密切相关。
IPAM 的思路一般有完全分布式的 CIDR per host 或集中式的 CIDR per IDC、global CIDR 几种。各种选择都有利弊,比如 CIDR per host 的路由表虽然简单,但 IP 漂移局限性较大,并且会因为碎片化浪费大量 IP;而 CIDR per IDC、global CIDR 方案 IP 漂移局限性小,也能节省 IP,但会导致路由表变得即为庞大难以维护。经协调,我们最终决定按照 TOR 做规划,尽可能在路由复杂度、IP 资源与灵活性之间做出权衡。具体的网络规划涉及保密信息,此处不便展开。
BGP 配置涉及到交换机和主机较大的改动。宿主机延续了之前的双物理网卡 HA 设计,通过分别于两个交换机建立 BGP 连接,并建立等价路由,既能提升网络带宽又能在一定程度保障网络高可用。
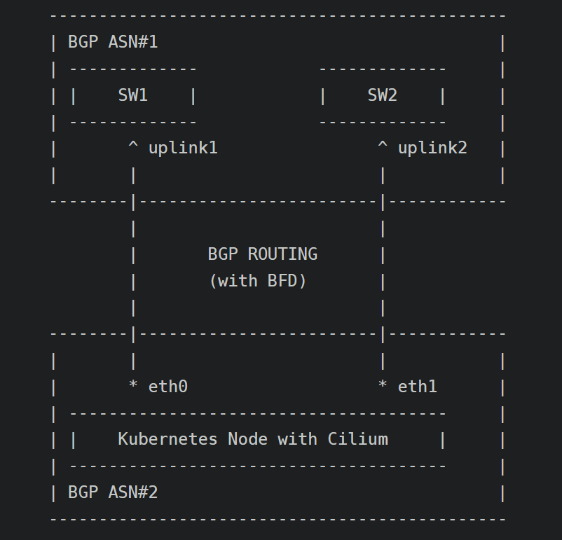
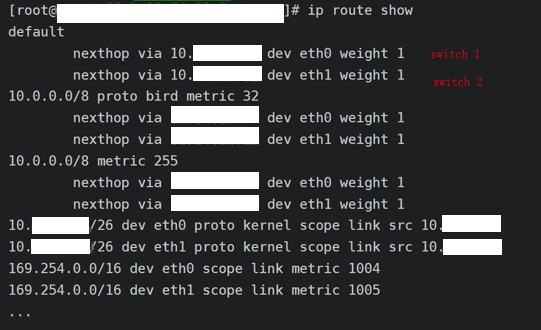
(4)Bridge/CNI + Cilium/CNI 混合部署
问题:——Cilium + BGP 改造周期长,不能及时满足交付时间;
——Cilium 技术本身潜在风险,需要准备快速恢复的方案;
——存量 Bridge 集群平滑迁移到 Cilium。
解决:——Bridge、Cilium 在内网网段统一规划,跨节点走交换机;
——为不同网络节点打标签,通过 Daemon Set 部署 CNI Agent。
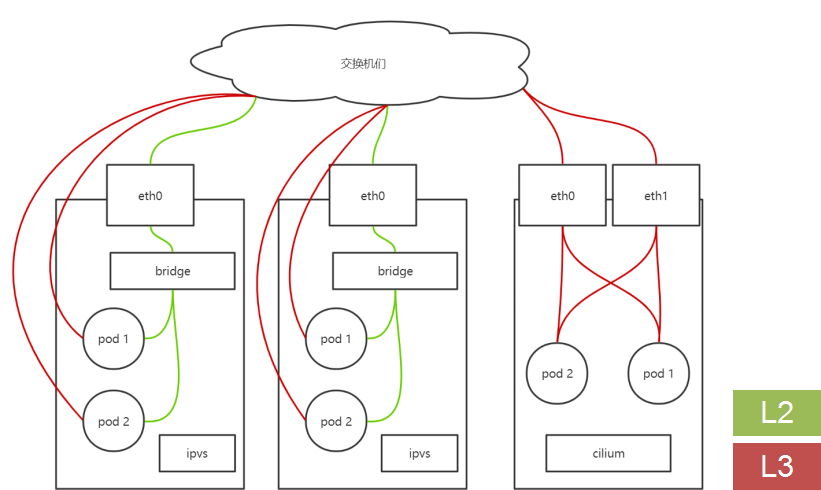
如图,绿色线是二层网络,红色三层数据通路。
容器运行时
在容器运行时这方面,爱奇艺也做过很多的尝试。使用最早也是最多的当然是 Docker;有一段时间曾尝试过 Mesos Unified Container;最后在 K8S 环境里选择了 Containerd + RunC/Kata。
