
摘要
最近,关于数据科学家的工作应该包含哪些,有许多激烈的讨论。许多公司都希望数据科学家是全栈的,其中包括了解比较底层的基础设施工具,如 Kubernetes(K8s)和资源管理。本文旨在说明,虽然数据科学家具备全栈知识有好处,但如果他们有一个良好的基础设施抽象工具可以使用,那么即使他们不了解 K8s,依然可以专注于实际的数据科学工作,而不是编写有效的 YAML 文件。
正文
最近,关于数据科学家的工作应该包含哪些,有许多激烈的讨论(1、2、3)。许多公司都希望数据科学家是全栈的,其中包括了解比较底层的基础设施工具,如 Kubernetes(K8s)和资源管理。
本文旨在说明,虽然数据科学家具备全栈知识有好处,但如果他们有一个良好的基础设施抽象工具可以使用,那么即使他们不了解 K8s,依然可以专注于实际的数据科学工作,而不是编写有效的YAML文件。
本文是基于这样一个假设,即对于全栈数据科学家的期望来自这些公司开发和生产环境的巨大差异。接下来,本文讨论了消除环境差异的两个步骤:第一步是容器化;第二步是基础设施抽象。
对于容器化,人们或多或少都有所了解,但基础设施抽象是相对比较新的一类工具,许多人仍然把它们和工作流编排弄混。本文最后一部分是比较各种工作流编排和基础设施工具,包括 Airflow、Argo、Prefect、Kubeflow 和 Metaflow。
Roles and Responsibilities:
Automate horrible business practices
Write ad hoc SQL as needed
REQUIRED EXPERIENCE:
15 years exp deep learning in Python
PhD thesis on Bayesian modeling
NLP experience in 7 languages
10 years of creating Hadoop clusters from scratch
— Nick Heitzman (@NickDoesData) February 12, 2019 Requirementsfor data scientists in real-time Network latency from VermontTworeal-life data scientist job descriptions

两份真实的数据科学职位描述
目录
全栈的期望
开发和生产环境分离
消除差异第一步:容器化
消除差异第二部:基础设施抽象
工作流编排 vs. 基础设施抽象
工作流编排:Airflow vs. Prefect vs. Argo
基础设施抽象:Kubeflow vs. Metaflow
注意
生产是一个范畴。对于有些团队,生产意味着从笔记本生成的结果生成漂亮的图表向业务团队展示。对于其他团队,生产意味着保证每天服务于数百万用户的模型正常运行。在第一种情况下,生产环境和开发环境类似。本文提到的生产环境更接近于第二种情况。
本文不是要论证 K8s 是否有用。K8s 有用。在本文中,我们只讨论数据科学家是否需要了解 K8s。
本文不是要论证全栈没用。如果你精通这个管道中的每个部分,我认为会有十几家公司当场雇用你(如果你允许的话,我也会努力招募你)。但是,如果你想成为一名数据科学家,不要想着要掌握全栈。
全栈的期望
大约 1 年前,我在推特上罗列了对于一名 ML 工程师或数据科学家而言非常重要的技能。该列表几乎涵盖了工作流的每一部分:数据查询、建模、分布式训练、配置端点,甚至还包括像 Kubernetes 和 Airflow 这样的工具。
如果我想自学成为一名 ML 工程师,那么我会优先学习下列内容:
版本控制
SQL + NoSQL
Python
Pandas/Dask
数据结构
概率 & 统计
ML algos
并行计算
REST API
Kubernetes + Airflow
单元/集成测试
——— Chip Huyen (@chipro),2020 年 11 月 11 日
这条推特似乎引起了我的粉丝的共鸣。之后,Eugene Yan 给我发消息说,他也撰文讨论了数据科学家如何在更大程度上做到端到端。Stitch Fix 首席算法官 Eric Colson(之前是 Netflix 数据科学和工程副总裁)也写了一篇博文“全栈数据科学通才的强大与职能分工的危险性”。
在我发那条推特时,我认为 Kubernetes 是 DS/ML 工作流必不可少的部分。这个看法源于我在工作中的挫败感——我是一名 ML 工程师,如果我能更熟练地使用 K8s,那么我的工作会更简单。
然而,随着对底层基础设施了解的深入,我认识到,期望数据科学家了解这些并不合理。基础设施需要的技能集与数据科学的需求完全不同。理论上,你可以都学。但实际上,你在一个方面花的时间多,在另一个方面花的时间肯定就少。我很喜欢 Erik Bernhardsson 打的那个比方,期望数据科学家了解基础设施就像期望应用开发人员了解Linux内核的工作原理。我成为数据科学家,是因为我想把更多时间花在数据上,而不是花在启动 AWS 实例、编写 Dockerfile、调度/扩展集群或是调试 YAML 配置文件。
开发和生产环境分离
那么为什么会有这种不合理的预期?
