
当前,大规模预训练模型已成为学术界和工业界都非常关注的一大研究领域。随着达摩院大模型 M6 突破 10 万亿参数,中国成功实现了全球最大 AI 预训练模型。
M6 成全球最大 AI 预训练模型
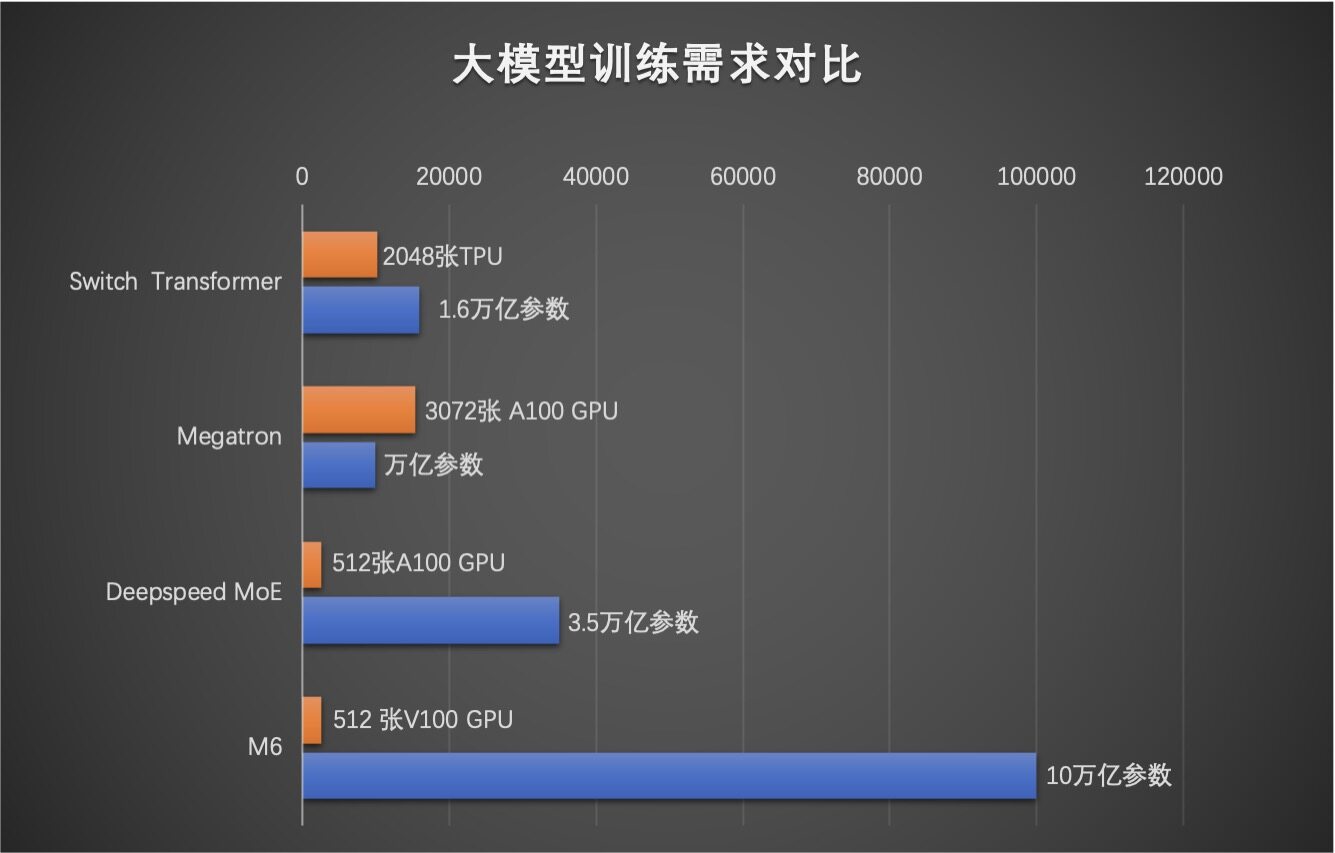
11 月 8 日,阿里巴巴达摩院公布多模态大模型M6最新进展,其参数已从万亿跃迁至 10 万亿,规模远超谷歌、微软此前发布的万亿级模型,成为全球最大的 AI 预训练模型。据了解,M6 使用 512 GPU 在 10 天内即训练出具有可用水平的 10 万亿模型。相比去年发布的大模型 GPT-3,M6 实现同等参数规模,能耗仅为其 1%。
M6 是达摩院研发的通用性人工智能大模型,拥有多模态、多任务能力,其认知和创造能力超越传统 AI,尤其擅长设计、写作、问答,在电商、制造业、文学艺术、科学研究等领域有广泛应用前景。
自 2020 年中 GPT-3 提出以来,一系列国内外大企业都在大模型的研发上开展探索,专注各个领域任务的大模型相继提出,在各大下游任务都展现出优越的表现。无疑,超大规模预训练模型蕴含着巨大的学术研究价值和商业落地价值。
与传统 AI 相比,大模型拥有成百上千倍“神经元”数量,且预先学习过海量知识,表现出像人类一样“举一反三”的学习能力。因此,大模型被普遍认为是未来的“基础模型”,将成下一代 AI 基础设施。然而,其算力成本相当高昂,训练 1750 亿参数语言大模型 GPT-3 所需能耗,相当于汽车行驶地月往返距离。
此前达摩院陆续发布了多个版本的 M6 模型,从大规模稠密模型到超大规模的混合专家模型的探索,逐步从百亿参数升级到万亿参数规模。
今年 5 月,通过专家并行策略及优化技术,达摩院 M6 团队将万亿模型能耗降低超八成、效率提升近 11 倍。10 月,M6 再次突破业界极限,通过更细粒度的 CPU offload、共享-解除算法等创新技术,让收敛效率进一步提升 7 倍,这使得模型规模扩大 10 倍的情况下,能耗未显著增加。这一系列突破极大降低了大模型研究门槛,让一台机器训练出一个千亿模型成为可能。
同时,达摩院联合阿里云推出了 M6 服务化平台,为大模型训练及应用提供完备工具,首次让大模型实现“开箱即用”,算法人员及普通用户均可方便地使用平台。达摩院还推出了当前最大规模的中文多模态评测数据集 MUGE,覆盖图文描述、文本生成图像、跨模态检索任务,填补了缺少中文多模态权威评测基准的空白。
作为国内首个商业化落地的多模态大模型,M6 已在超 40 个场景中应用,日调用量上亿。今年,大模型首次支持双 11。M6 在犀牛智造为品牌设计的服饰已在淘宝上线;凭借流畅的写作能力,M6 正为天猫虚拟主播创作剧本;依靠多模态理解能力,M6 正在增进淘宝、支付宝等平台的搜索及内容认知精度。