Docker Daemon 早期的工作模式和稳定性为很多使用者所诟病;后来我们为更好地保持集群和容器状态一致性,尝试使用 Mesos 推出的 Unified Container,然而遇到的问题并不比 Docker 少太多。由于当时镜像、容器的存储可靠性和使用效率不尽人意,以及缺少排障工具等等原因,这段尝试最终告一段落,当然现在还有一些特殊的应用场景仍在沿用这个环境。
这篇文章要分享的方案主要还是 Containerd + RunC/Kata。
使用容器时经常要被以下几个问题困扰:
首先,容器的隔离性并不充分,容器之间会有一定程度的相互影响,很多情况下,一个容器出问题会导致整个主机的运行瘫痪。比如我们之前遇到过一些问题,一个容器中的进程数飙升导致整个宿主机 load 升高,并伴随着高频的线程切换,这种情况 cgroup 的简单限制无法帮助其他容器正常运行;另外还遇到过一些低级错误,例如请求完忘记关掉连接,导致很快耗尽 FD 进而整机故障;
其次,容器内检测到的资源通常为宿主机的资源,比如有些 JAVA 程序通过检测 CPU、内存来自动适配自己的线程数等运行状态。当然 Java 等也都在逐渐往适配容器的方向发展,但效果还不是太理想;
最后是安全需求,比如各种资源的可见性、可访问性控制。
解决以上问题的一个常见思路是将容器放在虚拟机内运行。实际应用中要突破两个点,一是虚拟机要尽可能轻量、启动快,二是与方便使用、与 Kubernetes 等方便集成。
容器运行时的实践
(1)Kata
(图片来自网络)
爱奇艺接触英特尔 Clear Containers 比较早,但一直没有正式应用过,只是做了一些简单的试验,类似还包括 HYPER;两个项目最后合并成了 Kata Containers,将原来的虚机进行最大程度的精简但不影响使用。Kata 同样遵守 OCI 标准,能够与外部控制器交互,比如 Containerd 或者自身 CLI。