在我看来,一个原因是数据科学的开发和生产环境之间存在着很大的差别。开发和生产环境之间有许多不同的地方,但是有两个关键的差异使得数据科学家不得不掌握两个环境的两套工具,那就是规模和状态。

在开发过程中,你可能会启动一个 conda 环境,使用 notebook,借助 pandas 的 DataFrame 操作静态数据,借助 sklearn、PyTorch 或 TensorFlow 编写模型代码,运行并跟踪多个实验。
一旦对结果满意了(或是没时间了),你就会选取最好的模型将其投入生产应用。将模型投入生产应用基本上是说“将其从开发环境移到生产环境”。
幸运的话,开发环境中的 Python 代码可以在生产环境中重用,你所要做的是将 notebook 代码粘贴复制到合适的脚本中。如果运气不好,你可能需要将 Python 代码用 C++或公司在生产环境中使用的其他语言来重写。依赖项(pandas、dask、PyTorch、TF 等)就需要在运行模型的生产实例上重新打包和生成。如果你的模型服务于大量的流量,并且需要大量的计算资源,那么你可能需要进行任务调度。之前,你需要手动启动实例,或是在流量比较小的时候关闭实例,但现在,大部分公有云提供商都帮我们做了这项工作。
在传统软件开发中,CI/CD 可以帮助我们弥补这种差距。精心开发的测试集让我们可以测出在本地进行的修改到生产环境会产生什么行为。不过,对于数据科学而言,只有 CI/CD 还不够。除此之外,生产环境中的数据分布一直在变化。不管你的 ML 模型在开发环境中效果多好,你都无法确定它们在实际的生产环境中表现如何。
由于存在这种差别,所以数据科学项目会涉及两套工具:一套用于开发环境,一套用于生产环境。
消除差异第一步:容器化
容器化技术,包括 Docker,其设计初衷就是为了帮助我们在生产机器上重建开发环境。使用 Dokcer 的时候,你创建一个 Dockerfile 文件,其中包含一步步的指令(安装这个包,下载这个预训练的模型,设置环境变量,导航到一个文件夹,等等),让你可以重建运行模型的环境。这些指令让你的代码可以在任何地方的硬件运行上运行。
如果你的应用程序做了什么有趣的事情,那么你可能需要不只一个容器。考虑这样一种情况:你的项目既包含运行速度快但需要大量内存的特征提取代码,也包含运行速度慢但需要较少内存的模型训练代码。如果要在相同的 GPU 实例上运行这两部分代码,则需要大内存的 GPU 实例,这可能非常昂贵。相反,你可以在 CPU 实例上运行特征提取代码,在 GPU 实例上运行模型训练代码。这意味着你需要一个特征提取实例的容器和一个训练实例的容器。
当管道的不同步骤存在相互冲突的依赖项时,也可能需要不同的容器,如特征提取代码需要 NumPy 0.8,但模型需要 NumPy 1.0。
当存在多个实例的多个容器时,你需要建立一个网络来实现它们之间的通信和资源共享。你可能还需要一个容器编排工具来管理它们,保证高可用。Kubernetes 就是干这个的。当你需要更多的计算/内存资源时,它可以帮助你启动更多实例的容器,反过来,当你不再需要它们时,它可以把它们关掉。
目前,为了协调开发和生产两个环境,许多团队选择了下面两种方法中的一种:
由一个单独的团队管理生产环境
在这种方法中,数据科学/ML 团队在开发环境中开发模型。然后由一个单独的团队(通常是 Ops/Platform/MLE 团队)在生产环境中将模型生产化。这种方法存在许多缺点。
增加沟通和协调开销:不同的团队之间可能相互妨碍。按照 Frederick P. Brooks 的说法是,一名程序员一个月可以完成,两名程序需要两个月。
增加调试难度:当出现问题时,你不知道是自己团队的代码导致的,还是其他团队的代码导致的。可能根本就和你团队的代码无关。你需要和多个团队一起才能找出问题所在。
相互指责:即使你弄清楚了问题出在哪里,每个团队也可能会觉得另一个团队应该负责修复。
窄语境:没有人了解整个过程,也就无法对总体流程进行优化/改进。例如,平台团队知道如何改进基础设施,但他们只会应数据科学家的请求来做工作,但数据科学家并不一定要与基础设施打交道,所以他们不关心。
数据科学家拥有整个过程
在这种方法中,数据科学团队还需要考虑如何将模型投入生产应用。数据科学家变成了脾气暴躁的独角兽,人们期望他们了解这个过程中的所有工作,与数据科学相比,他们最终可能要写出更多的样板代码。
消除差异第二步:基础设施抽象
如果我们有一种抽象方法,让数据科学家可以拥有端到端的过程,而又不必担心基础设施的问题,会怎么样?