10 万亿 M6 技术实现
前文提到,M6 使用 512 GPU 在 10 天内即训练出具有可用水平的 10 万亿模型。而之前业界最好水平是微软最新发布的 DeepSpeed,其使用了 512 张 A100 才完成 3.5 万亿参数基于 MoE 的 GPT。
在研发的过程中,研究人员发现 MoE 模型结合高效的分组机制能够用有限资源快速训练完成一个效果优越的大模型。同时一系列大模型的工作都在说明,参数规模的扩展带来的便是模型能力边界的扩展,更多的数据+更大的模型=更强的能力。那么,如果要训练的是极限规模的十万亿参数模型,是不是就需要成倍地增加机器呢?
M6 团队提出的命题是,如何在有限资源的条件下高效地训练极限规模模型?
M6 团队提出了一种简单的方法解决此类极限规模模型训练的问题,不仅关注如何用有限的资源训练极限规模模型,还关注如何将其训练至真实可用。团队使用 512 张 GPU 将十万亿参数的模型训练至可用的水平,而如果训练此前的万亿参数模型也只需要 64 张 GPU 即可实现。相比此前的 M6 模型,M6-10T 具有如下优势:
相比此前的万亿参数 M6,M6-10T 的参数量是原先的 10 倍没有显著的资源增加(480 vs 512 GPU);
相比万亿参数 M6,M6-10T 在样本量的维度上具有更快的收敛速度;
提出的共享解除机制将十万亿参数模型的训练速度提升 7 倍以上,并可广泛应用于其他同类大模型的训练。
达摩院智能计算实验室联合阿里云 PAI 团队,在Whale框架下实现 M6 模型。此前发布的千亿和万亿参数 M6 模型,均在 Whale 上实现,利用其强大的数据并行、模型并行以及专家并行的能力实现超大规模模型的训练和推理。Whale 通过一系列优化,为 M6 模型的训练节约资源,提升效率。
显存优化方面,Whale 的自动 Gradient Checkpointing、Group-wise Apply、CPU Offload 技术和通信池化等技术均有效节约显存的使用,而在计算和通信方面,Whale 支持了 MoE 所需的 DP+EP 的机制,并在 EFLOPS 集群高速通信能力的基础上,采用分组融合通信、半精度通信、拓扑感知的 All2All 通信算子等技术来提高通信效率,以及结合混合精度、编译优化等技术提高训练效率等。同时,EFLOPS 团队联合 PAI 团队对 attention 进行优化,将访存密集型算子融合成一个 cuda kernel 实现,将 multihead attention 性能提升 30%。