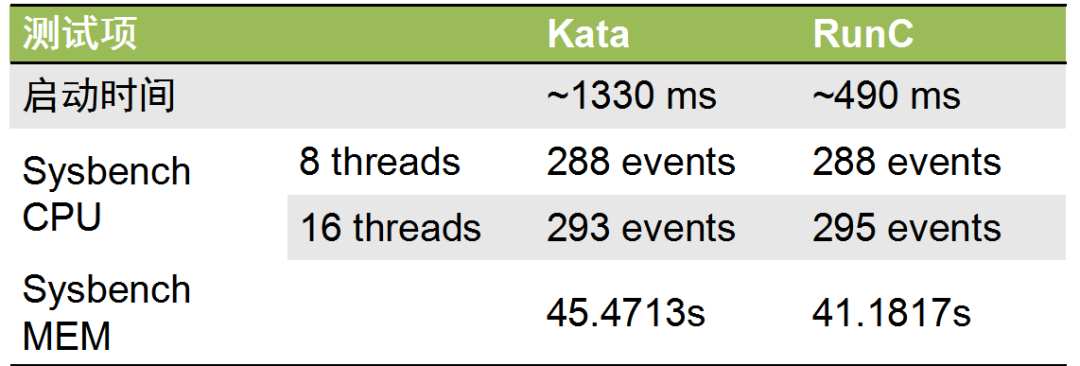
图注:测试 Kata 与 RunC 的性能
我们对 Kata 进行了一系列基准测试。根据测试结果,可以看出两者的启动时间相差不多,Kata 一秒多一点,RunC 是半秒,在实际应用中对毫秒级启动的需求也没有那么多,是完全可以接受的差距。而 CPU 测试是使用了经典的素数计算,计算 2,000,000 个素数,8 线程,运行 60 秒,看能运转多少轮;内存测试的大小为 100G。整体来看 Kata 比 RunC 稍微慢了一点点。
值得注意的是,实际应用场景中表现出来的性能通常与基准测试有一定差距。比如我们深度学习的图片推理场景进行测试,Kata 相比 RunC 有 5%到 10%的损耗,勉强在可接受范围之内,但是如果要规模应用,还需要进一步优化。
不过,Kata 本身因为套了一层虚机,实际应用还有一些限制,列举如下:
·需要 CPU 开启 vmx 虚拟化支持
·不支持 host 网络模式
·不支持加入其它容器 network namespace
·不支持 docker checkpoint、restore 功能
·不完全支持 events,例如不支持 OOM notification
·Update command 不支持 block IO weight
·不支持 docker run 参数 --shm-size 设定共享内存
·不支持 docker run 参数 –sysctl 等
在实际应用时,除了不支持 host 网络模式偶尔对我们有一些影响之外,其他限制基本没有影响。
(2)gVisor
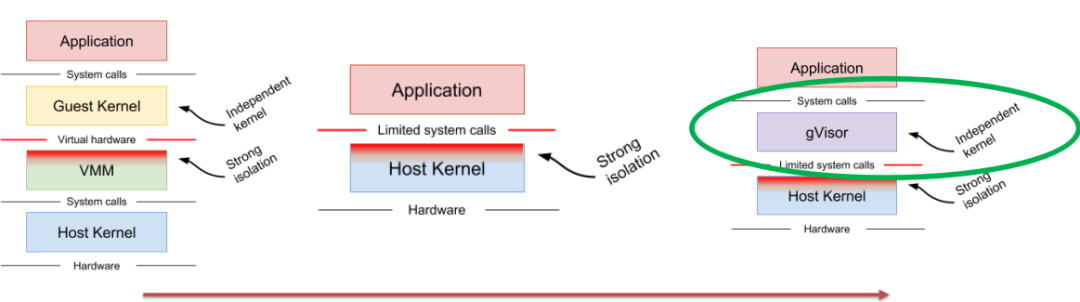