如果我可以直接告诉工具:这里是我存储数据的地方(S3),这里是我运行代码的步骤(特征提取、建模),这里是我运行代码的地方(EC2 实例、AWS Batch、Function 等无服务器类的东西),这里是我的代码在每一步需要运行的东西(依赖项)。然后这个工具会为我管理所有基础设施相关的工作,那会怎么样?
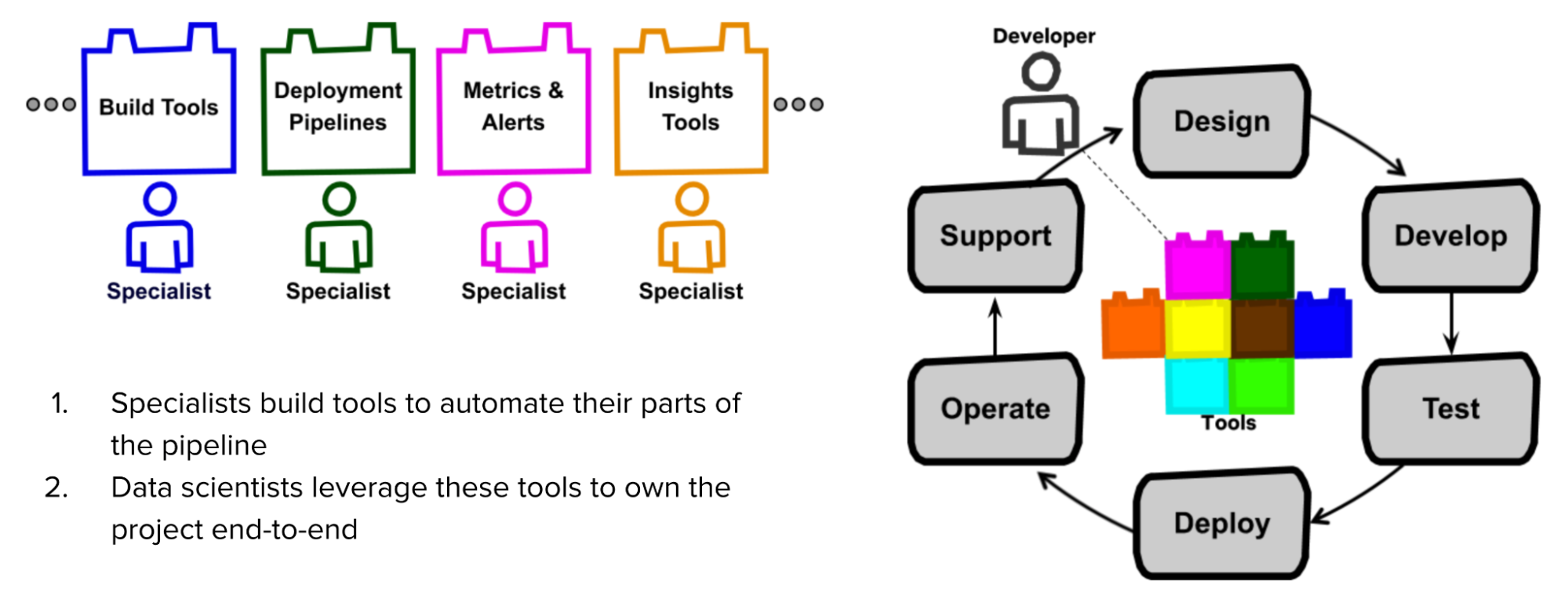
根据 Stitch Fix 和 Netflix 的说法,全栈数据科学家的成功依赖于他们拥有的工具。他们需要的工具应该能够“将数据科学家从容器化、分布式处理、自动故障转移及其他复杂的高级计算机科学概念中抽离出来”。
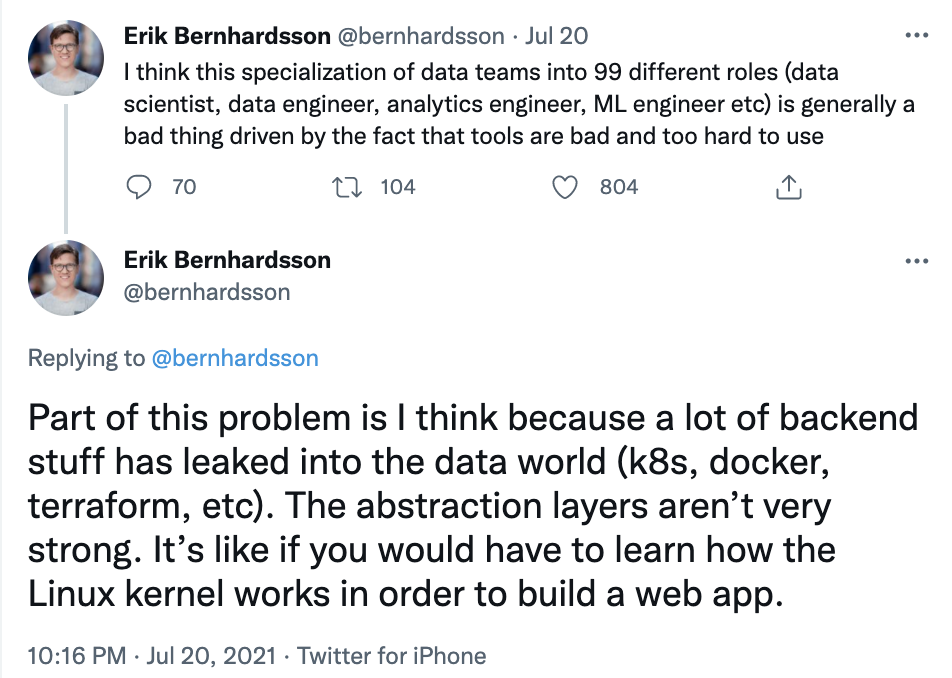
在Netflix的模型中,专家——那些原本就拥有部分项目的人——首先创建了使自己那部分自动化的工具。数据科学家可以利用这些工具来实现自己项目的端到端。
Netflix 的全生命周期开发人员
好消息是,你不在 Netflix 工作也可以使用他们的工具。两年前,Netflix 开源了Metaflow,这是一个基础设施抽象工具,使他们的数据科学家能够开展全栈工作,而不必担心底层基础设施。
对于大多数公司来说,数据科学对基础设施进行抽象的需求是一个相当新的问题。这主要是因为,以前在大多数公司,数据科学工作的规模并没有达到让基础设施成为问题的程度。基础设施抽象主要是在云设置相当复杂的时候才有用。从中受益最多的公司是那些拥有数据科学家团队、大型工作流程和多个生产模型的公司。
工作流编排 vs. 基础设施抽象
因为对基础设施进行抽象的需求是最近才出现的问题,所以其前景尚不确定(而且极其混乱)。你是否曾经疑惑,Airflow、Kubeflow、MLflow、Metaflow、Prefect、Argo 等之间到底有什么区别,并不是只有你有这种感觉。Paolo Di Tommaso 的awesome-pipeline存储库中有近 200 个工作流/管道工具包。其中大多数是工作流编排工具,而不是基础设施抽象工具,但是,人们对这两类工具多有混淆,让我们看看它们之间的一些关键的相似性和差异。