而在十万亿 M6 模型的训练上,团队首先解决有限资源(512 GPU)“放下”10 万亿参数的极限规模模型,而模型结构则采用此前万亿参数 M6-T 使用的结合 expert prototyping 的 MoE 模型。团队在分布式框架 Whale 中利用 CPU offload 的方法成功将十万亿参数的 M6-10T 模型在 512 张 GPU 的机器中放下并实现训练。相比其他的 CPU offload 方案,M6 的 CPU offload 粒度可控,可以灵活地选择 offload 的模型层,可以不用将所有的权重 offload 到 CPU memory 中,而选择保留部分权重在 GPU memory 上进行计算,这样的做法可以进一步地提高 GPU 利用率。
解决了放入模型的问题后,团队针对训练效率的问题设计了 Pseudo-to-Real(共享解除)机制,其核心思想为利用训练好的小模型初始化大模型。该算法首先利用参数共享的机制构建并快速训练小模型,此阶段无需使用 CPU 内存存放模型同时可以使用更大的批次。配合上专家拆分和合并的机制,算法团队只需要使用 256 张 GPU 即可快速训练一个 Pseudo Giant。随后,训练好的模型层的参数用于为 Real Giant 的每一层提供初始化,大模型即可在训练好的小模型的基础上继续优化。尽管大模型的训练速度较慢,但无需经历漫长的收敛过程,只需从一个低点开始优化。
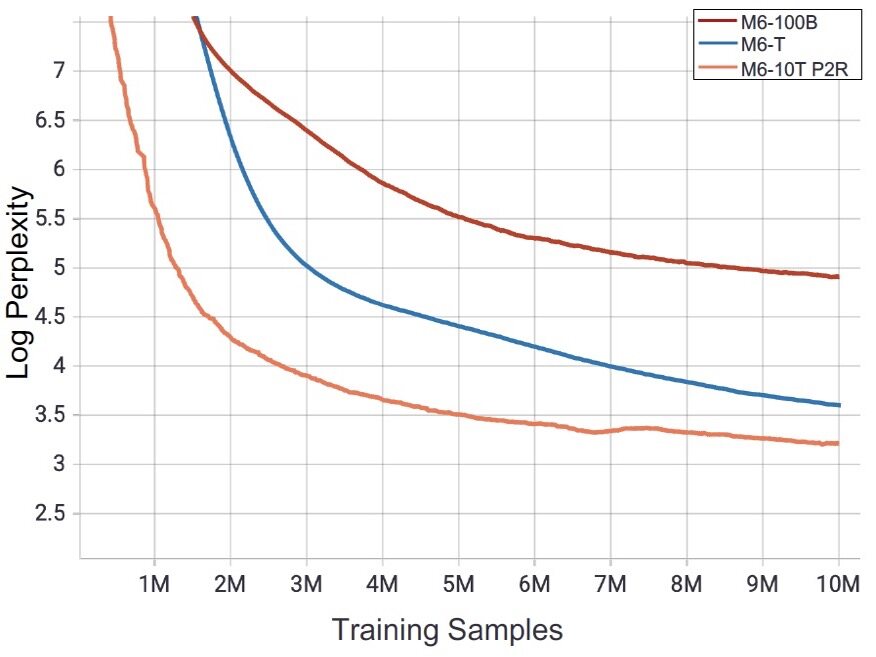
团队也通过实验证明该方案在收敛和下游迁移的有效性,同时在十万亿参数规模的 M6-10T 模型上做出成功实践,仅用 10 天左右的时间即得到非常突出的收敛效果。样本维度上收敛效果显著优于此前千亿参数 M6 和万亿参数模型 M6-T。如上图所示,在经过了 10M 样本的训练后,同等实验设置下 M6-10T 的 log PPL 显著低于 M6-MoE 和 M6-T,分别降低了 34.7%和 10.1%。
在实验中,对比不使用 Pseudo-to-Real 机制直接训练的十万亿模型,Pseudo-to-Real 机制达到相同预训练 loss 用时仅为原先的 6%。对比 M6 万亿模型,Pseudo-to-Real 十万亿模型达到相同预训练 loss 所需的样本量仅需约 40%,充分显示出 Pseudo-to-Real 机制对于超大模型训练的优势。
达摩院智能计算实验室负责人周靖人表示,“接下来,我们将深入研究大脑认知机理,致力于将 M6 的认知力提升至接近人类的水平,比如,通过模拟人类跨模态的知识抽取和理解方式,构建通用的人工智能算法底层框架;另一方面,不断增强 M6 在不同场景中的创造力,产生出色的应用价值。”