(图片来自网络)
gVisor 是轻量虚拟化的另一个选项,由谷歌推出,使用 Golang 开发了一个“高仿”内核。在极致性能的同时,也带来了一些兼容性问题。
在这里放上它的官方文档和兼容性描述连接:
兼容性:https://gvisor.dev/docs/user_guide/compatibility/
爱奇艺没有选择 gVisor 的原因是很多目前生产环境中的必需的工具它暂时无法完美支持,比如 IP、SSHD、netstat 等命令。
(3)Containerd + RunC/Kata
Containerd 与 RunC 的关系:
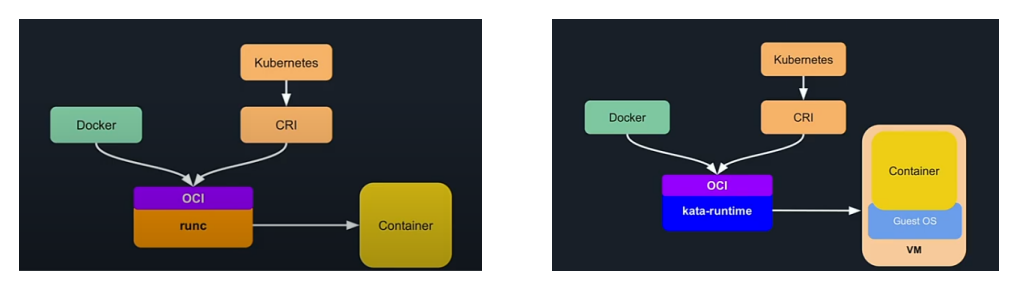
(图片来自网络)
简单解释一下,OCI 是 Docker 领衔推出的开放容器标准,定义了镜像、容器运行时、镜像仓库规范。只要 Kata 和 RunC 都按照 OCI 去实现接口,就基本可以直接进行替换。替换过程如果用 Docker 会繁琐一些,但是用 Containerd 会非常简单。
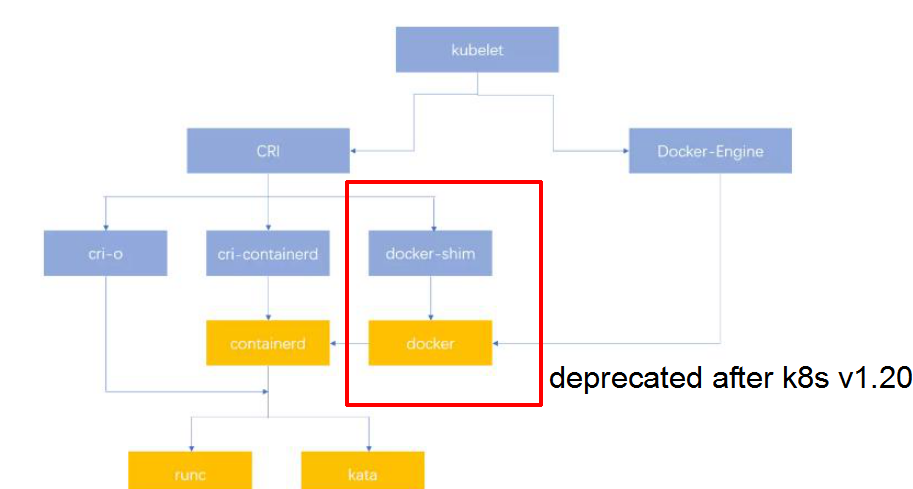
(图片来自网络)
前一段时间,Kubernetes 自 v1.20 之后将 Docker 标记为 Deprecated 状态的声明一度引起恐慌;但从目前的情况来看,使用 Containerd 替换 Docker + Shim 已经是一个很简便的操作。
有了以上基础,在 Kubernetes 中使用 Kata 就变得很简单。首先要有一个 K8S 的 Runtime Class,在 Containerd 上加上 Runtime Class 的相应配置:

最后在 Pod Spec 中指定 Kata:

应用场景