强烈建议企业不要在工具名称中使用“flow”
造成这种混乱的一个原因是,所有这些工具的基本概念都相同。它们都把工作流程当作一个 DAG,即有向无环图。工作流程中的每一个步骤都对应图上的一个节点,而步骤之间的边表示这些步骤的执行顺序。它们的不同之处在于如何定义这些步骤,如何打包它们以及在哪里执行。
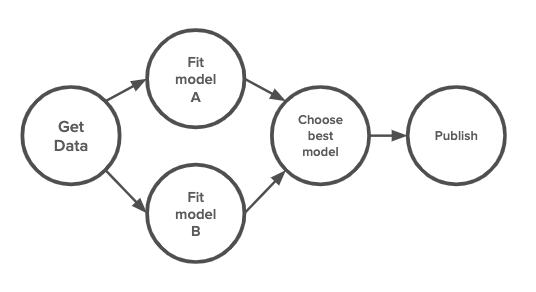
工作流的 DAG 表示
工作流编排:Airflow vs. Prefect vs. Argo
Airflow 最初是由 Airbnb 开发的,于 2014 年发布,是最早的工作流编排器之一。它是一个令人赞叹的任务调度器,并提供了一个非常大的操作符库,使得 Airflow 很容易与不同的云提供商、数据库、存储选项等一起使用。Airflow 是“配置即代码”原则的倡导者。它的创建者认为,数据工作流很复杂,应该用代码(Python)而不是 YAML 或其他声明性语言来定义。(他们是对的。)
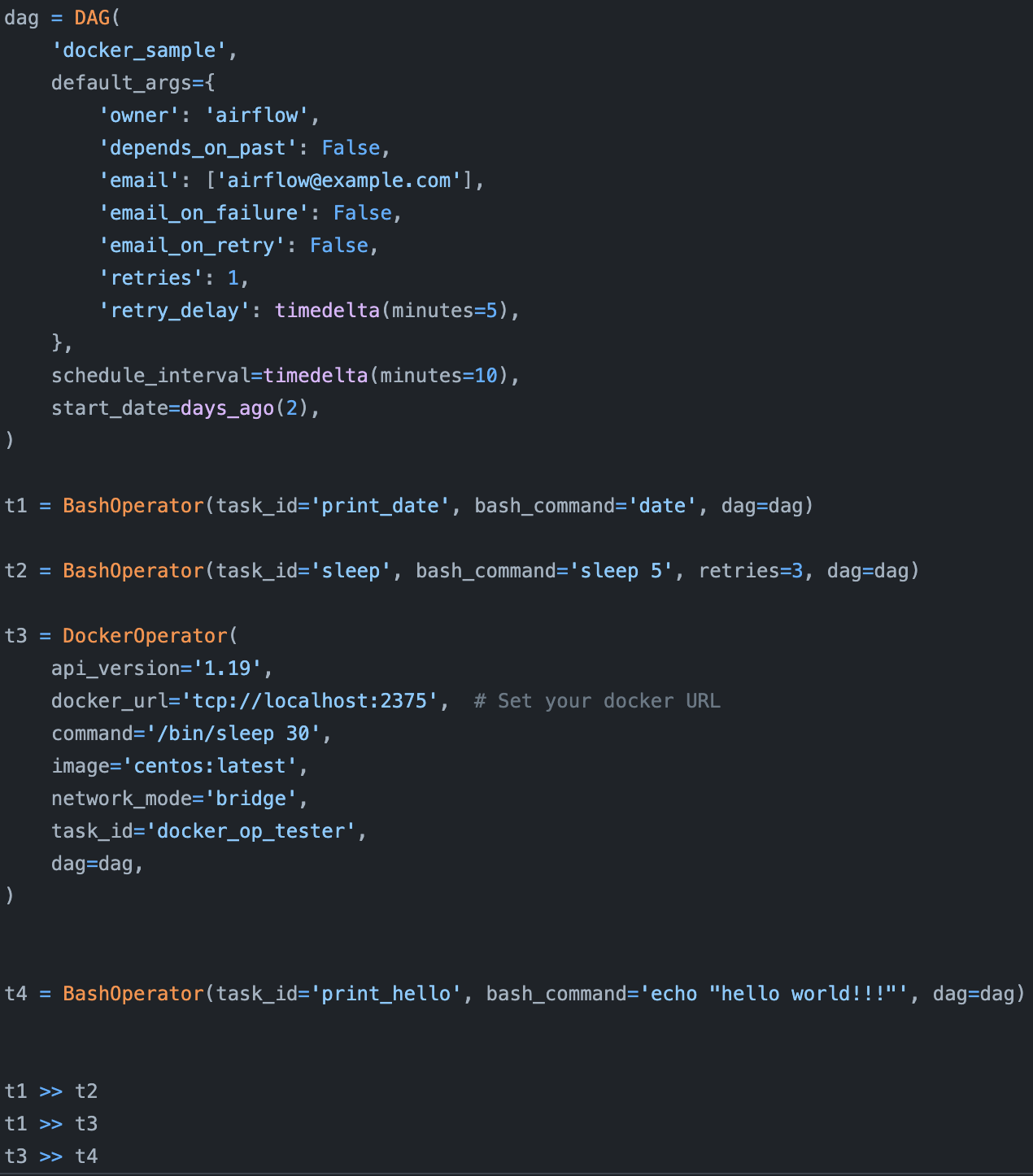
Airflow 中一个使用了 DockerOperator 的简单工作流。本示例来自 Airflow 存储库。
然而,由于比其他大多数工具创建得更早,所以 Airflow 没有任何工具可以借鉴,并因此有很多缺点,Uber 工程公司的这篇博文对此做了详细讨论。在这里,我们只介绍其中三个,让你大概有个了解。
首先,Airflow 是单体的,这意味着它将整个工作流程打包成了一个容器。如果你的工作流程中存在两个不同步骤有不同的要求,理论上,你可以使用 Airflow 提供的DockerOperator创建不同的容器,但这并不容易。
第二,Airflow 的 DAG 没有参数化,这意味着你无法向工作流中传入参数。因此,如果你想用不同的学习率运行同一个模型,就必须创建不同的工作流。
第三,Airflow 的 DAG 是静态的,这意味着它不能在运行时根据需要自动创建新步骤。想象一下,当你从数据库中读取数据时,你想创建一个步骤来处理数据库中的每一条记录(如进行预测),但你事先并不知道数据库中有多少条记录,Airflow 处理不了这个问题。
下一代工作流编排器(Argo、Prefect)就是为了解决 Airflow 不同方面的缺点而创建的。
Prefect 首席执行官 Jeremiah Lowin 是 Airflow 的核心贡献者。他们在早期的营销活动中对 Prefect 和 Airflow 做了强烈的对比。Prefect 的工作流实现了参数化,而且是动态的,与 Airflow 相比有很大的改进。它还遵循 “配置即代码”的原则,因此工作流是用 Python 定义的。
然而,像 Airflow 一样,容器化步骤并不是 Prefect 的首要任务。你可以在容器中运行每个步骤,但仍然需要处理 Dockerfile,并在 Prefect 中注册工作流 docker。
Argo 解决了容器的问题。在 Argo 的工作流程中,每一步都在自己的容器中运行。然而,Argo 的工作流是用 YAML 定义的,这让你可以在同一个文件中定义每个步骤及其要求。但 YAML 会让你的工作流定义变得混乱,难以调试。
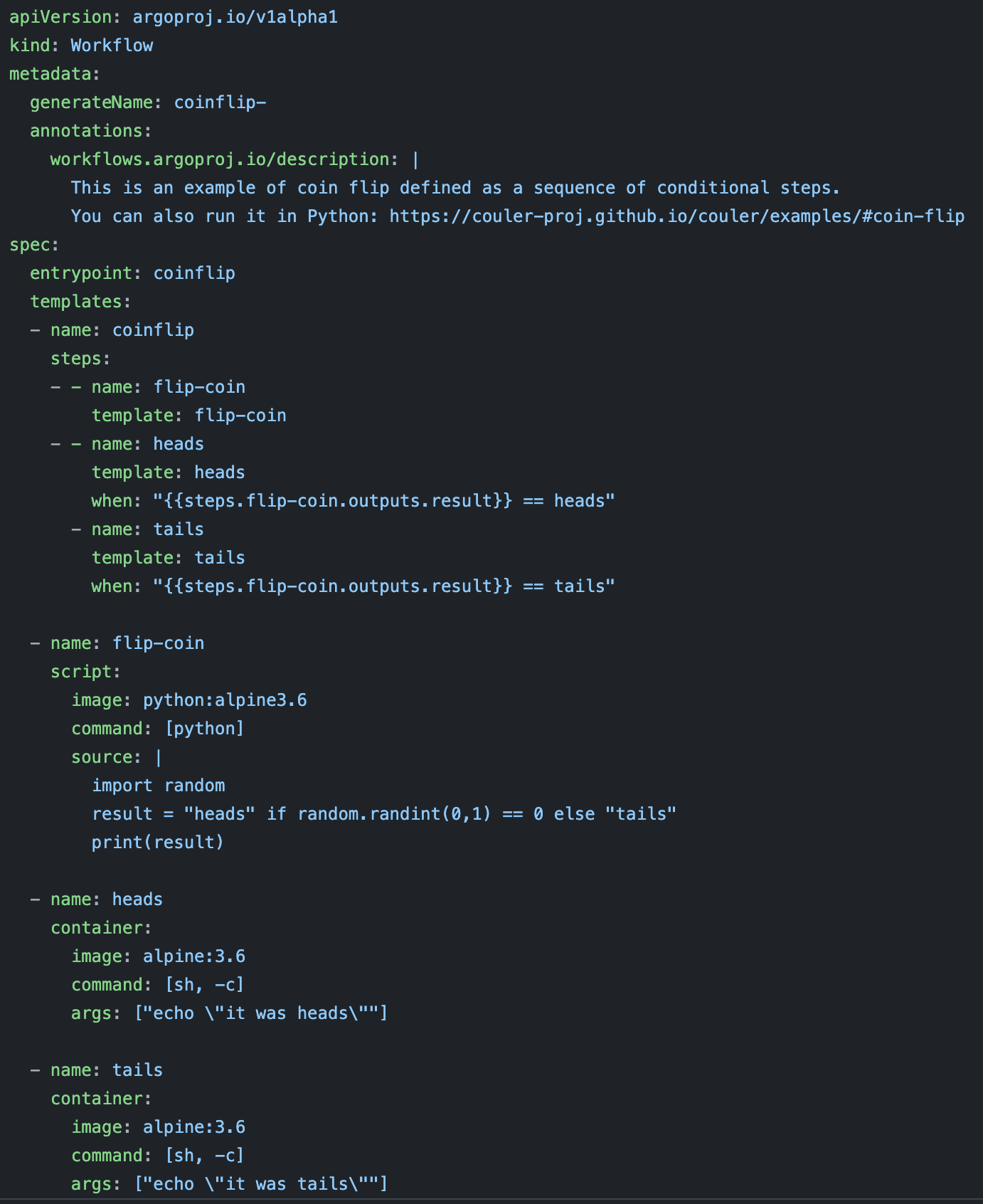
这是 Argo 中一个掷硬币的工作流。可以想象一下,如果你做的事情远比这个有趣,那么这个文件会多么凌乱。本示例来自 Argo 存储库。
除了 YAML 文件比较乱之外,Argo 的主要缺点是它只能在 Kubernetes 集群上运行,而通常 Kubernetes 集群只在生产环境中提供。如果你想在本地测试同样的工作流,就必须使用 minikube 或 k3d。
基础设施抽象:Kubeflow vs. Metaflow
像 Kubeflow 和 Metaflow 这样的基础设施抽象工具,旨在将运行 Airflow 或 Argo 通常需要的基础设施模板代码抽象出来,帮助你在开发和生产环境中运行工作流。它们承诺让数据科学家可以从本地笔记本上访问生产环境的全部计算能力,实际上,这就让数据科学家可以在开发和生产环境中使用相同的代码。