互联网行业普遍面临的一个问题是服务器资源利用率比较低。即使在午高峰、晚高峰等时间段,整体利用率也不尽如人意。截图是某个集群 24h 内的 CPU 利用率监控统计。如图所示,红色框中的突起部分,是我们稍微做了一些工作去解决这个问题,比如晚上去运行一些任务;由于是随机选取一天,看起来比日常平均优化效果略差一些。
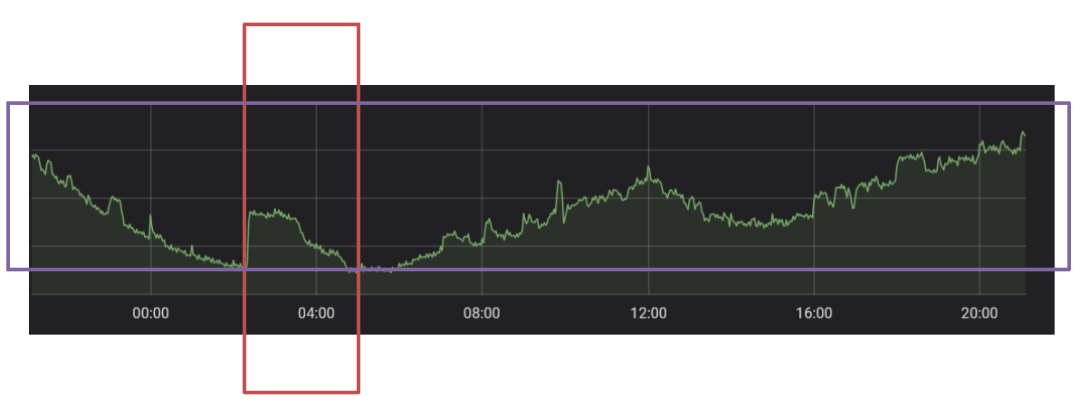
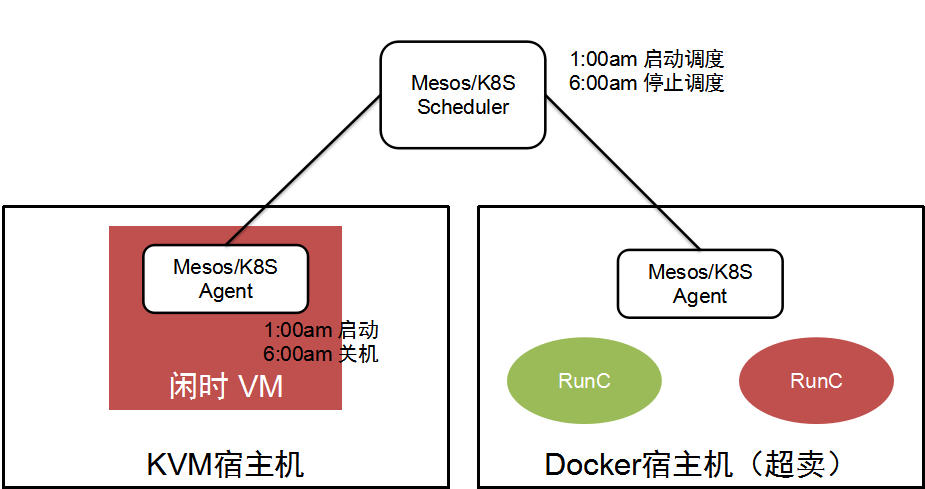
如图所示,目前方案以 Mesos 为主,同时管理 KVM 和 Docker 宿主机。虚机的部分比较简单粗暴,在每台宿主机上使用空闲资源(按照实际利用率)创建合适规格的虚拟机,在夜间启动、凌晨关闭;Docker 部分则利用 Mesos 灵活的资源超卖能力,为超卖资源分配单独的 Role。两种资源统一由 Mesos 管理,并交由任务调度系统使用,为避免影响到常规负载,调度时间同样控制在半夜 1 点到 6 点。
在 K8S + Kata/RunC 的环境中,事情会变得简单一些。这得益于 K8S 提供的比较可靠的纵向、横向伸缩能力,和 Kata 提供的较强的性能隔离特性。虚机由于创建时对资源调度的控制并不精确,白天使用可能会对常规虚机性能造成较大影响,因此仍然保持仅在夜间运行。容器方面 RunC 的部分就是正常的调度,而 Kata 用来运行一些转码等离线任务;整体资源由 K8S 统一控制,避免多个资源和任务管理框架在服务器控制上产生冲突。
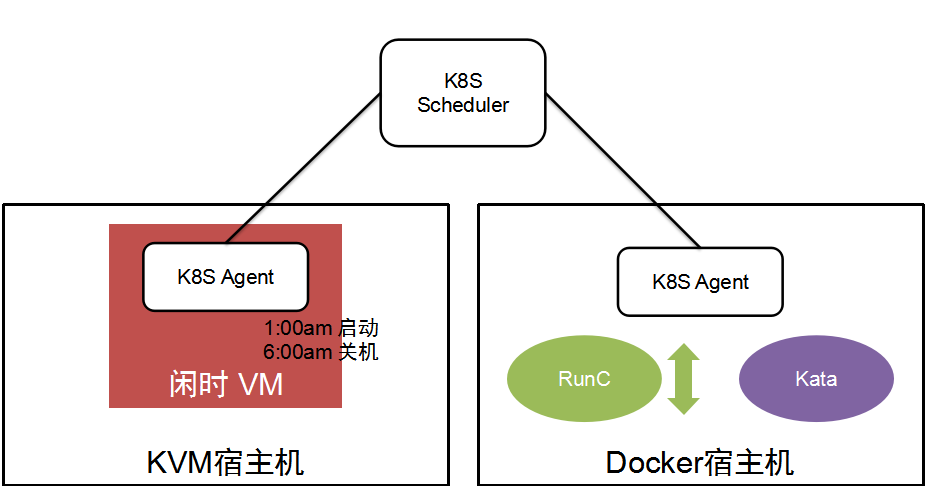
爱奇艺在 K8S 在线离线混部方面的工作才刚刚起步,希望在过去 Mesos 混部的基础上做出精细化的运作,并进一步提升服务器利用率。
本文转载自:爱奇艺技术产品团队(ID:iQIYI-TP)
原文链接:爱奇艺容器实践