尽管它们有一些工作流编排能力,但它们是要与真正的工作流编排器搭配使用的。事实上,Kubeflow 的其中一个组件 Kubeflow Pipelines 就是基于 Argo 构建的。
除了为你提供一致的开发和生产环境外,Kubeflow 和 Metaflow 还提供了其他一些不错的特性。
版本控制:自动生成工作流模型、数据和工件的快照。
依赖项管理:由于它们允许工作流的每个步骤都在自己的容器中运行,所以你可以控制每个步骤的依赖项。
可调试性:当一个步骤失败时,你可以从失败的步骤恢复工作流,而不是从头开始。
它们都是完全参数化的,而且是动态的。
目前,Kubeflow 更流行,因为它与 K8s 集群做了集成(同时,它是由谷歌创建的),而 Metaflow 只能用于 AWS 服务(Batch、Step Functions 等)。然而,它最近从 Netflix 剥离了出来,成了一家创业公司,所以我预计它很快就会发展到更多的用例。至少,原生的K8s集成正在进行中!
从用户体验的角度来看,我认为 Metaflow 更胜一筹。在 Kubeflow 中,虽然你可以用 Python 定义工作流,但你仍然需要写一个 Dockerfile 和一个 YAML 文件来指定每个组件的规格(如处理数据、训练、部署),然后才能将它们拼接到 Python 工作流中。因此,Kubeflow 帮助你抽离了其他工具的模板,你只需要编写 Kubeflow 模板就行了。
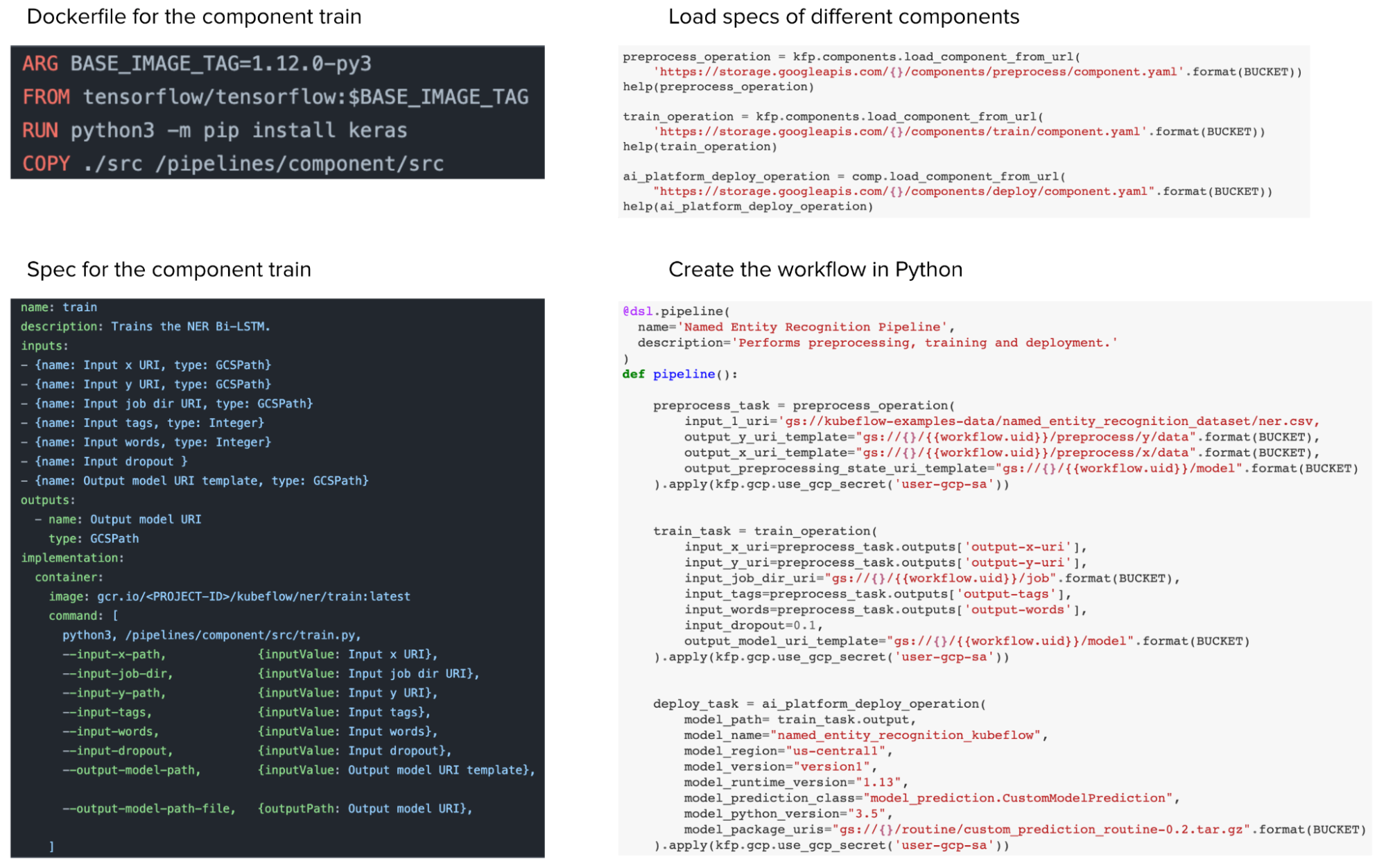
Kubeflow 工作流。尽管可以用 Python 创建 Kubeflow 工作流,但仍有许多配置文件需要编写。本示例来自 Kubeflow 存储库。
在 Metaflow 中,你可以使用 Python 装饰器@conda来指定每个步骤的需求——所需的库、内存和计算资源需求——Metaflow 将自动创建一个满足所有这些要求的容器来执行该步骤。你不用再编写 Dockerfiles 或 YAML 文件。
Metaflow 让你可以在同一个 notebook/脚本中实现开发和生产环境的无缝衔接。你可以在本机上运行小数据集实验,当你准备在云上运行大数据集实验时,只需添加@batch装饰器就可以在AWS Batch上执行。你甚至可以在不同的环境中运行同一工作流的不同步骤。例如,如果一个步骤需要的内存较小,就可以在本地机器上运行。但如果下一步需要的内存较大,就可以直接添加@batch在云端执行。
# 示例:一个组合使用了两种模型的推荐系统的框架# A模型在本地机器上运行,B模型在AWS上运行class RecSysFlow(FlowSpec): @step def start(self): self.data = load_data() self.next(self.fitA, self.fitB) # fitA requires a different version of NumPy compared to fitB @conda(libraries={"scikit-learn":"0.21.1", "numpy":"1.13.0"}) @step def fitA(self): self.model = fit(self.data, model="A") self.next(self.ensemble) @conda(libraries={"numpy":"0.9.8"}) # Requires 2 GPU of 16GB memory @batch(gpu=2, memory=16000) @step def fitB(self): self.model = fit(self.data, model="B") self.next(self.ensemble) @step def ensemble(self, inputs): self.outputs = ( (inputs.fitA.model.predict(self.data) + inputs.fitB.model.predict(self.data)) / 2 for input in inputs ) self.next(self.end) def end(self): print(self.outputs)总结
这篇文章的长度和信息量都远远超出了我的预期。这有两个方面的原因,一是所有与工作流有关的工具都很复杂,而且很容易混淆,二是我自己无法找到一种更简单的方式来解释它们。
下面是本文的一些要点,希望对你有所启发。
开发环境和生产环境之间的差异,导致企业希望数据科学家能够掌握两套完整的工具:一套用于开发环境,一套用于生产环境。
数据科学项目端到端可以加速执行,并降低沟通开销。然而,只有当我们有好的工具来抽象底层基础设施,帮助数据科学家专注于实际的数据科学工作,而不是配置文件时,这才有意义。
基础设施抽象工具(Kubeflow、Metaflow)与工作流编排器(Airflow、Argo、Prefect)似乎很相似,因为它们都将工作流视为 DAG。然而,基础设施抽象的主要价值在于使数据科学家可以在本地和生产环境中使用相同的代码。基础设施抽象工具可以和工作流编排器搭配使用。
在使用它们之前,很多数据科学家都不知道他们需要这样的基础设施抽象工具。务必试一下(Kubeflow 比较复杂,但 Metaflow 只需 5 分钟就能上手)。
更新
Yuan Tang 是 Argo 的顶级贡献者,他对本文的评论如下:
Argo 是一个很大的项目,包括 Workflows、Events、CD、Rollouts 等。因此,在与其他工作流引擎比较时,使用子项目Argo Workflows更准确。
还有一些项目为 Argo Workflows 提供了更高层次的 Python 接口,这样数据科学家就不必使用 YAML 了。特别地,可以研究下使用 Argo Workflows 作为工作流引擎的Couler和 Kubeflow Pipelines。
人们还提到了其他一些很棒的工具,我在这里就不一一列举了,比如MLFlow或Flyte。我目前还在学习该领域的相关知识。非常感谢您的反馈。谢谢!
查看英文原文:





{kind=link}